一种声源定位方法及系统
本发明涉及声源定位技术领域,特别是涉及一种声源定位方法及系统。
背景技术:
随着科学技术的迅速发展,为目标定位技术带来更多的应用场景与技术要求。因此近些年来,声源定位在众多应用场景中已成为不可或缺的重要技术。比如,利用声源定位获取声源信息,可以使得视频会议中的麦克风自动跟踪说话人,获得更加精确的采集语音,实现语音增强;可以进一步提高智能机器人的声音定位能力、语音交互能力;可以用于监控系统,作为传统视频监控的有效补充技术,在视频监控效果不佳时发挥本身特有的优点,增强监控力度;还可广泛应用于可智能家居、家庭安防报警、家庭环境中危险检测等音频及信号处理领域中。但是,目前声源定位精度往往不尽人意。
技术实现要素:
本发明的目的是提供一种声源定位方法及系统,以提高声源定位精准度。
为实现上述目的,本发明提供了如下方案:
一种声源定位方法,所述声源定位方法包括:
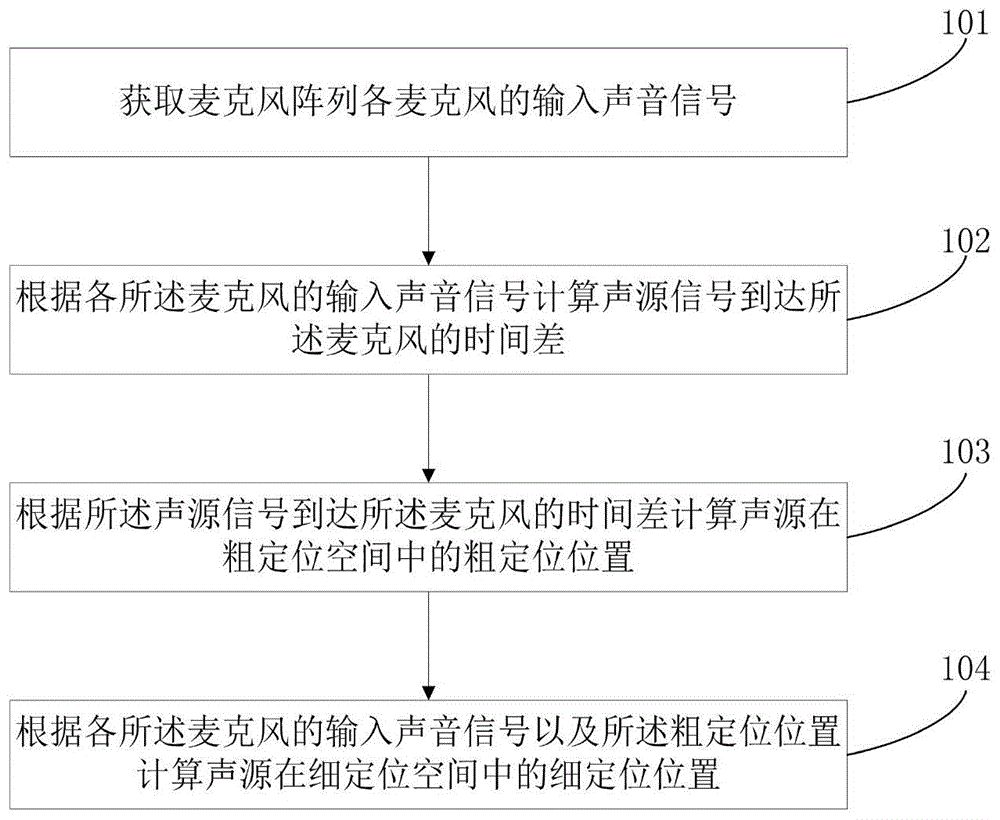
获取麦克风阵列各麦克风的输入声音信号;
根据各所述麦克风的输入声音信号计算声源信号到达所述麦克风的时间差;
根据所述声源信号到达所述麦克风的时间差计算声源在粗定位空间中的粗定位位置;
根据各所述麦克风的输入声音信号以及所述粗定位位置计算声源在细定位空间中的细定位位置;所述粗定位空间以及所述细定位空间均为以所述麦克风阵列为球心,由多个离散点组成的球形空间,所述离散点为所述球形空间的顶点,所述粗定位空间中离散点的数量小于所述细定位空间中离散点的数量。
可选地,所述麦克风阵列为四个心型指向性麦克风组成的环形麦克风阵列。
可选地,所述时间差的计算过程包括:
将每两个所述麦克风的输入声音信号表示为互相关函数;
使用广义互相关的方法将所述互相关函数表示为广义互相关函数;
使用scot与phat联合加权的方法对所述广义互相关函数中的加权函数进行修正,得到修正后的广义互相关函数;
根据所述修正后的广义互相关函数计算所述时间差。
可选地,所述粗定位位置的计算过程包括:
根据所述球形空间的环境参数对声速进行修正,得到修正后的声速;
根据所述修正后的声速以及所述时间差计算所述粗定位位置。
可选地,所述根据所述修正后的声速以及所述时间差计算所述粗定位位置具体包括:
根据所述修正后的声速以及所述时间差计算声源初始位置;
获取所述粗定位空间中距离所述声源初始位置最近的离散点,得到所述粗定位位置。
可选地,所述细定位位置的计算过程包括:
获取所述细定位空间中到所述粗定位位置的距离在预设范围内的多个离散点;
根据各所述麦克风的输入声音信号计算所述细定位空间中到所述粗定位位置的距离在预设范围内的各离散点的可控波束响应;
获取可控波束响应最大值对应的离散点,得到细定位位置。
可选地,所述可控波束响应计算公式为:
其中,p(θ)为可控波束响应,m为麦克风的数量,m为第m个麦克风,n为第n个麦克风,ψm,n(w)为可控波束响应中的加权函数,
可选地,所述粗定位空间以及所述细定位空间均由三角形网络构成,所述离散点为所述三角形网路的顶点;所述粗定位空间中离散点的数量为:
k1=10×4u+2
所述细定位空间中离散点的数量为:
k2=10×4v+2
其中,k1为粗定位空间中离散点的数量,k2为细定位空间中离散点的数量,u和v均为自然数,u<v。
一种声源定位系统,所述声源定位系统包括:
获取模块,用于获取麦克风阵列各麦克风的输入声音信号;
第一计算模块,用于根据各所述麦克风的输入声音信号计算声源信号到达所述麦克风的时间差;
第二计算模块,用于根据所述声源信号到达所述麦克风的时间差计算声源在粗定位空间中的粗定位位置;
第三计算模块,用于根据各所述麦克风的输入声音信号以及所述粗定位位置计算声源在细定位空间中的细定位位置;所述粗定位空间以及所述细定位空间均为以所述麦克风阵列为球心,由多个离散点组成的球形空间,所述离散点为所述球形空间的顶点,所述粗定位空间中离散点的数量小于所述细定位空间中离散点的数量。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明公开了一种声源定位方法及系统,方法包括:获取麦克风阵列各麦克风的输入声音信号;根据各所述麦克风的输入声音信号计算声源信号到达所述麦克风的时间差;根据所述声源信号到达所述麦克风的时间差计算声源在粗定位空间中的粗定位位置;根据各所述麦克风的输入声音信号以及所述粗定位位置计算声源在细定位空间中的细定位位置;所述粗定位空间以及所述细定位空间均为以所述麦克风阵列为球心,由多个离散点组成的球形空间,所述离散点为所述球形空间的顶点,所述粗定位空间中离散点的数量小于所述细定位空间中离散点的数量。本发明使用粗定位空间快速搜索到声源所在区域后,再利用细定位空间搜索得到声源的精确位置,声源定位精度极高。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的声源定位方法流程图;
图2为本发明提供的球形示意图一;
图3为本发明提供的球形示意图二;
图4为本发明提供的球形示意图三。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种声源定位方法及系统,以提高声源定位精准度
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图所示,声源定位方法包括:
步骤101:获取麦克风阵列各麦克风的输入声音信号。
其中,麦克风阵列为四个心型指向性麦克风组成的环形麦克风阵列。环形麦克风半径为4.5cm。心型指向性麦克风在接收来自于前方和两侧声音信号时,可以减小后方声音信号的增益。通过心型指向性麦克风组成的环形麦克风阵列获得输入声音信号时,可以有效获得扫描方向的输入声音信号,降低非扫描方向的输入声音信号。
步骤102:根据各麦克风的输入声音信号计算声源信号到达麦克风的时间差。
使用tdoa(到达时间差,timedifferenceofarrival)算法中的广义互相关(gcc,generalizedcross-correlation)算法计算声源信号到达麦克风的时间差。具体包括:
将每两个麦克风的输入声音信号表示为互相关函数。
使用广义互相关的方法将互相关函数表示为广义互相关函数。
使用scot与phat联合加权的方法对广义互相关函数中的加权函数进行修正,得到修正后的广义互相关函数。
根据修正后的广义互相关函数计算所述时间差。
时间差计算原理如下:
麦克风阵列中每对麦克风的输入声音信号可表示为:
x1(t)=h1(t)*s1(t)+n1(t)
x2(t)=h2(t)*s1(t-τ12)+n2(t)
其中,x1(t)为第一个麦克风的输入声音信号,x2(t)为第二个麦克风的输入声音信号,h1(t)为第一个麦克风对应的声源的冲激响应,h2(t)为第二个麦克风对应的声源的冲激响应,n1(t)为第一个麦克风的噪声信号,n2(t)为第二个麦克风的噪声信号,s1(t)为声源信号,s1(t-τ12)为声源信号s1(t)时延τ12后的信号,t为时间,τ12为声源信号到达第一个麦克风与第二个麦克风的时间差。
将输入声音信号x1(t)与x2(t)使用互相关函数表示:
其中,
根据维纳-辛钦定理,互相关函数与其互功率谱密度互为傅里叶变换对,因此上述互相关函数又可以表示为:
其中,
为克服由于存在混响和噪声的影响导致
其中,
广义互相关函数
步骤103:根据声源信号到达麦克风的时间差计算声源在粗定位空间中的粗定位位置。
首先进行空间划分,形成一个以麦克风阵列为球心,由多个离散点组成的球形空间,离散点为球形空间的顶点。粗定位空间以及细定位空间均由三角形网络构成,离散点为三角形网路的顶点。粗定位空间中离散点的数量为:k1=10×4u+2,细定位空间中离散点的数量为:k2=10×4v+2。其中,k1为粗定位空间中离散点的数量,k2为细定位空间中离散点的数量,u和v均为自然数,u<v。u等于0时,此时的球形空间可视为初始空间,是由12个离散点组成的正凸二十面体,拥有20个三角形网络,初始球形空间如图2所示。u等于1或v等于1时,此时的球形空间可视为一次递归细分后的空间,由42个离散点组成,拥有80个三角形网路,一次递归细分后的空间如图3所示。u等于4或v等于1时,此时的球形空间可视为四次递归细分后的空间,由2562个离散点组成,拥有5120个三角形网路,四次递归细分后的空间如图4所示。
然后计算粗定位位置:
根据球形空间的环境参数对声速进行修正,得到修正后的声速。声速修正公式为:
其中,t为球形空间中的温度,pw为球形空间中空气的分压强,pw=pa×rh,pa为水的饱和蒸汽压,rh为球形空间中的相对湿度,p为球形空间中的大气压强。对声速进行修正,可以优化声源定位精度。
根据修正后的声速以及时间差计算粗定位位置。其中,根据修正后的声速以及时间差计算粗定位位置包括:
根据修正后的声速以及时间差计算声源初始位置。声源初始位置计算公式如下:
τ12为声源信号到达第一个麦克风与第二个麦克风的时间差,τ13为声源信号到达第一个麦克风与第三个麦克风的时间差,τ14为声源信号到达第一个麦克风与第四个麦克风的时间差,c为修正后的声速,mi(i=1,2,3,4)为声源到第i个麦克风的距离。
(xi,yi,zi)为球形空间中麦克风的坐标,(xs,ys,zs)为解算出的位置,即声源初始位置。
获取粗定位空间中距离声源初始位置最近的离散点,得到粗定位位置。
步骤104:根据各麦克风的输入声音信号以及粗定位位置计算声源在细定位空间中的细定位位置。其中,细定位位置的计算过程包括:
获取细定位空间中到粗定位位置的距离在预设范围内的多个离散点。
根据各麦克风的输入声音信号计算细定位空间中到粗定位位置的距离在预设范围内的各离散点的可控波束响应。
获取可控波束响应最大值对应的离散点,得到细定位位置。
细定位位置计算原理如下:
将粗定位位置(x,y,z)映射到粗定位空间中,映射方法为:
其中,β为粗定位位置在声源水平方向上的方位角,
利用srp-phat算法计算出声源的精确位置,其精确位置可由细定位空间中某一离散点的俯仰角α″和水平方位角β″表示。
使用求取可控波束响应(srp)最大值的方法获得俯仰角θ′和水平方位角α′,可控波束响应(srp)可以使用滤波求和(fs)的输出功率表示,其中滤波求和(fs)函数可表示为:
其中,m为麦克风的数量,gm(w)为滤波器的表达式,xm(w)为第m个麦克风输入声音信号的傅里叶变换,τm(θ)为为第m个麦克风与相对参考麦克风的水平方位角或垂直俯仰角为θ时声源信号到达第m个麦克风与相对参考麦克风的时间差。
可控波束响应(srp)可表示为:
将滤波求和(fs)函数代入得到:
其中,p(θ)为可控波束响应,m为麦克风的数量,m为第m个麦克风,n为第n个麦克风,ψm,n(w)为可控波束响应中的加权函数,也使用scot与phat联合加权的方法进行修正,
计算粗定位位置在细定位空间中距离最近的5个离散点的水平方位角的可控波束响应,最大值即为声源水平方向上的方位角,可表示为:
其中,p(β′)为水平方向上的方位角为β′时的可控波束响应。
再计算离散点的俯仰角的可控波束响应,最大值即为声源垂直方向上的俯仰角,可表示为:
其中,p(α′)为垂直方向上的俯仰角为α′时的可控波束响应。
声源的细定位位置也就是精确位置由细定位空间中某一离散点的俯仰角α″和水平方位角β″表示。
本实施例还公开了一种声源定位系统,声源定位系统包括:
获取模块,用于获取麦克风阵列各麦克风的输入声音信号。
第一计算模块,用于根据各麦克风的输入声音信号计算声源信号到达麦克风的时间差。
第二计算模块,用于根据声源信号到达麦克风的时间差计算声源在粗定位空间中的粗定位位置。
第三计算模块,用于根据各麦克风的输入声音信号以及粗定位位置计算声源在细定位空间中的细定位位置。粗定位空间以及细定位空间均为以麦克风阵列为球心,由多个离散点组成的球形空间,离散点为球形空间的顶点,粗定位空间中离散点的数量小于细定位空间中离散点的数量。
本发明使用指向性麦克风获取输入声音信号,麦克风具有对声源方向的选择性,减少了进行声源定位时所需要扫描的空间和麦克风对数,降低了计算量,提高了声源定位的实时性。
本发明采用了分级搜索定位的方法,使用粗细两种定位方式,将声源定位空间划分为粗定位空间和细定位空间。首先使用计算量小、定位快速的定位算法进行粗定位以获取声源在粗定位空间的大体位置,再使用精确度高,计算量大的定位算法进行精确定位,使得本发明在保证定位实时性的情况下,具有极高的声源定位精度。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!