一种面向电磁大数据的未知雷达辐射源智能识别方法与流程
1.本发明涉及雷达信号处理技术领域,尤其是涉及一种面向电磁大数据的未知雷达辐射源智能识别方法。
背景技术:
2.雷达辐射源识别(radar emitter recognition,rer)是雷达对抗侦察中的关键环节,它是在分选的基础上提取雷达辐射源信号中的特征参数和工作参数,在这些参数的基础上可获取该目标辐射源的体制、用途、型号、载体平台等信息,进而能够对战场态势、威胁等级、活动规律和战术意图等进行推理,为己方决策提供重要情报支持。
3.目前,在雷达辐射源识别领域中,人工智能的相关理论方法已经得到了广泛的应用,且能够取得很好的效果,但随着电子信息技术的发展,将会出现越来越多的未知辐射源,其特征分布与类别都是未知的,在缺少先验知识的情况下,难以对人工智能模型进行充分的训练,因而使得现有的大多数方法都无法很好地完成对未知雷达辐射源的识别。故未知雷达辐射源识别问题是目前雷达辐射源识别领域最困难、也是最急需解决的问题。
4.针对未知雷达辐射源识别的问题,研究者们主要采用了迁移学习、在线学习等方法来应对。陆鑫伟等深入研究了领域匹配迁移学习理论,设计了基于迁移成分分析改进的神经网络分类器,通过迁移不同领域的数据辅助训练分类器,减小了系统的识别误差。李蒙等将迁移学习理论引入识别系统,提出一种基于迁移成分分析的雷达辐射源识别方法,通过设置统一的核函数将不同样本集映射到同一隐藏空间,在隐藏空间对支持向量机进行训练并对测试样本进行识别。田昊等为了满足雷达辐射源识别系统实时处理数据的需求,研究了多种在线学习算法。
5.但上述解决方案都属于是对传统的机器学习范式进行修正,能够取得一定的效果,但没有从本质上直接解决未知雷达辐射源识别这个问题。
6.本发明针对传统机器学习范式的不足,企图依靠海量的数据以及大数据计算集群强大的算力将分类问题转变为检索问题,来解决复杂电磁环境下未知雷达辐射源识别的问题。
技术实现要素:
7.为解决上述问题,本发明的目的是提供一种面向电磁大数据的未知雷达辐射源智能识别方法,其以“检索”代替“分类”来完成未知雷达辐射源的识别任务。
8.为实现上述发明目的,本发明采用如下技术方案:
9.一种面向电磁大数据的未知雷达辐射源智能识别方法,其包括以下步骤:
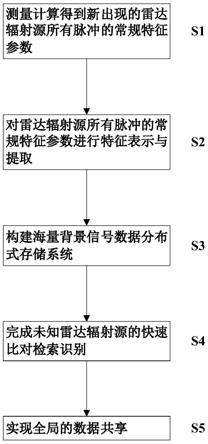
10.s1、测量计算得到新出现的雷达辐射源所有脉冲的常规特征参数;
11.s2、对雷达辐射源所有脉冲的常规特征参数进行特征表示与提取;
12.s3、构建海量背景信号数据分布式存储系统;
13.s4、完成未知雷达辐射源的快速比对检索识别,操作方法为:
14.步骤4.1、为了能够准确地计算雷达辐射源之间的相似度,同时捕捉辐射源信号内的波动变化特性,采用一种基于互信息的雷达辐射源相似度计算方法,使用信息论中的互信息来代替传统的欧式距离对雷达辐射源之间的相似度进行计算,针对两个n维的雷达辐射源信号深层特征向量x=(x1,x2,
…
,x
n
)和y=(y1,y2,
…
,y
n
),计算得到两个辐射源之间的相似度xsd(x,y);
15.步骤4.2、通过将互信息mi与k最近邻knn算法相结合,提出mi
‑
knn算法实现未知雷达辐射源的检索识别,同时能够进行辐射源威胁等级的判定;已知海量辐射源信号深层特征数据集k=(k0,k1,
…
,k
m
)及其对应的威胁等级标签t=(t0,t1,
…
,t
m
),针对一个未知的待分类的辐射源信号深层特征数据x,能够得到x的具体类别及其威胁等级t
′
;
16.步骤4.3、对mi
‑
knn算法进行并行化,使用基于flink的未知雷达辐射源快速比对检索识别算法完成未知雷达辐射源的识别;
17.s5、实现全局的数据共享。
18.进一步地,上述的步骤s1,具体操作方法为:
19.步骤1.1、使用超外差侦察接收机接收雷达辐射源信号;
20.步骤1.2、对雷达辐射源信号进行参数测量与分选;
21.步骤1.3、得到新出现的雷达辐射源所有脉冲的脉冲载频cf、脉冲宽度pw、脉冲重复间隔pri、脉冲幅度pa、脉冲的到达角aoa。
22.进一步地,上述的步骤s2,具体操作方法为:
23.步骤2.1、在所有侦察接收机上加装边缘计算终端,该边缘计算终端主要包含一个嵌入式gpu;
24.步骤2.2、在服务器中的历史采集数据上训练一个无监督的深度学习模型autoencoder,并将已训练好的模型部署至上述嵌入式gpu上;
25.步骤2.3、所述深度学习模型autoencoder接收新出现的雷达辐射源所有脉冲的常规特征参数作为输入,进行特征表示与提取,输出辐射源信号的深层特征,即一个高维实值特征向量,该向量代表着一个辐射源与信道环境无关的核心特征,用于辐射源的检索。
26.进一步地,上述的步骤s3,具体操作方法为:
27.步骤3.1、通过flume消息传递中间件,将所有边缘计算终端的计算结果,即未知雷达辐射源信号深层特征数据,作为消息进行收集;
28.步骤3.2、再由kafka消息处理中间件将深层特征数据传输至基于flink的大数据计算集群中;
29.步骤3.3、将所有深层特征数据及其属性信息在基于hbase的分布式存储系统中进行数据持久化。
30.进一步地,上述的步骤s4中,步骤4.1中的基于互信息的雷达辐射源相似度计算方法,步骤为:
31.步骤4.1.1、针对两个n维的雷达辐射源信号深层特征向量x=(x1,x2,
…
,x
n
)和y=(y1,y2,
…
,y
n
),求两个深层特征向量x和y之间的互信息值i(x;y);
[0032][0033]
其中,p(x
i
)为x的概率密度函数,p(y
j
)为y的概率密度函数;
[0034]
步骤4.1.2、求互信息值i(x;y)的对称不确定性值;
[0035][0036]
其中,p(x
i
)为x的概率密度函数,p(y
j
)为y的概率密度函数;
[0037]
步骤4.1.3、计算得到两个辐射源之间的相似度xsd(x,y);
[0038]
xsd(x;y)=1
‑
su(x;y)。
[0039]
进一步地,上述的步骤s4中,步骤4.2中的mi
‑
knn算法实现未知雷达辐射源的检索识别,同时能够进行辐射源威胁等级的判定,步骤为:
[0040]
步骤4.2.1、计算待分类的辐射源信号深层特征数据x与数据集k中所有样本数据的对称不确定性——相似度;
[0041]
步骤4.2.2、按照计算得到的相似度对所有样本进行排序,若存在超过设定的相似度阈值的样本,即完成未知雷达辐射源的检索识别;若所有样本都未超过设定的相似度阈值,则直接将x加入深层特征数据集k中;
[0042]
步骤4.2.3、完成检索识别后,取出与x最相似的k个样本,计算k个样本的威胁等级比例,所占比例最高的威胁等级即作为x的威胁等级判定结果。
[0043]
进一步地,上述的步骤s4中,步骤4.3中的整个并行化策略分为三个阶段:首先对深层特征数据集进行分割,然后对相似度计算过程进行并行化,最后对计算结果进行聚合。
[0044]
更进一步地,上述的步骤4.3中,具体步骤为:
[0045]
步骤4.3.1、深层特征数据集被分为若干子集,作为后续并行化计算的数据源;
[0046]
步骤4.3.2、并行化策略是在使用hdfs对数据集进行自定义分区后,对mi
‑
knn算法中的相似度计算进行任务并行化以实现加速;flink计算架构的任务并行化采用了主从模型,jobmanager和taskmanager分别为主节点和从节点;jobmanager的主要任务为数据的划分与分配,即完成数据集的分割,并把分割结果广播至所有taskmanager;taskmanager的主要任务为并行化计算与反馈,即计算待分类的辐射源信号深层特征数据与其他样本之间的相似度,并把计算结果反馈至jobmanager;
[0047]
步骤4.3.3、在分割后的所有数据子集上,将并行化计算得到的与每个样本相似度以key值作为索引进行聚合,选取超过设定的相似度阈值的样本,作为最终的检索识别结果。
[0048]
再进一步地,上述的步骤4.3.1中,深层特征数据集被分为若干子集,具体的分割步骤如下:
[0049]
步骤4a、利用数据集分区的方法把深层特征数据集k分割为p个部分,每个部分分配至一个处理器processor;
[0050]
步骤4b、主节点将mi
‑
knn算法中所选择的k值和相似度阈值广播至各个处理器processor。
[0051]
进一步地,上述的步骤s5,具体操作方法为:
[0052]
步骤5.1、将云存储服务器通过网线与大数据计算集群相连接;
[0053]
步骤5.2、将未知雷达辐射源识别结果信息定时上传至云存储服务器中。
[0054]
由于采用如上所述的技术方案,本发明具有如下优越性:
[0055]
未知雷达辐射源的特征分布与类别都是未知的,导致无法对其进行标注并构建可用的训练数据集,也就无法训练出传统的分类模型,常规的解决方案都属于是对传统的机器学习范式进行修正,能够取得一定的效果,但并未从本质上直接解决未知雷达辐射源识别这个问题。
[0056]
本发明面向电磁大数据的未知雷达辐射源智能识别方法,其从电磁大数据的角度出发,针对传统机器学习范式的不足,依靠海量的数据以及大数据计算集群强大的算力将分类问题转变为检索问题,来解决复杂电磁环境下未知雷达辐射源识别的问题。海量未标注的雷达辐射源信号特征数据能够直接存入大数据库中用于检索,当新出现一个辐射源信号时,若能够在大数据库中检索到,将该辐射源的信息合并入检索到的辐射源,从而得到其历次出现的时间、方位等属性信息,且能够进一步分析该辐射源的行为等特点。
附图说明
[0057]
图1是本发明面向电磁大数据的未知雷达辐射源智能识别方法的流程图;
[0058]
图2是本发明中的电磁大数据解决方案的流程图;
[0059]
图3是本发明中的相似度计算并行化原理图;
[0060]
图4是本发明中的knn与mi
‑
knn算法性能对比柱状示意图;
[0061]
图5是本发明中的mi
‑
knn并行化算法各阶段耗时统计占比示意图;
[0062]
图6是本发明中的不同并行度下t(source)阶段耗时柱状示意图;
[0063]
图7是本发明中的不同并行度下整个mi
‑
knn并行化算法耗时柱状示意图。
具体实施方式
[0064]
下面结合附图和实施例对本发明的技术方案作进一步详细说明。
[0065]
如图1、2所示,本发明的面向电磁大数据的未知雷达辐射源智能识别方法,其包括以下步骤:
[0066]
s1、测量计算得到新出现的雷达辐射源所有脉冲的常规特征参数,具体操作方法为:
[0067]
步骤1.1、使用超外差侦察接收机接收雷达辐射源信号;
[0068]
步骤1.2、对雷达辐射源信号进行参数测量与分选;
[0069]
步骤1.3、得到新出现的雷达辐射源所有脉冲的脉冲载频cf、脉冲宽度pw、脉冲重复间隔pri、脉冲幅度pa、脉冲的到达角aoa;
[0070]
s2、对雷达辐射源所有脉冲的常规特征参数进行特征表示与提取,具体操作方法
为:
[0071]
步骤2.1、在所有侦察接收机上加装边缘计算终端,该边缘计算终端主要包含一个嵌入式gpu,cuda核心大于256个;
[0072]
步骤2.2、在服务器中的历史采集数据上训练一个无监督的深度学习模型autoencoder,并将已训练好的模型部署至上述嵌入式gpu上;
[0073]
步骤2.3、所述深度学习模型autoencoder接收新出现的雷达辐射源所有脉冲的常规特征参数作为输入,进行特征表示与提取,输出辐射源信号的深层特征,即一个高维实值特征向量,该向量代表着一个辐射源与信道环境无关的核心特征,用于辐射源的检索;
[0074]
s3、构建海量背景信号数据分布式存储系统,具体操作方法为:
[0075]
步骤3.1、通过flume消息传递中间件,将所有边缘计算终端的计算结果,即未知雷达辐射源信号深层特征数据,作为消息进行收集;
[0076]
步骤3.2、再由kafka消息处理中间件将深层特征数据传输至基于flink的大数据计算集群中;
[0077]
步骤3.3、将所有深层特征数据及其属性信息在基于hbase的分布式存储系统中进行数据持久化;
[0078]
s4、完成未知雷达辐射源的快速比对检索识别,操作方法为:
[0079]
步骤4.1、为了能够准确地计算雷达辐射源之间的相似度,同时捕捉辐射源信号内的波动变化特性,采用一种基于互信息的雷达辐射源相似度计算方法,使用信息论中的互信息来代替传统的欧式距离对雷达辐射源之间的相似度进行计算,针对两个n维的雷达辐射源信号深层特征向量x=(x1,x2,
…
,x
n
)和y=(y1,y2,
…
,y
n
),计算得到两个辐射源之间的相似度xsd(x,y);具体步骤为:
[0080]
步骤4.1.1、针对两个n维的雷达辐射源信号深层特征向量x=(x1,x2,
…
,x
n
)和y=(y1,y2,
…
,y
n
),求两个深层特征向量x和y之间的互信息值i(x;y);
[0081][0082]
其中,p(x
i
)为x的概率密度函数,p(y
j
)为y的概率密度函数;
[0083]
步骤4.1.2、求互信息值i(x;y)的对称不确定性值;
[0084][0085]
其中,p(x
i
)为x的概率密度函数,p(y
j
)为y的概率密度函数;
[0086]
步骤4.1.3、计算得到两个辐射源之间的相似度xsd(x,y);
[0087]
xsd(x;y)=1
‑
su(x;y);
[0088]
步骤4.2、通过将互信息(mi,mutual information)与k最近邻(k
‑
nearestneighbor,knn)算法相结合,提出mi
‑
knn算法实现未知雷达辐射源的检索识别,同
时能够进行辐射源威胁等级的判定;已知海量辐射源信号深层特征数据集k=(k0,k1,
…
,k
m
)及其对应的威胁等级标签t=(t0,t1,
…
,t
m
),针对一个未知的待分类的辐射源信号深层特征数据x,能够得到x的具体类别及其威胁等级t
′
,具体步骤为:
[0089]
步骤4.2.1、计算待分类的辐射源信号深层特征数据x与数据集k中所有样本数据的对称不确定性——相似度;
[0090]
步骤4.2.2、按照计算得到的相似度对所有样本进行排序,若存在超过设定的相似度阈值的样本,即完成未知雷达辐射源的检索识别;若所有样本都未超过设定的相似度阈值,则直接将x加入深层特征数据集k中;所述相似度阈值可以根据实际情况预先进行设定,所述相似度阈值通常设定为0.85~0.95;优选地,根据经验选取相似度阈值为0.9;
[0091]
步骤4.2.3、完成检索识别后,取出与x最相似的k个样本,计算k个样本的威胁等级比例,所占比例最高的威胁等级即作为x的威胁等级判定结果;
[0092]
步骤4.3、对mi
‑
knn算法进行并行化,使用基于flink的未知雷达辐射源快速比对检索识别算法完成未知雷达辐射源的识别;
[0093]
整个并行化策略分为三个阶段:首先对深层特征数据集进行分割,然后对相似度计算过程进行并行化,最后对计算结果进行聚合;具体步骤为:
[0094]
步骤4.3.1、深层特征数据集被分为若干子集,作为后续并行化计算的数据源;具体的分割步骤如下:
[0095]
步骤4a、利用数据集分区的方法把深层特征数据集k分割为p个部分,每个部分分配至一个处理器processor;
[0096]
步骤4b、主节点将mi
‑
knn算法中所选择的k值和相似度阈值广播至各个处理器processor;
[0097]
步骤4.3.2、并行化策略是在使用hdfs对数据集进行自定义分区后,对mi
‑
knn算法中的相似度计算进行任务并行化以实现加速,相似度计算并行化如图3所示;flink计算架构的任务并行化采用了主从模型,jobmanager和taskmanager分别为主节点和从节点;jobmanager的主要任务为数据的划分与分配,即完成数据集的分割,并把分割结果广播至所有taskmanager;taskmanager的主要任务为并行化计算与反馈,即计算待分类的辐射源信号深层特征数据与其他样本之间的相似度,并把计算结果反馈至jobmanager;
[0098]
步骤4.3.3、在分割后的所有数据子集上,将并行化计算得到的与每个样本相似度以key值作为索引进行聚合,选取超过设定的相似度阈值的样本,作为最终的检索识别结果;
[0099]
s5、实现全局的数据共享,具体操作方法为:
[0100]
步骤5.1、将云存储服务器通过网线与大数据计算集群相连接;
[0101]
步骤5.2、将未知雷达辐射源识别结果信息定时上传至云存储服务器中。
[0102]
实验搭建了由7台高性能工作站组成的flink大数据计算集群环境,其中1台作为主节点jobmanager,4台作为从节点taskmanager,1台作为kafka中间数据源获取节点,1台作为hdfs存储节点。flink计算集群的采用flink1.10.0版本,master节点和slave节点的内存均为16g。
[0103]
为了验证基于flink的未知雷达辐射源快速比对检索识别算法的性能,仿真生成了海量辐射源信号数据集,仿真参数设置如表1所示,150000个雷达辐射源模式,每个模式
就是一个脉冲组,即150000个脉冲组,通常40个~200个脉冲即代表辐射源的一种模式。脉冲组由每个脉冲的常规特征组成,而未知雷达辐射源脉冲信号的常规特征参数可能会发生迅速变化。
[0104]
表1海量辐射源信号数据集仿真参数设置
[0105][0106]
海量辐射源信号数据集经过深层网络处理后,即将每个辐射源信号通过特征表示与提取生成一个高维实值特征向量,从而得到海量辐射源信号深层特征数据集,用于评估本发明中的基于flink的未知雷达辐射源快速比对检索识别算法。
[0107]
实验在上述数据集中对knn与mi
‑
knn算法的性能进行了验证。结果如图4所示,相比于传统的knn算法,本发明中的mi
‑
knn算法针对未知雷达辐射源的识别准确率提升了3.1%,达到了87.2%。其主要原因为雷达脉冲之间不存在欧式空间结构关系,故传统knn算法中直接使用欧式距离来进行相似度计算会影响算法的整体性能,而本发明的基于互信息的雷达辐射源相似度计算方法能够很好地表示雷达脉冲之间的时序相关关系和信息交互关系。
[0108]
实验从并行化任务提交到任务完成过程中的各阶段来验证基于flink的mi
‑
knn并行化加速效果,设置了三组对比实验。基于flink的并行化任务具体分为4个阶段,其中获取数据的时间为t(source),相似度计算的时间为t(mi
‑
knn),taskmanager之间数据交换的时间为t(process),slot之间数据交换的时间为t(thread)。
[0109]
在海量辐射源信号深层特征数据集上,在并行度设置为10时,对mi
‑
knn并行化算法中t(source)、t(mi
‑
knn)、t(process)和t(thread)的耗时进行统计,实验结果如图5所示。
[0110]
由统计结果或知,在mi
‑
knn并行化算法执行过程中,t(source)阶段耗时占比为43%,由于整个并行化过程是分割后的所有数据子集上进行的,前期的数据分割、数据获取等操作会消耗大量的时间;t(mi
‑
knn)阶段耗时最多,占比为49%,该阶段为并行化算法运算执行的阶段,包括map和reduce等操作;t(process)和t(thread)耗时较少,占比分别为3%和5%。
[0111]
相比于传统的串行执行过程,由于大量分布式计算节点的使用,mi
‑
knn并行化算法的t(source)和t(mi
‑
knn)阶段耗时会显著降低,但分布式进程和线程之间大量的数据交换和通信会导致t(process)和t(thread)有一定程度的增加。综合考虑上述各因素,相比于串行执行过程,基于flink的mi
‑
knn并行化的整体耗时会有明显的下降。
[0112]
由于mi
‑
knn并行化算法执行过程中,t(source)阶段耗时占据了近一半,几乎接近了算法运算执行的耗时,明显具有很大的优化空间。因此,实验分别对并行度为2、4、6、8、10下的t(source)阶段耗时进行统计,实验结果如图6所示。
[0113]
由统计结果获知,当并行度设置为6时,t(source)阶段耗时最少,仅为2.0s,表明了该并行度为较合理的选择。并行度设置得过小或过大都会导致t(source)阶段耗时增加,当并行度设置为10时,t(source)阶段耗时最大,达到了2.8s。
[0114]
最终,在海量辐射源信号深层特征数据集上,对不同并行度下整个mi
‑
knn并行化算法耗时进行统计,实验结果如图7所示。
[0115]
由统计结果或知,随着并行度的不断增加,整个mi
‑
knn并行化算法耗时是先不断下降,后慢慢升高,其主要原因为当并行度设置得过小时,算法运算执行的耗时会显著增加,导致整体耗时很高;当并行度设置为6时,整个mi
‑
knn并行化算法耗时最少,仅为4.7s;当并行度设置得过大时,虽然算法运算执行的耗时会有所降低,但针对庞大数据集的数据分割、数据获取和数据交换等操作的耗时会增加,故也会使得整体耗时很高。因此,针对整个mi
‑
knn并行化算法,选取合适的并行度至关重要。
[0116]
以上所述仅为本发明的较佳实施例,而非对本发明的限制,在不脱离本发明的精神和范围的情况下,凡依本发明申请专利范围所作的均等变化与修饰,皆应属本发明的专利保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1