一种水质监测数据质量控制方法及系统与流程
1.本发明涉及水质监测领域,尤其涉及一种水质监测数据质量控制方法及系统。
背景技术:
2.当前,我国水质监测技术主要以理化监测技术为主,包括化学法、电化学法、原子吸收分光光度法、离子选择电极法等等。而基于多元高斯分布、基于聚类分析等的数据挖掘算法多用于互联网和统计学领域。当获取到大量水质各项指标的数据集后,用传统方法监测水质污染情况和异常数据工作量会非常大,我们将不限于上述统计学中的各类数据挖掘方法应用到水质异常数据监测中会大大减少工作量,上述两类数据挖掘算法及其混合算法在合理的误差范围内可以较好的监测水质异常数据,不过相比于传统的水质异常数据的监测,上述智能监测水质技术在工作量大大减少的同时对水质异常数据检测的精度会有所降低。
3.上述内容仅用于辅助理解本发明的技术方案,并不代表承认上述内容是现有技术。
技术实现要素:
4.为解决上述技术问题,本发明提供一种水质监测数据质量控制方法,包括:
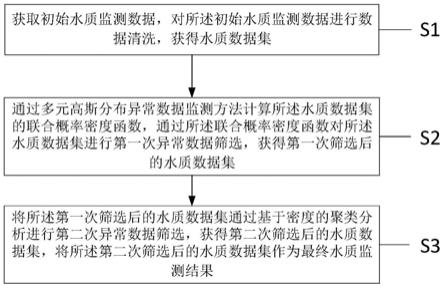
5.s1:获取初始水质监测数据,对所述初始水质监测数据进行数据清洗,获得水质数据集;
6.s2:通过多元高斯分布异常数据监测方法计算所述水质数据集的联合概率密度函数,通过所述联合概率密度函数对所述水质数据集进行第一次异常数据筛选,获得第一次筛选后的水质数据集;
7.s3:将所述第一次筛选后的水质数据集通过基于密度的聚类分析进行第二次异常数据筛选,获得第二次筛选后的水质数据集,将所述第二次筛选后的水质数据集作为最终水质监测结果。
8.优选的,步骤s1具体为:
9.剔除所述初始水质监测数据中的缺省值,获得所述水质数据集,所述水质数据集中各水质数据的维度均为n;
10.所述水质数据集中各水质数据的监测项包括:ph值,溶解氧,浊度,总磷,总氮,氨氮和cod。
11.优选的,步骤s2具体为:
12.s21:所述水质数据集t的表达式为:t={x
(1)
,x
(2)
,
…
,x
(m)
},其中,m表示水质数据集中水质数据的总数,对于各水质数据均满足:i表示水质数据的编号,x(i)表示第i号水质数据,n表示水质数据的维度;
13.s22:计算获得所述水质数据集的期望μ、标准差σ和协方差σ;
14.期望μ的计算公式如下:
[0015][0016]
标准差计算公式如下:
[0017][0018]
协方差σ的计算公式如下:
[0019][0020]
s23:所述联合概率密度函数的计算公式如下:
[0021][0022]
其中,x表示联合概率密度函数中的元素;
[0023]
s24:提取所述水质数据集中满足所述联合概率密度函数的水质数据,将三倍标准差σ以外的水质数据剔除,获得所述第一次筛选后的水质数据集。
[0024]
优选的,步骤s3具体为:
[0025]
s31:所述第一次筛选后的水质数据集的表达式为:t1={x
(1)
,x
(2)
,
…
,x
(k)
},其中,k表示第一次筛选后的水质数据集中水质数据的总数,对于各水质数据均满足:j表示水质数据的编号,x
(j)
表示第j号水质数据,n表示水质数据的维度;
[0026]
s32:给定各水质数据x
(j)
邻域半径内包含的其它水质数据的个数值n,计算获得各水质数据x
(j)
对应的最小邻域半径rj;
[0027]
水质数据x
(j)
的最小邻域半径rj采用欧式距离进行计算,计算公式如下:
[0028][0029]
其中,d表示水质数据x
(j)
邻域半径内包含的其它水质数据的编号;
[0030]
s33:计算各水质数据对应的最小邻域半径的期望μ1和标准差σ1;
[0031]
期望μ1的计算公式如下:
[0032][0033]
标准差σ1的计算公式如下:
[0034][0035]
s34:将最小邻域半径rj》μ1+3σ1和rj《μ
1-3σ1的水质数据作为异常数据剔除,获得所述第二次筛选后的水质数据集。
[0036]
一种水质监测数据质量控制系统,包括:
[0037]
水质数据集获取模块,用于获取初始水质监测数据,对所述初始水质监测数据进行数据清洗,获得水质数据集;
[0038]
第一次筛选模块,用于通过多元高斯分布异常数据监测方法计算所述水质数据集的联合概率密度函数,通过所述联合概率密度函数对所述水质数据集进行第一次异常数据筛选,获得第一次筛选后的水质数据集;
[0039]
第二次筛选模块,用于将所述第一次筛选后的水质数据集通过基于密度的聚类分析进行第二次异常数据筛选,获得第二次筛选后的水质数据集,将所述第二次筛选后的水质数据集作为最终水质监测结果。
[0040]
本发明具有以下有益效果:
[0041]
本发明提供的方法仅有邻域内的其它水质数据个数(n)一个人为设置的参数,可以很好的减少人为设置多个参数的难度和带来的误差,很好的实现了多元高斯分布异常数据监测方法和基于密度的聚类分析方法的并用;在减少传统异常数据监测工作量的同时,可以较好的挖掘出具有统计意义的水质异常数据,可有效增加水质监测数据质量控制的合理性。
附图说明
[0042]
图1为本发明实施例方法流程图;
[0043]
图2为本发明实施例系统结构图;
[0044]
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
[0045]
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0046]
参照图1,本发明提供一种水质监测数据质量控制方法,包括:
[0047]
s1:获取初始水质监测数据,对所述初始水质监测数据进行数据清洗,获得水质数据集;
[0048]
s2:通过多元高斯分布异常数据监测方法计算所述水质数据集的联合概率密度函数,通过所述联合概率密度函数对所述水质数据集进行第一次异常数据筛选,获得第一次筛选后的水质数据集;
[0049]
s3:将所述第一次筛选后的水质数据集通过基于密度的聚类分析进行第二次异常数据筛选,获得第二次筛选后的水质数据集,将所述第二次筛选后的水质数据集作为最终水质监测结果。
[0050]
本实施例中,步骤s1具体为:
[0051]
剔除所述初始水质监测数据中的缺省值,获得所述水质数据集,所述水质数据集中各水质数据的维度均为n;
[0052]
所述水质数据集中各水质数据的监测项包括:ph值,溶解氧,浊度,总磷,总氮,氨氮和cod等;
[0053]
具体的,每个维度对应一个监测项,例如维度1对应ph值的监测数据,维度2对应溶解氧监测数据,维度3对应浊度监测数据,维度4对应总磷监测数据,维度5对应总氮监测数
据,维度6对应氨氮监测数据,维度7对应cod监测数据;根据需要可以添加其他监测项。
[0054]
本实施例中,步骤s2的原理是基于多元高斯分布监测异常数据,因为水质数据在不同的污染情况下各项指标之间会存在一定的相关性,所以选择多元高斯分布来处理数据,这种方法可以自动找出各个维度之间的相关性;选取一定数量的水质数据作为训练集,拟合出参数μ和σ,然后计算出相应的联合概率密度函数p(x),最后对数据集中满足联合概率密度函数的水质数据采取3σ原则挖掘异常数据;
[0055]
步骤s2具体为:
[0056]
s21:所述水质数据集t的表达式为:t={x
(1)
,x
(2)
,
…
,x
(m)
},其中,m表示水质数据集中水质数据的总数,对于各水质数据均满足:i表示水质数据的编号,x(i)表示第i号水质数据,n表示水质数据的维度;
[0057]
s22:计算获得所述水质数据集的期望μ、标准差σ和协方差σ;
[0058]
期望μ的计算公式如下:
[0059][0060]
标准差计算公式如下:
[0061][0062]
协方差σ的计算公式如下:
[0063][0064]
s23:所述联合概率密度函数的计算公式如下:
[0065][0066]
其中,x表示联合概率密度函数中的元素;
[0067]
s24:提取所述水质数据集中满足所述联合概率密度函数的水质数据,将三倍标准差σ以外的水质数据剔除,获得所述第一次筛选后的水质数据集。
[0068]
本实施例中,步骤s3的原理是基于上述多元高斯分布方法挖掘得到的第一次筛选后的水质数据集,利用基于密度的聚类分析算法计算每个水质数据的最小领域半径,进而利用3σ原则筛选最小邻域半径异常值;上述的基于密度的聚类分析将位于高密度区域的水质数据视为正常数据,位于低密度区域的水质数据视为异常数据;
[0069]
步骤s3具体为:
[0070]
s31:所述第一次筛选后的水质数据集的表达式为:t1={x
(1)
,x
(2)
,
…
,x
(k)
},其中,k表示第一次筛选后的水质数据集中水质数据的总数,对于各水质数据均满足:j表示水质数据的编号,x
(j)
表示第j号水质数据,n表示水质数据的维度;
[0071]
s32:给定各水质数据x
(j)
邻域半径内包含的其它水质数据的个数值n,计算获得各水质数据x
(j)
对应的最小邻域半径rj;在最小邻域半径rj内的水质数据均符合一元高斯分
布;
[0072]
水质数据x
(j)
的最小邻域半径rj采用欧式距离进行计算,计算公式如下:
[0073][0074]
其中,d表示水质数据x
(j)
邻域半径内包含的其它水质数据的编号;
[0075]
s33:计算各水质数据对应的最小邻域半径的期望μ1和标准差σ1;
[0076]
期望μ1的计算公式如下:
[0077][0078]
标准差σ1的计算公式如下:
[0079][0080]
s34:将最小邻域半径rj》μ1+3σ1和rj《μ
1-3σ1的水质数据作为异常数据剔除,获得所述第二次筛选后的水质数据集;
[0081]
具体的,采取改进的3σ原则作为异常数据判断标准,当μ
1-3σ1≤rj≤μ1+3σ1时判断该水质数据位于高密度区域,视为正常数据;否则判断该水质数据位于低密度区域,视为异常数据,将这些异常数据剔除,即可获得具有统计意义的质量控制的水质数据集。
[0082]
与现有技术相比,本发明的优点是:本发明中基于密度的聚类分析算法是根据基于多元高斯分布检测算法的检测结果继续挖掘异常数据的,并且上述基于密度的聚类分析算法与标准的聚类算法不同,该算法只有一个人为设置的参数:邻域内的其它水质数据个数(n),可以很好的减少人为设置多个参数的难度和带来的误差,很好的实现了两种挖掘算法的并用;综上,本发明提供的一种水质监测数据质量控制方法在减少传统异常数据监测工作量的同时,可以较好的挖掘出水质异常数据,具有很好的统计意义。
[0083]
本发明提供一种水质监测数据质量控制系统,包括:
[0084]
水质数据集获取模块,用于获取初始水质监测数据,对所述初始水质监测数据进行数据清洗,获得水质数据集;
[0085]
第一次筛选模块,用于通过多元高斯分布异常数据监测方法计算所述水质数据集的联合概率密度函数,通过所述联合概率密度函数对所述水质数据集进行第一次异常数据筛选,获得第一次筛选后的水质数据集;
[0086]
第二次筛选模块,用于将所述第一次筛选后的水质数据集通过基于密度的聚类分析进行第二次异常数据筛选,获得第二次筛选后的水质数据集,将所述第二次筛选后的水质数据集作为最终水质监测结果。
[0087]
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者系统不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者系统所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括该
要素的过程、方法、物品或者系统中还存在另外的相同要素。
[0088]
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。词语第一、第二、以及第三等的使用不表示任何顺序,可将这些词语解释为标识。
[0089]
以上仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1