一种基于太赫兹光谱定性识别氨基酸混合物的方法与流程
:
1.本发明属于太赫兹光谱和成像技术领域,具体涉及一种基于太赫兹光谱定性识别氨基酸混合物的方法。
背景技术:
2.太赫兹波是一种波长介于红外线和微波之间的电磁波,由于处于光子学到电子学的过渡区域,其具有很多独特的属性,如指纹光谱性、低能性、特殊穿透性等。太赫兹波与性材料作用会产生独特的吸收谱-指纹谱。极性分子,如水分子,非极性分子,如二氧化碳分子,对太赫兹波的吸收有着非常明显的区别,因此太赫兹吸收谱对检验分子特性也有着重要价值。时域太赫兹光谱扫描技术利用高精度延时线将飞秒脉冲的采样时间延长至几十皮秒,并通过硬件预处理来降低噪声。由其产生的时域信号经傅里叶变换得到被检测物质的特征吸收谱,其谱宽可达5thz以上,动态范围可达70db以上。这种频谱性能可满足绝大多数化合物的检测需求,从而为太赫兹时域光谱扫描提供了大量的应用场景。
3.鉴于太赫兹吸收光谱的指纹特性,对于物质识别分类具有重要应用。目前许多方法可以定性或定量地识别混合物的光谱,比如偏最小二乘法(pls)、支持向量回归(svr)等,然而,这些方法侧重于一维太赫兹光谱,往往受到振动峰的加宽和重叠性质的影响,并且仅在某些诱导和低湿度下才可行,因此在实际环境中使用起来很麻烦。因此,本发明基于分量空间模式分析和卷积神经网络提出一种从吸收光谱库中识别混合物质成分的方法
技术实现要素:
4.为了解决上述问题,本发明旨在提供一种从吸收光谱库中识别混合物质成分的方法,首先通过分量空间模式分析csp分析得到每个采样点某种化合物出现的概率化学图,然后通过卷积神经网络识别csp分析的结果来确定混合物中是否存在特定成分。所提出的方法将使我们能够在单次测量中定性地检测未知混合物中的成分,并将用于现实生活中的生物分子检测。
5.为了实现上述目的,本发明涉及的一种基于太赫兹光谱定性识别氨基酸混合物的方法,具备包括以下步骤:
6.步骤1:采用透射式太赫兹时域系统对样品进行逐点扫描,得到氨基酸混合物样品采样点对应的太赫兹时域光谱数据;
7.步骤2:通过傅里叶变换将时域光谱数据转换成频谱数据,采用公式(1)-(2)计算吸收率,得到待测氨基酸混合样品采样点的吸收光谱图;
[0008][0009]
[0010]
式中,n(ω)表示折射率,ω是角频率,φ(ω)表示在样品中传播引起的相位改变,c是真空中的光速,d是样品厚度,α(ω)表示吸收率,ρ(ω)表示样品和参考信号的幅值比;
[0011]
步骤3:构建氨基酸混合物样品的太赫兹光谱数据矩阵fn×
l
,采用公式(4)计算得到矩阵pm×
l
,即氨基酸混合物样品的化学图;
[0012]
[pm×
l
]=([sn×m]
t
[sn×m])-1
[sn×m]
t
[
fn
×
l], (4)
[0013]
式中,l表示氨基酸混合物样品上的像素点,即采样点(事先将样品上的采样点的二维坐标转变为一维坐标,与l对应),n表示每一个像素点对应的n个太赫兹光谱数据频率分量,即fn×
l
为氨基酸混合物样品中l个采样点的太赫兹吸收光谱的n个频率分量组成的矩阵,sn×m表示已知的m种氨基酸的太赫兹光谱矩阵,每种氨基酸的太赫兹吸收光谱数据都有n个频率分量,即sn×m为已知的m种氨基酸的太赫兹吸收光谱的n个频率分量组成的矩阵,pm×
l
表示每个像素点出现某种氨基酸的概率,也被描述为化学图;
[0014]
步骤4:采用公式(5)对pm×
l
中的每一个数据自适应阈值去除背景,高于该阈值像素值设置为1,否则为0,得到处理后的化学图;
[0015]
c1=min(p)+c0[max(p)-min(p)] (5)
[0016]
式中,c1表示阈值0;max(p)是矩阵pm×
l
中元素的最大值,min(p)是矩阵pm×
l
中元素的最小值;c0是[max(p)-min(p)]值范围的权重,设置为0.6;
[0017]
步骤5:基于lenet-5构建了一个卷积神经网络,对卷积神经网络进行训练;
[0018]
步骤6:将按照步骤1到4得到的待测氨基酸混合物样品的化学图输入到训练好卷积神经网络中,输出样品中含有的氨基酸种类。
[0019]
所述卷积神经网络包括依次相连的第一卷积-池化层、第二卷积-池化层、第一全连通层、第二全连通层和平面层,其中,6个卷积核组成第一卷积-池化层,16个卷积核组成的第二卷积-池化层,第一全连通层大小为120、第二全连通层的大小为大小为84,卷积滤波器的核大小为5,步进为1;两个全连通层将第二卷积-池化层的输出转换为平面层的线性输入,全连通层使用sigmoid激活函数进行二进分类,网络选择adam训练策略,并使用二元交叉熵损失函数计算预测结果和数据标记之间的距离,训练的最大迭代次数为50,并在精度停止增长10个迭代期之后,提前终止训练。
[0020]
本发明与现有技术相比具有以下有益效果:能够在室温和潮湿空气中从混合物中识别出不同成分的氨基酸,可达到100%的准确率。该方法克服了颗粒中高湿度和粒度分布不均等干旱条件的影响,具有在海关和机场等现实生活场景中定性检测生物分子的潜力。
附图说明:
[0021]
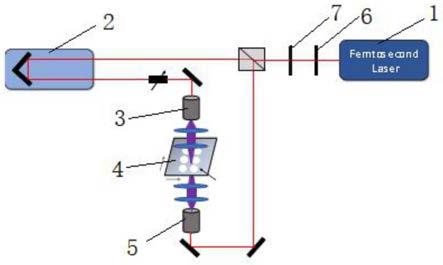
图1为本发明采用的透射式太赫兹时域系统的实验装置图。
[0022]
图2a为氨基酸混合物样品中某一个采样点的太赫兹时域光谱图。
[0023]
图2b为氨基酸混合物样品中某一个采样点的太赫兹频谱图。
[0024]
图2c为l亮氨酸的吸收光谱图。
[0025]
图2d为l酪氨酸的吸收光谱图。
[0026]
图2e为l亮氨酸和l酪氨酸1:1混合物的吸收光谱图。
[0027]
图3a为纯l亮氨酸的化学图。
[0028]
图3b为纯l酪氨酸的化学图。
[0029]
图3c为l亮氨酸、l酪氨酸和peek的1:1:1混合物的化学图。红点代表l酪氨酸,绿点代表l亮氨酸,黄点代表两者共存。
[0030]
图4a为6种氨基酸1:1二元混合物压片照片,从左上到右下依次为l亮氨酸和l缬氨酸、l亮氨酸和dl酪氨酸、l缬氨酸和dl酪氨酸、l亮氨酸和l酪氨酸、dl酪氨酸和l酪氨酸、l酪氨酸和l缬氨酸。
[0031]
图4b为对图4a中6个压片进行分量空间模式分析(csp分析)后识别的l亮氨酸的化学图。含l亮氨酸的压片所在区域明显亮于其他区域。
[0032]
图4c为对图4a中6个压片进行分量空间模式分析(csp分析)后识别的l酪氨酸的化学图。含l酪氨酸的压片所在区域明显亮于其他区域。
[0033]
图4d为dl-tyrosine(dl酪氨酸),l-leucine(l亮氨酸)、l-valine(l缬氨酸)、l-tyrosine(l酪氨酸)四种氨基酸的吸收光谱图。
[0034]
图5a为本发明涉及的卷积神经网络框架图。
[0035]
图5b为采用卷积神经网络进行训练的损失函数。
[0036]
图5c为采用卷积神经网络对l亮氨酸进行测试的准确度。
[0037]
图5d为采用卷积神经网络对l亮氨酸进行测试的精度。
[0038]
图5e为召回率随训练过程变化的曲线。
[0039]
图6a为l亮氨酸识别结果的分类混淆矩阵图。
[0040]
图6b为l酪氨酸识别结果的分类混淆矩阵图。
具体实施方式:
[0041]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0042]
实施例1:
[0043]
如图1所示,本实施例采用的透射式太赫兹时域系统包括飞秒激光器1、光延迟线2、发射器pca 3和样品台4和接收器pca 5。
[0044]
透射式太赫兹时域系统数据采集过程具体为:
[0045]
飞秒激光器1发出激光束,输入激光束的中心波长为1560nm,脉冲宽度约为100fs,重复率约为100mhz,功率约为80mw。在通过线性偏振器6和半波片7后,输入光束被平均分成泵浦光束和探测光束,分别用于太赫兹的产生和检测。探测光束经光学延迟线2(采样范围为120ps)平移,使激光脉冲由接收到的太赫兹脉冲的幅度调制,然后转换为模拟电信号,由计算机系统进行处理。来自发射器pca3的太赫兹光束由两个tpx透镜准直和聚焦,并由另外两个tpx透镜准直和聚焦到接收器pca5。透射式太赫兹时域系统的横向分辨率为30μm。样品放置在样品台4上并通过夹子固定,样品台4由计算机系统控制平移。thz波穿过样品,测量和收集样品的时域光谱数据。透射式太赫兹时域系统扫描的步长在水平和垂直轴上均为0.5mm。实验在25℃的温度和40%左右的湿度下进行。
[0046]
本实施例涉及的一种基于太赫兹光谱定性识别氨基酸混合物的方法,具备包括以下步骤:
[0047]
步骤1:将按照不同比例将dl酪氨酸、l亮氨酸、l缬氨酸、l酪氨酸四种氨基酸中的任意两种与聚醚醚酮(peek)混合压片,得到六个氨基酸混合物样品,如图4a所示。聚醚醚酮(peek)是一种特种工程塑料,在太赫兹波段透明。
[0048]
步骤2:采用透射式太赫兹时域系统对氨基酸混合物样品进行逐点扫描,得到每个样品采样点对应的时域光谱数据(如图2a),通过傅里叶变换将时域光谱数据转换成频谱数据(如图2b),采用公式(1)-(2)计算吸收率,得到样品采样点的吸收光谱图,即一维吸收光谱(如图2c、2d和2e)。
[0049][0050][0051]
式中,n(ω)表示折射率,ω是角频率,φ(ω)表示在氨基酸混合物样品中传播引起的相位改变,c是真空中的光速,d是氨基酸混合物样品厚度,α(ω)表示吸收率,ρ(ω)表示氨基酸混合物样品和参考信号的幅值比。
[0052]
步骤3:构建氨基酸混合物样品的太赫兹光谱数据矩阵fn×
l
,采用公式(4)计算得到矩阵pm×
l
,即氨基酸混合物样品的化学图。
[0053]
[pm×
l
]=([sn×m]
t
[sn×m])-1
[sn×m]
t
[fn×
l
], (4)
[0054]
式中,l表示氨基酸混合物样品上的像素点,即采样点(事先将样品上的采样点的二维坐标转变为一维坐标,与l对应),n表示每一个像素点对应的n个太赫兹光谱数据频率分量,即fn×
l
为氨基酸混合物样品中l个采样点的太赫兹吸收光谱的n个频率分量组成的矩阵,sn×m表示己知的m种氨基酸的太赫兹光谱矩阵,每种氨基酸的太赫兹吸收光谱数据都有n个频率分量,即sn×m为已知的m种氨基酸的太赫兹吸收光谱的n个频率分量组成的矩阵,pm×
l
表示每个像素点出现某种氨基酸的概率,也被描述为化学图。本实施例中,sn×m表示采用的四种氨基酸的太赫兹吸收光谱的n个频率分量组成的矩阵,fn×
l
为任一个样品中l个采样点(所有采样点)的太赫兹吸收光谱的n个频率分量组成的矩阵,设i对应l-酪氨酸,p
ij
表示在像素j处l-酪氨酸出现的概率。
[0055]
步骤4:采用公式(5)对pm×
l
中的每一个数据自适应阈值去除背景,高于该阈值像素值设置为1,否则为0,得到处理后的化学图;
[0056]
c1=min(p)+c0[max(p)-min(p)] (5)
[0057]
式中,c1表示阈值0;max(p)是矩阵pm×
l
中元素的最大值,min(p)是矩阵pm×
l
中元素的最小值;c0是[max(p)-min(p)]值范围的权重,在本文中设置为0.6。
[0058]
步骤5:基于lenet-5构建了一个卷积神经网络,将对两组六个氨基酸混合物压片样品的25次扫描得到的50幅化学图分割成300张图像(2*6*25=300),将60%的图像用作训练数据,送入卷积神经网络进行训练,在经过四个迭代期后,网络实现收敛(如图5b所示),训练完成。
[0059]
如图5a所示,所述卷积神经网络包括依次相连的第一卷积-池化层(conv1)、第二卷积-池化层(conv2)、第一全连通层(fc1)、第二全连通层(fc2)和平面层(fc3)。其中,6个卷积核组成第一卷积-池化层(conv1),16个卷积核组成的第二卷积-池化层(conv2),第一
全连通层(fc1)大小为120、第二全连通层(fc2)的大小为大小为84。卷积滤波器的核大小为5,步进为1;两个全连通层将第二卷积-池化层(conv2)的输出转换为平面层的线性输入,全连通层使用sigmoid激活函数进行二进分类。网络选择adam训练策略,并使用二元交叉熵损失函数计算预测结果和数据标记之间的距离。训练的最大迭代次数为50,并在精度停止增长10个迭代期之后,提前终止训练。
[0060]
步骤6:将剩下的40%的图像作为测试数据输入到训练好的卷积神经网络进行测试,输出样品中采样点对应的氨基酸种类,如图4b和4c所示,对混合物组分的识别准确率达到100%,识别精度也达到100%,如图5c和5d所示。图6a中31表示true positve,0表示false positve,0表示false negative,27表示true negative,因此有31个含有l亮氨酸的被正确识别出来,27个不含l亮氨酸的也被正确识别,识别结果的分类混淆矩阵图。同理,图6b中32表示true positve,0表示false positve,0表示false negative,30表示true negative,因此有31个含有l酪氨酸的被正确识别出来,30个不含l酪氨酸的也被正确识别,识别结果的分类混淆矩阵图。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1