深度图生成
深度图生成
背景技术:
1.车辆通常配备有一个或多个相机和一个或多个雷达。相机可以检测在某个波长范围的电磁辐射。例如,相机可以检测可见光、红外辐射、紫外光或包括可见光、红外光和/或紫外光的某个范围的波长。雷达传输无线电波并接收那些无线电波的反射以检测环境中的物理对象。雷达可以使用直接传播,即,测量无线电波的发射和接收之间的时间延迟,或使用间接传播,即,调频连续波(fmcw)方法,即,测量发射和接收的无线电波之间的频率变化。
附图说明
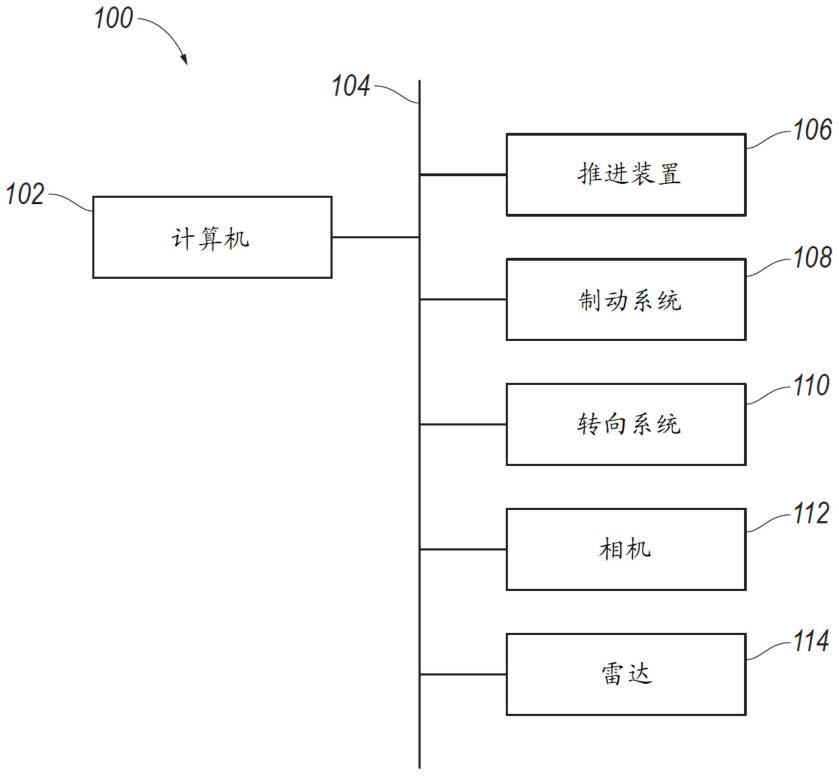
2.图1是具有雷达和相机的示例性车辆的框图。
3.图2是车辆和由雷达和相机检测到的示例性对象的示意性侧视图。
4.图3是来自相机的示例性图像帧,其中来自雷达的雷达像素被映射到图像帧上。
5.图4是图像帧中的雷达像素周围的示例性区域和叠加在图像帧上的多个示例性深度图像的图。
6.图5是示例性深度图。
7.图6是用于基于来自相机和雷达的数据生成深度图并操作车辆的示例性过程的过程流程图。
具体实施方式
8.本文描述的系统和方法包括使用来自车辆上的相机和雷达的数据来生成稠密深度图。出于本文档的目的,“深度图”被定义为图像,即,一组图像数据,其包含与场景对象的表面距视点的距离相关的信息,通常通过指定由像素表示的表面距视点的距离。车辆可以使用深度图来自主地或半自主地操作。
9.所述系统组合来自相机和雷达的数据以生成关于距场景中对象的距离的稠密数据,即,表示代表现实世界的区域或体积的更多而不是更少点的数据(例如按相机像素的密度)。雷达通常产生比来自相机的相机数据显著更稀疏的雷达数据,即,包括距对象的距离的雷达像素比包括在来自相机的图像帧中的相机像素相隔更远。相机不直接检测到场景中的对象的距离。然而,本文的系统使用来自相机和雷达的数据来产生其中距离数据的密度比雷达数据显著更高的深度图。此外,深度图具有高准确度。有利地,可以在不使用激光雷达的情况下生成深度图,所述激光雷达通常以比单独的雷达更高的密度检测关于场景的距离数据,同时施加显著的附加架构和处理要求。
10.一种计算机包括处理器和存储器,所述存储器存储指令,所述指令可由处理器执行以:从雷达接收雷达数据,所述雷达数据包括具有相应测量深度的雷达像素;从相机接收相机数据,所述相机数据包括具有相机像素的图像帧;将所述雷达像素映射到所述图像帧;生成围绕所述相应雷达像素的所述图像帧的相应区域;对于每个区域,确定所述区域中的所述相应相机像素的置信度分数;以及基于所述置信度分数输出所述相应相机像素的投影深度的深度图。所述置信度分数指示将所述区域的雷达像素的测量深度应用于所述相应相
机像素的置信度。
11.所述指令还可以包括用于基于所述深度图来操作包括所述雷达和所述相机的车辆的指令。
12.所述指令还可以包括用于生成对应于相应置信度阈值的多个深度图像的指令,每个深度图像指示置信度分数高于所述深度图像的所述置信度阈值的所述相机像素的深度。输出深度图可以基于深度图像。输出所述深度图可包括执行经训练网络,并且至所述经训练网络的输入可包括所述雷达像素、所述图像帧和所述深度图像。
13.所述置信度阈值可以是预设的并且彼此不同。
14.多个深度图像的数量可以是预设的。
15.确定置信度分数可以包括执行经训练网络。至所述经训练网络的输入可包括所述雷达像素、所述图像帧、光流和雷达流。在所述相机像素中的第一相机像素处的所述光流与所述雷达流之间的较小差异可增加所述经训练网络确定所述第一相机像素的较高置信度分数的可能性。
16.雷达像素和雷达流可以在一定时间间隔内累积。图像帧可以是第一图像帧,相机数据可以包括第二图像帧,并且光流可以表示第一图像帧与第二图像帧之间的场景移位。
17.经训练网络可为卷积神经网络。
18.所述区域可具有所述图像帧中相对于所述相应雷达像素的预设位置。所述区域可在所述图像帧中各自为预设形状,并且所述预设形状的高度可大于宽度。
19.所述区域可在所述图像帧中各自为预设形状,并且所述预设形状可从所述相应雷达像素竖直向上比向下延伸更大的距离。
20.输出所述深度图可包括执行经训练网络。
21.雷达数据可以是单行数据。
22.映射到图像帧之后的雷达像素在图像帧的水平方向上可能比相机像素更稀疏。
23.一种方法包括:从雷达接收雷达数据,所述雷达数据包括具有相应测量深度的雷达像素;从相机接收相机数据,所述相机数据包括具有相机像素的图像帧;将所述雷达像素映射到所述图像帧;生成围绕所述相应雷达像素的所述图像帧的相应区域;对于每个区域,确定所述区域中的所述相应相机像素的置信度分数;以及基于所述置信度分数输出所述相应相机像素的投影深度的深度图。所述置信度分数指示将所述区域的雷达像素的测量深度应用于所述相应相机像素的置信度。
24.参考附图,其中贯穿若干视图,相同的数字指示相同的部分,一种计算机102包括处理器和存储器,所述存储器存储指令,所述指令可由处理器执行以:从雷达114接收雷达数据,所述雷达数据包括具有相应测量深度的雷达像素116;从相机112接收相机数据,所述相机数据包括具有相机像素120的图像帧118;将所述雷达像素116映射到所述图像帧118;生成围绕所述相应雷达像素116的所述图像帧118的相应区域122;对于每个区域122,确定所述区域122中的所述相应相机像素120的置信度分数;基于所述置信度分数输出所述相应相机像素120的投影深度的深度图126;以及基于所述深度图126操作包括所述雷达114和所述相机112的车辆100。置信度分数指示将所述区域122的雷达像素116的测量深度应用于相应相机像素120的置信度。
25.参考图1,车辆100可以是任何乘用或商用汽车,诸如轿车、卡车、运动型多功能车、
跨界车、货车、小型货车、出租车、公共汽车等。
26.车辆100可以是自主或半自主车辆。计算机102可被编程为完全地或在较小程度上独立于人类操作员的介入而操作车辆100。计算机102可被编程为基于来自相机112和雷达114以及其他传感器的数据来操作推进装置106、制动系统108、转向系统110和/或其他车辆系统。出于本公开的目的,自主操作意指计算机102在没有来自人类操作员的输入的情况下控制推进装置106、制动系统108和转向系统110;半自主操作意指计算机102控制推进装置106、制动系统108和转向系统110中的一者或两者,而人类操作员控制其余部分;并且非自主操作意指人类操作员控制推进装置106、制动系统108和转向系统110。
27.计算机102是基于微处理器的计算装置,例如,通用计算装置(其包括处理器和存储器)、电子控制器或类似装置、现场可编程门阵列(fpga)、专用集成电路(asic)、前述各者的组合等。通常,在电子设计自动化中使用诸如vhdl(超高速集成电路硬件描述语言)的硬件描述语言来描述诸如fpga和asic的数字和混合信号系统。例如,asic是基于制造前提供的vhdl编程而制造的,而fpga内部的逻辑部件可以基于例如存储在电连接到fpga电路的存储器中的vhdl编程来配置。因此,计算机102可包括处理器、存储器等。计算机102的存储器可包括用于存储可由处理器执行的指令以及用于电子地存储数据和/或数据库的介质,和/或计算机102可包括诸如提供编程的前述结构的结构。计算机102可以是耦接在一起的多个计算机。
28.计算机102可以通过通信网络104(诸如控制器局域网(can)总线、以太网、wifi、局域互连网(lin)、车载诊断连接器(obd-ii))和/或通过任何其他有线或无线通信网络传输和接收数据。计算机102可经由通信网络104通信地耦接到相机112、雷达114、推进装置106、制动系统108、转向系统110以及其他部件。
29.车辆100的推进装置106生成能量并将能量转换成车辆100的运动。推进装置106可为常规的车辆推进子系统,例如,常规的动力传动系统,其包括耦接到将旋转运动传递到车轮的变速器的内燃发动机;电动动力传动系统,其包括电池、电动马达和将旋转运动传递到车轮的变速器;混合动力传动系统,其包括常规的动力传动系统和电动动力传动系统的元件;或任何其他类型的推进装置。推进装置106可包括与计算机102和/或人类操作员通信并从其接收输入的电子控制单元(ecu)等。人类操作员可经由例如加速踏板和/或换挡杆来控制推进装置106。
30.制动系统108通常是常规的车辆制动子系统并且抵抗车辆100的运动,由此使车辆100减慢和/或停止。制动系统108可以包括摩擦制动器,诸如盘式制动器、鼓式制动器、带式制动器等;再生制动器;任何其他合适类型的制动器;或者它们的组合。制动系统108可包括与计算机102和/或人类操作员通信并从其接收输入的电子控制单元(ecu)等。人类操作员可以经由例如制动踏板来控制制动系统108。
31.转向系统110通常是常规的车辆转向子系统并且控制车轮的转弯。转向系统110可以是具有电动助力转向的齿条与小齿轮系统、线控转向系统(这两者是已知的),或者任何其他合适的系统。转向系统110可以包括与计算机102和/或人类操作员通信并且从其接收输入的电子控制单元(ecu)等。人类操作员可经由例如方向盘来控制转向系统110。
32.相机112检测在某个波长范围的电磁辐射。例如,相机112可以检测可见光、红外辐射、紫外光或包括可见光、红外光和/或紫外光的某个范围的波长。例如,相机112可以是电
荷耦合装置(ccd)、互补金属氧化物半导体(cmos)或任何其他合适的类型。
33.雷达114传输无线电波并接收那些无线电波的反射以检测环境中的物理对象。雷达114可以使用直接传播,即,测量无线电波的发射和接收之间的时间延迟,和/或使用间接传播,即,调频连续波(fmcw)方法,即,测量发射和接收的无线电波之间的频率变化。
34.参考图2,相机112和雷达114相对于彼此固定,具体地具有相对于彼此的固定位置和取向。例如,相机112可以比雷达114安装得更高且更远。相机112可以安装在车辆100的车顶上,或者安装在车辆100的挡风玻璃内的顶板上。雷达114可以安装到车辆100的前保险杠。相机112和雷达114可以替代地固定到车辆100的其他位置。相机112和雷达114被取向成使得它们的视野重叠。例如,相机112和雷达114都可以在车辆前向方向上取向。
35.参考图3,相机112生成相机数据。相机数据是相机112的视野的多个,即,一系列图像帧118。每个图像帧118是包括相机像素120的二维矩阵。(在图3中,仅在图像帧118的左上角和区域122中的一个中示出了相机像素120,因为将它们全部示出是不切实际的,但是相机像素120在整个图像帧118上延伸)。每个相机像素120具有表示为一个或多个数值的亮度或颜色,例如,0(黑色)与1(白色)之间的光度光强度的标量无单位值,或红色、绿色和蓝色中的每一者的值,例如,每一个以8位为标度(0到255)或12位或16位为标度。相机像素120可以是表示的混合,例如,三个相机像素120和具有三个数值颜色值的第四相机像素120的强度的标量值的重复模式,或某种其他模式。图像帧118中的位置,即在图像帧118被记录时在相机112的视场中的位置,可以以像素尺寸或坐标来指定,例如,一对有序的像素距离,诸如来自图像帧118的顶部边缘的多个相机像素120和来自图像帧118的左侧边缘的多个相机像素120。
36.雷达114生成雷达数据。雷达数据包括多个雷达像素116。(在图3中,仅一个示例性雷达像素116用附图标记标记,因为将它们全部标记出来是不切实际的,但是所有灰度正方形都是雷达像素116。)雷达像素116指定环境中相对于雷达114的位置的相应位置。例如,雷达数据可以在球面坐标中,其中雷达114位于球面坐标系的原点处。球面坐标可以包括径向距离,即,从雷达114到由雷达114测量的点的测量深度;极角,即,从穿过雷达114的竖直轴到由雷达114测量的点的角度;和方位角,即,在水平面中从穿过雷达114的水平轴到由雷达114测量的点的角度。水平轴可以例如沿着车辆前进方向。替代地,雷达114可以将雷达像素116作为以雷达114为原点的笛卡尔坐标或作为任何其他合适的坐标系中的坐标返回,或者计算机102可以将球面坐标转换为笛卡尔坐标或另一坐标系。雷达像素116还可以包括径向速度,即,由雷达114测量的点朝向或远离雷达114的速度分量。
37.雷达数据可以是单行数据,即,雷达像素116可以水平序列布置而不是竖直堆叠。即使雷达像素116布置在单行中,雷达像素116也可以处于不同的高度或极角,如图3所示。(图3示出了在一定时间间隔内累积的雷达像素116)。雷达像素116比相机像素120更稀疏。例如,雷达像素116可以是单行而不是像相机像素120那样的多行,并且雷达像素116可以比相机像素120在水平方向上更稀疏。
38.图3示出了在映射到图像帧118之后的雷达像素116。例如,计算机102可以通过首先应用从雷达114的参考系到相机112的参考系的已知几何变换来将雷达像素116映射到图像帧118:
39.40.其中q是表示环境中的点的4元素矢量(xq,yq,zq,1),左上标c指示相机112的参考系,左上标r表示雷达114的坐标系,并且是从雷达114的参考系r到相机112的参考系c的4
×
4变换矩阵。变换矩阵基于相机112和雷达114的相对位置是提前已知的,并且存储在计算机102中。矢量q可以笛卡尔坐标表示,其中相对于相机112或雷达114取向的方向,x轴向左延伸,y轴向上延伸,并且z轴向前延伸,即,沿着z轴测量深度。矢量cq的前两个元素(即,矢量cq相对于相机112取向的方向的竖直分量和横向分量)可以移位和/或缩放已知常数以得出雷达像素116的像素坐标(i,j)。移位和/或缩放的常数基于相机112的物理性质。
41.返回到图2,使用变换矩阵将雷达像素116映射到图像帧118可以导致雷达像素116位于与具有与雷达像素116不同的深度的对象相对应的相机像素120处。例如,雷达像素116可以具有与在图像帧118中的雷达像素116的位置附近但与所述位置间隔开的相机像素120相对应的深度。又如,雷达像素116可以具有不对应于图像帧118中的相机像素120的深度,例如,如果雷达像素116是被遮挡在图像帧118之外的对象的雷达像素。在图2的示例中,雷达114可以检测图2中所示的具有相应深度da、db和dc的点a、b和c。使用变换矩阵将对应于点a、b和c的雷达像素116映射到对应于点a
p
、b
p
和c
p
的相机像素120。从相机112到点a
p
的实际深度与点a的雷达像素116的深度大致相同。从相机112到点b
p
的实际深度不同于对应于点b的雷达像素116的深度,但是从相机112到点b的实际深度与对应于点b的雷达像素116的深度相同。从相机112到点c
p
的实际深度不同于对应于点c的雷达像素116的深度,并且相机112被遮挡而不能检测到与从相机112到其的实际深度与对应于点c的雷达像素116的深度大致相同的点相对应的任何附近的相机像素120。
42.参考图4,在将雷达像素116映射到图像帧118之后,计算机102生成图像帧118的围绕相应雷达像素116的区域122,即,每个雷达像素116一个区域122。每个区域122是图像帧118的连续子集。每个区域122相对于相应的雷达像素116具有预设位置和预设形状。区域122的预设位置包括区域122内的雷达像素116,例如,在雷达像素116上水平地居中。相对于雷达像素116的预设形状的高度可大于宽度,这考虑了雷达数据具有更大的垂直稀疏性,例如,通过是单行。预设形状可以从相应的雷达像素116竖直向上比向下延伸更大的距离,这考虑了感兴趣的对象在雷达114高度上方的距离可能大于在雷达114高度下方的距离,部分原因是对象不能在车辆100正在其上行驶的地面下方。例如,预设形状可以是h
×
w矩形,其中h是沿着图像帧118的以相机像素120为单位的竖直距离,并且w是沿着图像帧118的以相机像素120为单位的水平距离,其中h》w。相对于相应的雷达像素116,区域122的预设形状可以向雷达像素116的左侧和右侧延伸距离w/2,并且预设形状可以在雷达像素116上方延伸距离h
上方
并在雷达像素116下方延伸距离h
下方
,其中h
上方
+h
下方
=h并且h
上方
》h
下方
。
43.计算机102确定每个区域122中的相应相机像素120的置信度分数。置信度分数指示相应相机像素120与同一区域122的雷达像素116具有相同深度的置信度。置信度分数可以表示为函数a(i,j,k),其中(i,j)是雷达像素116的像素坐标,并且k是围绕该雷达像素116的区域122中的相机像素120的索引。相机像素120的索引k具有范围[1,
…
n],其中n是区域122中的相机像素120的总数,例如,对于图4中所示的区域122的矩形预设形状,n=h
×
w。区域122中的每个相机像素120被分配针对该区域122的雷达像素116的深度d(i,j)以及置信度分数a(i,j,k)。对于多个区域122内的相机像素120,即,当区域122重叠时,相机像素
120被赋予置信度分数较高的雷达像素116的深度。如现在将描述的,确定置信度分数包括执行第一经训练网络,例如神经网络或其他机器学习程序。
[0044]
第一经训练网络从相机数据和雷达数据获取输入。至第一经训练网络的输入包括雷达像素116、图像帧118、光流和雷达流。光流描述了作为输入的图像帧118(其将被称为第一图像帧118)与第二图像帧118之间的场景移位,即,对应于空间中的相应点的像素坐标的差异。第二图像帧118可以来自与第一图像帧118不同的附近时间点。第二图像帧118可以在第一图像帧118之前或之后。例如,对于在第一图像帧和第二图像帧118中观察到的目标,光流给出从两个图像帧118中的较早者中的像素坐标到两个图像帧118中的后者中的像素坐标的映射,例如,flow((i1,j1))
→
(i2,j2)。可以使用用于图像的场景流的已知图像处理技术来确定光流。类似地,雷达流描述了两个时间点的雷达数据之间的移位,并且可以使用用于雷达数据的场景流的已知技术来确定。可以在某个时间点拍摄图像帧118和光流,并且可以在包括所述时间点的时间间隔内累积雷达像素116和雷达流。可以将时间间隔选择为短的,同时为第一经训练网络提供足够的雷达数据以实现准确的结果,例如0.3秒。可以使用车辆100的运动和/或来自雷达数据的径向速度将雷达数据变换为图像帧118的时间点,以便补偿车辆100和环境中的对象的运动。与相机数据相比,雷达数据在时间间隔内的累积补偿了雷达数据的相对稀疏性。
[0045]
第一经训练网络输出置信度分数a(i,j,k)。区域122中的第k个相机像素120的置信度分数a(i,j,k)指示将位于该区域122的(i,j)处的雷达像素116的测量深度d(i,j)应用于第k个相机像素120的置信度。置信度分数a(i,j,k)越大,测量的深度d(i,j)可能越接近相机像素120的真实深度。例如,计算机102可以将sigmoid函数应用于第一经训练网络的原始输出z(i,j,k)以获得在0至1的范围内的置信度分数a(i,j,k)。
[0046]
输入的组合可以用于生成置信度分数a(i,j,k)。图像帧118为每个雷达像素116提供场景背景,以及对象的边界信息。雷达像素116提供用于解译图像帧118的背景的深度以及用于预测附近相机像素120的深度的基础。光流和雷达流的配对提供了对遮挡和深度差的提示,这可能由于将雷达像素116映射到图像帧118而发生,如上面关于图2所述。给定相机像素120处的光流和雷达流之间的较小差异增加了第一经训练网络确定该相机像素120的较高置信度分数a(i,j,k)的可能性。对于静态对象,当相机像素120的深度与对应的雷达像素116的深度相同时,光流应等于雷达流。相反,被遮挡在相机112的视野之外的雷达像素116将具有与遮挡雷达像素116的静态对象的光流不同的雷达流。
[0047]
第一经训练网络可以是用于将输入转换为输出的置信度分数a(i,j,k)的任何合适类型的网络。例如,第一经训练网络可以是非常适合于分析视觉图像的卷积神经网络。卷积神经网络包括一系列层,其中每一层使用前一层作为输入。每个层包含多个神经元,所述多个神经元接收由前一层的神经元的子集生成的数据作为输入,并且生成发送给下一层中的神经元的输出。层的类型包括:卷积层,所述卷积层计算权重和小区域的输入数据的点积;池化层,所述池化层沿着空间维度执行下采样操作;以及全连接层,所述全连接层基于前一层的所有神经元的输出而生成。卷积神经网络的最后一层输出原始输出z(i,j,k)。替代地或另外地,第一经训练网络可以是例如具有跳层连接的编码器-解码器网络。具有跳层连接的编码器-解码器网络在图像分割方面表现良好,因此非常适合于使用相机数据来将置信度分数a(i,j,k)分配给特定的相机像素120。
[0048]
可以在训练集上训练第一经训练网络,所述训练集包括相机数据、雷达数据以及与相机数据和雷达数据相对应的地面实况深度。例如,训练集可以包括与相机数据和雷达数据配对的激光雷达数据,并且激光雷达数据可以用作地面实况。可以在短的时间间隔内累积激光雷达数据以增加由激光雷达数据返回的深度的密度,这可以产生更准确的训练网络。还可以以其他方式处理激光雷达数据以形成训练集,诸如使用激光雷达点的场景流、语义分割和/或3d边界框来从训练集中的相机数据中移除被遮挡的激光雷达点。这些类型的处理可以使激光雷达数据更准确。
[0049]
可以通过使损失函数最小化来在训练集上训练第一经训练网络。损失函数的一个要素是区域122中的每个相机像素120的标签,所述标签根据该区域122的雷达像素116的深度是否在该相机像素120的地面实况深度的阈值内,例如:
[0050][0051]
其中e
ijk
是(i,j)处的雷达像素116的深度与第k个相机像素120的地面实况深度之间的差值;ta是深度差e
ijk
的阈值;是缩放到雷达像素116的深度的相对深度差,即,并且tr是相对深度差的阈值。换句话说,如果雷达像素116的深度与相机像素120的地面实况深度之间的深度差和相对深度差小于相应阈值,则标签为1,否则,标签为0。可以选择阈值ta和tr以适应雷达114的误差余量。替代地,标签a
tr
(i,j,k)可以仅取决于深度差e
ijk
是否小于阈值ta,或者仅取决于相对深度差是否小于阈值tr。最小化损失函数可以是标签a
tr
(i,j,k)与原始网络输出z(i,j,k)之间的加权二进制交叉熵损失:
[0052][0053]
其中w(i,j,k)是指示是否存在(i,j)处的雷达像素116和第k个相机像素120的地面实况深度两者的二进制权重。如果两个条件都为真,则二进制权重w(i,j,k)等于1,否则等于0。可以通过应用sigmoid函数将原始网络输出z(i,j,k)转换为置信度分数a(i,j,k),即:
[0054][0055]
如下面将描述的,计算机102使用置信度分数a(i,j,k)来生成与相应的置信度阈值相对应的多个深度图像124。置信度阈值是预设的,例如,是由计算机102存储的常数。置信度阈值彼此不同,即,每个置信度阈值与其他置信度阈值不同,即,置信度阈值彼此都不相等。可以选择置信度阈值以为第二经训练网络提供足够的数据以执行如下所述的深度补全,例如,0.95、0.9、0.8、0.7、0.6和0.5。多个深度图像124的数量以及因此置信度阈值的数量是预设的,例如,将一定数量的不同置信度阈值存储在计算机102中。选择所述数量的置信度阈值以为第二经训练网络提供足够的数据以执行如下所述的深度补全,例如,六。
[0056]
计算机102生成对应于相应置信度阈值的深度图像124,即,针对每个置信度阈值生成深度图像124,例如,六个深度图像124:每个深度图像针对置信度阈值0.95、0.9、0.8、0.7、0.6和0.5中的每一者。每个深度图像124指示置信度分数高于该深度图像124的置信度
阈值的相机像素120的深度。换句话说,对于深度图像124中的一个中的每个相机像素120,如果相机像素120的置信度分数高于置信度阈值,则所述深度为相机像素120所在区域122的雷达像素116的深度,并且如果相机像素120的置信度分数低于置信度阈值,则相机像素120缺少深度值。如果相机像素120在多个区域122中,则相机像素120被分配给相机像素120具有较高置信度分数的区域122。如图4所示,深度图像124可以表示为多通道深度图像128,其中每个深度图像124是一个通道。通道的数量与深度图像124或置信度阈值的数量相同,例如,六个,其中图4中示出了三个。
[0057]
参考图5,计算机102输出相应相机像素120的投影深度的深度图126。深度图126可以包括每个相机像素120的深度。计算机102基于置信度分数输出深度图126。例如,计算机102基于深度图像124输出深度图126,所述深度图像是基于如上所述的置信度分数生成的。如现在将描述的,输出深度图126包括执行第二经训练网络。
[0058]
第一经训练网络从相机数据、雷达数据和第一经训练网络获取输入。至第二经训练网络的输入包括雷达像素116、图像帧118和深度图像124。
[0059]
第二经训练网络输出深度图126,即执行深度补全。深度图126包括每个相机像素120的深度,这意味着深度图126是密集的。深度不限于雷达像素116的深度。深度可以沿着朝向或远离车辆100延伸的对象的表面融合。
[0060]
第二经训练网络可以是用于执行深度补全的任何合适类型的网络,例如诸如已知的,例如引导卷积神经网络。
[0061]
可以在训练集上训练第二经训练网络,所述训练集包括相机数据、雷达数据以及与相机数据和雷达数据相对应的地面实况深度。例如,训练集可以包括与相机数据和雷达数据配对的激光雷达数据,如上相对于第一经训练网络所述进行处理的,并且激光雷达数据可以用作地面实况。
[0062]
图6是示出用于生成深度图126并基于深度图126操作车辆100的示例性过程600的过程流程图。计算机102的存储器存储用于执行过程600的步骤的可执行指令和/或可以诸如上述的结构来实施编程。当车辆100开启时,计算机102可以连续地执行过程600。作为过程600的总体概述,计算机102接收相机数据和雷达数据,将雷达像素116映射到图像帧118,生成围绕图像帧118中的雷达像素116的区域122,确定相机像素120的置信度分数,生成深度图像124,输出深度图126,并且基于深度图126来操作车辆100。
[0063]
过程600在框605中开始,其中计算机102接收来自相机的相机数据和来自雷达114的雷达数据。雷达数据包括具有测量的深度的雷达像素116,如上所述。如上所述,相机数据包括具有相机像素120的图像帧118。
[0064]
接下来,在框610中,计算机102例如使用如上所述的变换矩阵将雷达像素116映射到图像帧118。
[0065]
接下来,在框615中,计算机102生成围绕相应雷达像素116的图像帧118的区域122,如上文所述并且如图4所示。
[0066]
接下来,在框620中,计算机102通过执行第一经训练网络来确定区域122中的相机像素120的置信度分数a(i,j,k),如上所述。
[0067]
接下来,在框625中,计算机102使用置信度分数a(i,j,k)来生成深度图像124,如上所述。
[0068]
接下来,在框630中,计算机102通过以深度图像124作为输入执行第二经训练网络来输出深度图126,如上所述。
[0069]
接下来,在框635中,计算机102基于深度图126来操作车辆100。例如,计算机102可以致动推进装置106、制动系统108或转向系统110中的至少一者。例如,计算机102可以基于作为车道保持辅助特征的一部分的深度图126(例如,基于包括限定车道边缘的路沿或路肩的深度图126)来致动转向系统110。又如,计算机102可以基于作为自动制动特征的一部分的深度图126来致动制动系统108,例如,制动以防止车辆100接触环境中的对象。又如,计算机102可以自主地操作车辆100,即,基于深度图126致动推进装置106、制动系统108和转向系统110,例如,以在环境中的对象周围导航车辆100。在框635之后,过程600结束。
[0070]
一般来讲,所描述的计算系统和/或装置可以采用多种计算机操作系统中的任一种,包括但决不限于以下版本和/或种类:ford应用程序;applink/智能装置连接中间件;microsoft操作系统;microsoft操作系统;unix操作系统(例如,由加利福尼亚州红木海岸的oracle corporation发布的操作系统);由纽约州阿蒙克市的国际商业机器公司发布的aix unix操作系统;linux操作系统;由加利福尼亚州库比蒂诺市的苹果公司发布的mac osx和ios操作系统;由加拿大滑铁卢的黑莓有限公司发布的黑莓操作系统;以及谷歌公司和开放手机联盟开发的安卓操作系统;或由qnx软件系统公司提供的车载娱乐信息平台。计算装置的示例包括但不限于车载计算机、计算机工作站、服务器、台式机、笔记本、膝上型计算机或手持计算机、或某一其他计算系统和/或装置。
[0071]
计算装置通常包括计算机可执行指令,其中所述指令可由诸如以上列出的那些的一个或多个计算装置执行。可以由使用多种编程语言和/或技术创建的计算机程序编译或解译计算机可执行指令,所述编程语言和/或技术单独地或者组合地包括但不限于java
tm
、c、c++、matlab、simulink、stateflow、visual basic、java script、python、perl、html等。这些应用中的一些可以在虚拟机(诸如java虚拟机、dalvik虚拟机等)上编译和执行。一般来说,处理器(例如,微处理器)例如从存储器、计算机可读介质等接收指令,并且执行这些指令,由此执行一个或多个过程,包括本文所描述的过程中的一者或多者。此类指令和其他数据可使用各种计算机可读介质来存储和传输。计算装置中的文件通常是存储在诸如存储介质、随机存取存储器等计算机可读介质上的数据的集合。
[0072]
计算机可读介质(又被称为处理器可读介质)包括参与提供可以由计算机(例如,由计算机的处理器)读取的数据(例如,指令)的任何非暂时性(例如,有形)介质。此类介质可以采取许多形式,包括但不限于非易失性介质和易失性介质。非易失性介质可以包括例如光盘或磁盘以及其他持久性存储器。易失性介质可以包括例如通常构成主存储器的动态随机存取存储器(dram)。此类指令可以由一种或多种传输介质(包括同轴电缆、铜线和光纤(包括具有耦接到ecu的处理器的系统总线的导线))传输。计算机可读介质的常见形式包括例如软盘、软磁盘、硬盘、磁带、任何其他磁性介质、cd-rom、dvd、任何其他光学介质、穿孔卡片、纸带、任何其他具有孔图案的物理介质、ram、prom、eprom、快闪eeprom、任何其他存储器芯片或盒式磁带、或计算机可从中读取的任何其他介质。
[0073]
本文所述的数据库、数据存储库或其他数据存储可包括用于存储、访问和检索各种数据的各种机制,包括分层数据库、文件系统中的文件集、专用格式的应用程序数据库、
关系型数据库管理系统(rdbms)、非关系数据库(nosql)、图形数据库(gdb)等。每个这样的数据存储通常被包括在采用诸如以上提及中的一种的计算机操作系统的计算装置内,并且以各种方式中的任何一种或多种来经由网络进行访问。文件系统可以从计算机操作系统访问,并且可以包括以各种格式存储的文件。除了用于创建、存储、编辑和执行已存储的程序的语言(诸如上述pl/sql语言)之外,rdbms还通常采用结构化查询语言(sql)。
[0074]
在一些示例中,系统元件可被实施为一个或多个计算装置(例如,服务器、个人计算机等)上、存储在与其相关联的计算机可读介质(例如,磁盘、存储器等)上的计算机可读指令(例如,软件)。计算机程序产品可以包括存储在计算机可读介质上的用于执行本文所描述功能的此类指令。
[0075]
在附图中,相同的附图标记指示相同的元件。另外,可以改变这些元件中的一些或全部。关于本文描述的介质、过程、系统、方法、启发等,应理解,虽然此类过程等的步骤已被描述为按照某一有序的顺序发生,但是可以通过以与本文所述顺序不同的顺序执行所述步骤来实践此类过程。还应理解,可以同时执行某些步骤,可以添加其他步骤,或者可以省略本文描述的某些步骤。
[0076]
除非本文作出相反的明确指示,否则权利要求中使用的所有术语意图给出如本领域技术人员所理解的普通和通常的含义。特别地,诸如“一个”、“该”、“所述”等单数冠词的使用应被解读为叙述所指示的要素中的一个或多个,除非权利要求叙述相反的明确限制。形容词“第一”和“第二”贯穿本文档用作标识符,并且不意图表示重要性、次序或数量。
[0077]
已经以说明性方式描述了本公开,并且应理解,已经使用的术语意图具有描述性词语而非限制性词语的性质。鉴于以上教导,本公开的许多修改和变化是可能的,并且本公开可以不同于具体描述的其他方式来实践。
[0078]
根据本发明,提供了一种计算机,其具有处理器和存储器,所述存储器存储指令,所述指令可由处理器执行以:从雷达接收雷达数据,所述雷达数据包括具有相应测量深度的雷达像素;从相机接收相机数据,所述相机数据包括具有相机像素的图像帧;将所述雷达像素映射到所述图像帧;生成围绕所述相应雷达像素的所述图像帧的相应区域;对于每个区域,确定所述区域中的所述相应相机像素的置信度分数,所述置信度分数指示将所述区域的所述雷达像素的所述测量深度应用于所述相应相机像素的置信度;以及基于所述置信度分数输出所述相应相机像素的投影深度的深度图。
[0079]
根据一个实施例,所述指令还包括用于基于所述深度图来操作包括所述雷达和所述相机的车辆的指令。
[0080]
根据一个实施例,所述指令还包括用于生成对应于相应置信度阈值的多个深度图像的指令,每个深度图像指示置信度分数高于所述深度图像的所述置信度阈值的所述相机像素的深度。
[0081]
根据一个实施例,输出所述深度图基于所述深度图像。
[0082]
根据一个实施例,输出所述深度图包括执行经训练网络,并且至所述经训练网络的输入包括所述雷达像素、所述图像帧和所述深度图像。
[0083]
根据一个实施例,所述置信度阈值是预设的并且彼此不同。
[0084]
根据一个实施例,所述多个深度图像的数量是预设的。
[0085]
根据一个实施例,确定置信度分数包括执行经训练网络。
[0086]
根据一个实施例,至所述经训练网络的输入包括所述雷达像素、所述图像帧、光流和雷达流。
[0087]
根据一个实施例,在所述相机像素中的第一相机像素处的所述光流与所述雷达流之间的较小差异增加所述经训练网络确定所述第一相机像素的较高置信度分数的可能性。
[0088]
根据一个实施例,雷达像素和雷达流在一定时间间隔内累积。
[0089]
根据一个实施例,图像帧是第一图像帧,相机数据包括第二图像帧,并且光流表示第一图像帧与第二图像帧之间的场景移位。
[0090]
根据一个实施例,所述经训练网络为卷积神经网络。
[0091]
根据一个实施例,所述区域具有所述图像帧中相对于所述相应雷达像素的预设位置。
[0092]
根据一个实施例,所述区域在所述图像帧中各自为预设形状,并且所述预设形状的高度大于宽度。
[0093]
根据一个实施例,所述区域在所述图像帧中各自为预设形状,并且所述预设形状从所述相应雷达像素竖直向上比向下延伸更大的距离。
[0094]
根据一个实施例,输出所述深度图包括执行经训练网络。
[0095]
根据一个实施例,所述雷达数据是单行数据。
[0096]
根据一个实施例,映射到图像帧之后的雷达像素在图像帧的水平方向上比相机像素更稀疏。
[0097]
根据本发明,一种方法包括:从雷达接收雷达数据,所述雷达数据包括具有相应测量深度的雷达像素;从相机接收相机数据,所述相机数据包括具有相机像素的图像帧;将所述雷达像素映射到所述图像帧;生成围绕所述相应雷达像素的所述图像帧的相应区域;对于每个区域,确定所述区域中的所述相应相机像素的置信度分数,所述置信度分数指示将所述区域的所述雷达像素的所述测量深度应用于所述相应相机像素的置信度;以及基于所述置信度分数输出所述相应相机像素的投影深度的深度图。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1