大米类别鉴别模型及其构建方法以及鉴别大米类别的方法与流程
1.本发明涉及检测领域,具体涉及一种大米类别鉴别模型的构建方法,一种大米类别鉴别模型,以及一种鉴别大米类别的方法。
背景技术:
2.由于大米品种和产地环境不同,使其各种物质的含量和成分存在差异,一些大米因其独特的地理环境使其具有较高的营养价值和优良的口感,而成为地理标识产品,在市场上占据优势的销售价格。因此亟需开发大米快速鉴别技术,解决大米假冒问题,尤其是大米产地假冒的问题。
3.传统方法对于大米产地或品种的鉴别多采用经典的化学手段,而这些方法都普遍存在耗时长、前处理繁琐、人为误差大且对检验人员要求高等缺点。
4.分子光谱分析技术具有快速、无污染和同时检测多个组分等优点,通过建立的预测模型来测定未知样品所属类别,是一种间接的定性分析技术。采用光谱技术对大米类别进行检测可减少了检测时间,降低了实验误差,还能实现同时对多个理化指标进行分析检测,但是由于使用单一光谱数据存在片面性,使得大米类别鉴别正确率不能达到100%。
5.大米中主要含有淀粉,脂肪、蛋白质和氨基酸等有机化合物和钙、镁和铁等无机物质,近红外光谱、中红外光谱及拉曼光谱由于波长和机理不同反映了分子不同的振动信息,在鉴定有机化合物时红外光谱具有较大优势,而拉曼光谱能获得600cm-1
以下的谱图信息,在无机化合物鉴别方面更具优势。三种光谱均为重要的检测手段,具有差异性和互补性,3种光谱法相互配合补充可以获得更多的样品特征信息。
6.将不同光谱信息结合增加信息维度,可以获得更为精准、更为全面的特征信息,从而提高整个系统的性能和鉴别的准确度,因此数据融合技术在类别确证方面也有着很大优势。因此若能利用近红外光谱、中红外光谱及拉曼光谱融合技术建立一个快速预测模型来预测大米类别,不仅使识别正确率大大上升,还能减少检测时间,加大应用范围。
技术实现要素:
7.本发明的目的是为了克服现有技术存在的正确率低、耗时长、人为误差大和环境污染等问题,提供一种大米类别鉴别模型的构建方法,一种大米类别鉴别模型,以及一种鉴别大米类别的方法,该方法利用近红外光谱、中红外光谱及拉曼光谱融合技术建立一个快速检测模型来预测大米类别,不仅使识别正确率大大上升,还能减少测量时间,加大应用范围。
8.为了实现上述目的,本发明第一方面提供一种大米类别鉴别模型的构建方法,该方法包括:
9.(1)以不同类别的大米作为样本,分别采用近红外光谱、中红外光谱和拉曼光谱采集大米的光谱数据;
10.(2)分别对步骤(1)中得到的近红外光谱、中红外光谱和拉曼光谱的光谱数据进行
数据集的划分得到校正集和预测集,对校正集数据进行预处理,并对预处理后的数据进行特征波长的筛选,结合化学计量学方法通过数据融合建立鉴别模型;
11.(3)以校正集和预测集的正确率为标准,对步骤(2)得到的鉴别模型进行评估和筛选,得到大米类别鉴别模型。
12.本发明第二方面提供一种大米类别鉴别模型,所述模型的构建方法包括:
13.分别采用近红外光谱、中红外光谱和拉曼光谱采集不同类别大米的光谱数据;对得到的近红外光谱、中红外光谱和拉曼光谱的光谱数据进行数据集的划分得到校正集和预测集,对校正集数据进行预处理;并对校正集进行特征波长的筛选,结合化学计量学方法通过数据融合建立大米类别鉴别模型;
14.其中,所述预处理的方法为标准归一化(snv)与一阶微分或二阶微分的组合;
15.所述筛选的方法为竞争性自适应重加权采样法(cars);
16.所述化学计量学方法为k近邻算法(knn)或最小二乘-支持向量机算法(ls-svm)。
17.优选地,所述数据融合的方法为数据层融合、特征层融合或决策层融合。
18.本发明第三方面提供了一种鉴别大米类别的方法,该方法包括:分别采用近红外光谱、中红外光谱和拉曼光谱采集待测大米的光谱数据;将得到的光谱数据输入如上所述的大米类别鉴别模型中进行鉴别。
19.本发明创造性地将3种光谱(近红外光谱、中红外光谱以及拉曼光谱)数据分别进行数据层融合、特征层融合及决策层融合,建立了大米类别鉴别模型,其校正集和预测集识别正确率较单一光谱模型大大提升,能达到100%。
20.通过本发明所述的模型用于大米类别的鉴定还减少了检测时间,降低了实验误差,为大米类别鉴别提供了极大的便利。
附图说明
21.图1是本发明实施例1中使用的186个大米样品的原始近红外光谱图(a)、原始中红外光谱图(b)及原始拉曼光谱图(c);
22.图2是本发明实施例1决策层融合最优模型中校正集(a)和预测集(b)的参考值和预测值关系图。
具体实施方式
23.在本文中所披露的范围的端点和任何值都不限于该精确的范围或值,这些范围或值应当理解为包含接近这些范围或值的值。对于数值范围来说,各个范围的端点值之间、各个范围的端点值和单独的点值之间,以及单独的点值之间可以彼此组合而得到一个或多个新的数值范围,这些数值范围应被视为在本文中具体公开。
24.本发明第一方面提供一种大米类别鉴别模型的构建方法,该方法包括:
25.(1)以不同类别的大米作为样本,分别采用近红外光谱、中红外光谱和拉曼光谱采集大米的光谱数据;
26.(2)分别对步骤(1)中得到的近红外光谱、中红外光谱和拉曼光谱的光谱数据进行数据集的划分得到校正集和预测集,对校正集数据进行预处理,并对预处理后的数据进行特征波长的筛选,结合化学计量学方法通过数据融合建立鉴别模型;
27.(3)以校正集和预测集的正确率为标准,对步骤(2)得到的鉴别模型进行评估和筛选,得到大米类别鉴别模型。
28.在本发明中,大米的类别可以是以大米的产地或者大米的品种分类得到的,比如,按照产地,可以有东北大米、南方大米、五常大米、响水大米等,按照大米品种,比如可以水晶米、珍珠米、稻花香、长粒香、秋田小町、蟹田米等。
29.在本发明中,获得大米光谱数据的方法可以为本领域常规的方法,可以按照不同光谱检测的需要进行制样,并对操作条件和步骤进行合理的选择和调整。
30.在进行光谱分析时,样品可以以粉末的形式上样分析,可以采用本领域常规的方法制备粉末状样品,比如研磨后过筛,筛网比如具有100目或120目或目数更高的孔径,筛下物可以用于数据的采集。
31.对近红外光谱而言,比如,需要保证状样深度,比如不少于样品杯的1/3体积,样品保持蓬松和好的混合度;采集大米样品的近红外光谱数据时,可以采用漫反射模式,比如积分球漫反射模式,并基于实际需要调整操作。比如,分辨率控制在8-32cm-1
范围内,样品扫描次数为32-128,扫描谱区波数为3600-15200cm-1
,应当理解的是,本领域技术人员可以根据需要进行调整。
32.对于中红外光谱和拉曼光谱,可以通过压片法制备上样的样品,比如可以在15-25mpa压力下放置3-8min压成片。
33.中红外光谱的采集方式可以为衰减全反射模式,分辨率控制在2-8cm-1
范围内,样品扫描次数为16-64,扫描谱区波数为500-4000cm-1
,应当理解的是,本领域技术人员可以根据需要进行调整。
34.拉曼光谱采集条件可以包括:激光波长为780nm,激光能量为12-24mw,样品扫描谱区波数为50-3500cm-1
。
35.步骤(2)中,预处理的方法可以为本领域常规的预处理方法,用于消除干扰信息,比如可以选自标准归一化(snv)、一阶微分、二阶微分、均值中心化(mean centering)、多元散射校正msc(mulitiplicative scatter correction)、正交信号校正osc(orthogonal signal correction)、平滑(smoothing)和标准化(normalize)中的至少一种。
36.所述数据集的划分的方法可以为分层抽样法或随机抽样法。可以按照本领域常规的比例进行数据集的划分,比如校正集和预测集的比例可以为2.5-3.5:1。
37.由于预处理后的光谱数据分类特征不突出,需对其进行特征波长的筛选使数据降维,优选地,筛选特征波长的方法为竞争性自适应重加权采样法(cars)、连续投影算法(successive projections algorithm,spa)、无信息变量去除算法(uninformative variable elimination)或最小角回归算法(least angle regression,lar)。
38.优选地,所述化学计量学方法为k近邻算法(knn)、线性判别分析(lda)、最小二乘-支持向量机算法(ls-svm)、主成分分析(principal component analysis,pca)、马氏距离判别分析(mahalanobis distance,md)、簇类独立软模式分类法(soft independent modeling of class anallogy,simca)、偏最小二乘判别分析(pls-da)、fisher判别分析、聚类分析(cluster analysis,ca)或人工神经网络(artificial neural network,ann)。
39.k近邻算法(k nearest neighbor,knn)通过测量不同特征值之间的距离由距离其最近的k个邻居投票来决定预测集样品的所属类别,是简单数据挖掘算法的分类技术之一。
40.线性判别分析(linear discriminant analysis,lda)算法是使用统计学,模式识别和机器学习的方法从已知样品信息中筛选出与分类相关的若干个指标,得到分类的线性判别函数关系式,应用该函数对预测样品进行分类,此方法是对费舍尔的线性鉴别方法的归纳,是一个学习与预测的过程。
41.最小二乘-支持向量机(least squares-support vector machine,ls-svm)算法将传统支持向量机算法中的不等式约束改为等式约束,且将误差平方和损失函数作为校正集的经验损失,把解二次规划问题转化为求解线性方程组的问题,以提高鉴别模型求解速度和收敛精度。
42.优选地,所述数据融合的方式为数据层融合、特征层融合或决策层融合。
43.优选地,所述数据层融合的方式为将3种光谱经预处理的校正集数据串联成单个矩阵,然后筛选矩阵的特征波长,结合化学计量学方法建立鉴别模型。所述预处理的方式可以相同或不同,优选相同。比如,将所有样品的近红外、中红外及拉曼光谱原始数据均采用5种方法进行预处理,将3种光谱相同预处理的数据逐个连接串联成单个矩阵,经cars算法提取5个光谱融合矩阵的特征波长,筛选出来的5个特征矩阵结合knn算法、lda算法和ls-svm算法三种化学计量学分析方法建立15个鉴别模型。
44.优选地,所述特征层融合的方式为提取3种光谱经预处理后的数据的特征波长,并将得到的特征信息串联成单个矩阵,然后结合化学计量学方法建立鉴别模型。所述预处理的方式可以相同或不同,优选相同。比如,将所有样品的近红外、中红外及拉曼光谱原始数据均采用5种方法进行预处理,经cars算法提取15个预处理数据的特征波长,将3种光谱相同预处理的特征信息串联在单个矩阵中,结合化学计量分析方法knn、lda和ls-svm建立15个鉴别模型。
45.优选地,所述决策层融合的方式为获得每种光谱预处理的校正集数据的矩阵,然后筛选矩阵的特征波长,然后结合化学计量学方法建立单一光谱的鉴别模型,然后将3种光谱鉴别模型的校正集参考值和预测值分别融合,进行多元线性回归,得到鉴别模型。比如,将所有样品的近红外、中红外及拉曼光谱原始数据均采用5种方法进行预处理得到15个光谱预处理矩阵,经cars筛选矩阵的特征信息,结合knn算法、lda及ls-svm算法建立单一光谱鉴别模型,共计45个。将近红外、中红外及拉曼光谱模型的校正集参考值和预测值分别融合,进行多元线性回归(比如可以使用spss软件),得到鉴别模型。
46.以校正集和预测集的正确率为标准,对步骤(2)得到的鉴别模型进行评估和筛选,得到大米类别鉴别模型。应当理解的是,选择校正集和预测集的正确率高的模型为大米类别鉴别模型。
47.本发明第二方面提供一种大米类别鉴别模型,所述模型的构建方法包括:
48.分别采用近红外光谱、中红外光谱和拉曼光谱以不同类别大米的光谱数据;对得到的近红外光谱、中红外光谱和拉曼光谱的光谱数据进行数据集的划分得到校正集和预测集,对校正集数据进行预处理,并对预处理后的数据进行特征波长的筛选,结合化学计量学方法通过数据融合建立大米类别鉴别模型;
49.其中,所述预处理的方法为标准归一化(snv)与一阶微分或二阶微分的组合;
50.所述筛选的方法为竞争性自适应重加权采样法(cars);
51.所述化学计量学方法为k近邻算法(knn)或最小二乘-支持向量机算法(ls-svm)。
52.优选地,所述数据融合的方法为数据层融合、特征层融合或决策层融合,更优选为特征层融合或决策层融合,进一步优选为特征层融合。
53.优选地,所述数据集的划分的方法为分层抽样法或随机抽样法。
54.各方法的具体描述请参见第一方面。
55.在本发明的一种优选的实施方式中,所述数据融合的方法为数据层融合、特征层融合或决策层融合,所述预处理的方法为标准归一化(snv)与一阶微分的组合或标准归一化(snv)与二阶微分的组合,所述筛选的方法为竞争性自适应重加权采样法(cars);所述化学计量学方法为k近邻算法(knn)或最小二乘-支持向量机算法(ls-svm)。
56.在本发明的一种更优选的实施方式中,所述数据融合的方法为数据层融合,所述预处理的方法为标准归一化(snv)与一阶微分的组合或标准归一化(snv)与二阶微分的组合,所述筛选的方法为竞争性自适应重加权采样法(cars);所述化学计量学方法为最小二乘-支持向量机算法(ls-svm)。
57.在本发明的一种更优选的实施方式中,所述数据融合的方法为特征层融合,所述预处理的方法为标准归一化(snv)与一阶微分的组合或标准归一化(snv)与二阶微分的组合,所述筛选的方法为竞争性自适应重加权采样法(cars);所述化学计量学方法为k近邻算法(knn)或最小二乘-支持向量机算法(ls-svm)。
58.在本发明的一种更优选的实施方式中,所述数据融合的方法为决策层融合,所述预处理的方法为标准归一化(snv)与一阶微分的组合或标准归一化(snv)与二阶微分的组合,所述筛选的方法为竞争性自适应重加权采样法(cars);所述化学计量学方法为k近邻算法(knn)或最小二乘-支持向量机算法(ls-svm)。
59.在本发明的一种最优选的实施方式中,所述数据融合的方法为特征层融合,所述预处理的方法为标准归一化(snv)与一阶微分的组合或标准归一化(snv)与二阶微分的组合,所述筛选的方法为竞争性自适应重加权采样法(cars);所述化学计量学方法为最小二乘-支持向量机算法(ls-svm)。
60.本发明第三方面提供了一种鉴别大米类别的方法,该方法包括:分别采用近红外光谱、中红外光谱和拉曼光谱采集待测大米的光谱数据;将得到的光谱数据输入如上所述的大米类别鉴别模型中进行鉴别。
61.在本发明中,得到的光谱数据可以进行与对应模型校正集相同的预处理,提取与模型校正集筛选的相同特征波长的数据,按照模型校正集的数据融合方式进行数据融合,然后输入如上所述的大米类别鉴别模型中进行鉴别。
62.采集数据和对数据进行处理的方法参见第一和第二方面,在此不再赘述。
63.以下将通过实施例对本发明进行详细描述。
64.以下实施例中,如无特殊说明,采用的方法和手段为本领域常规的,使用的试剂和材料也是常规的。
65.傅里叶变换近红外光谱仪(mpaⅱ),德国布鲁克(北京)有限公司;
66.傅里叶变换中红外光谱仪(nicolet is50),赛默飞世尔科技(中国)有限公司;
67.智能dxr拉曼光谱仪,赛默飞世尔科技(中国)有限公司;
68.粉碎机,德国ika/艾卡(广州)仪器设备有限公司;
69.粉末压机(bj-15),天津博君科技有限公司。
70.样品前处理:经粉碎机将大米样品研磨成粉末通过100目筛,筛过的样品放入样品瓶,不要挤压样品,以保持蓬松和好的混合度以供近红外光谱仪测试。准确称取100mg大米粉末样品,在20mpa压力下放置5min压成片,每个样品压六个片待中红外和拉曼光谱仪检测使用。采集样品光谱时,环境温度为室温(25
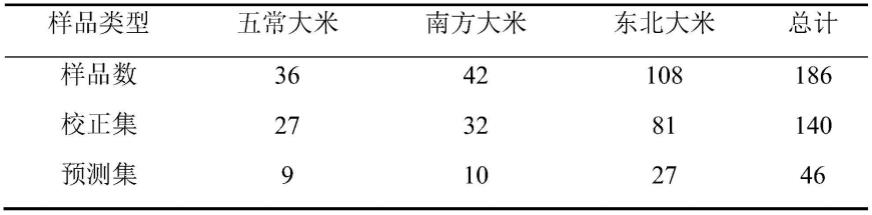
±
1)℃,均对样品进行三次扫描求平均以减少噪声干扰。
71.近红外光谱采集:取不少于样品杯1/3体积的大米粉末样品,采用积分球漫反射模式,分辨率为16cm-1
,样品扫描次数为64次,样品厚度为2cm,扫描谱区波数为3600-12500cm-1
。
72.中红外光谱采集:采用衰减全反射(attenuated total reflection,atr)模式,扫描次数为32次,分辨率为4cm-1
,扫描谱区波数为500-4000cm-1
。
73.拉曼光谱采集:激光波长为780nm,激光能量为24mw,样品扫描谱区波数为50-3500cm-1
。
74.实施例1
75.本实施例用于说明大米产地鉴别模型的构建。
76.所用大米样品共186份,其中五常大米36份,均采集于黑龙江省哈尔滨市五常市,品种为稻花香2号粳米;东北大米108份,采集于黑龙江省(牡丹市、哈尔滨市非五常地区、宁安市,鸡西市)、吉林省(德惠市、吉林市)、辽宁省(沈阳市、朝阳市),品种均为粳米;南方大米42份,采集于江苏省(南通市、泰州市)、广东省(深圳市、东菀市),品种均为粳米。
77.1、操作方法
78.(1)光谱数据预处理
79.对近红外光谱、中红外光谱及拉曼光谱数据均使用5种预处理方法消除干扰信息或基线漂移,标准归一化(standard normal variable,snv)、一阶微分(1st)、二阶微分(2nd)以及叠加预处理方法(snv+1st,snv+2nd),以选取大米产地鉴别最优模型。
80.使用竞争性自适应重加权采样法(competitive adapative reweighted sampling,cars)算法筛选特征波长。
81.(2)定性建模方法
82.将186份大米样品按照产地定义为三类,五常大米36份、南方大米42份、东北大米108份。按照校正集:预测集=3:1的比例,对样品隔三取一分组以保证校正集训练的均匀性,大米校正集和预测集样本分组情况具体见表1。
83.表1
[0084][0085]
(3)数据融合技术
[0086]
采用数据层融合、特征层融合和决策层融合三种方法进行数据融合。
[0087]
数据层融合是将所有样品的近红外、中红外及拉曼光谱原始数据均采用5种方法
进行预处理,将3种光谱相同预处理的数据逐个连接串联成单个矩阵,经cars算法提取5个光谱融合矩阵的特征波长,筛选出来的5个特征矩阵结合knn算法、lda算法和ls-svm算法三种化学计量学分析方法建立15个鉴别模型。
[0088]
特征层融合是将所有样品的近红外、中红外及拉曼光谱原始数据均采用5种方法进行预处理,经cars算法提取15个预处理数据的特征波长,将3种光谱相同预处理的特征信息串联在单个矩阵中,结合化学计量分析方法knn、lda和ls-svm建立15个鉴别模型。
[0089]
决策层融合是将所有样品的近红外、中红外及拉曼光谱原始数据均采用5种方法进行预处理得到15个光谱预处理矩阵,经cars筛选矩阵的特征信息,结合knn算法、lda及ls-svm算法建立单一光谱鉴别模型,共计45个。将近红外、中红外及拉曼光谱模型的校正集参考值和预测值分别融合,集成到spss软件中进行多元线性回归,建立15个鉴别模型。
[0090]
分别分析每个鉴别模型的校正集及预测集的正确率。
[0091]
2、结果
[0092]
(1)光谱分析
[0093]
图1示出了186个大米样品的原始近红外光谱图(a)、原始中红外光谱图(b)及原始拉曼光谱图(c)。
[0094]
近红外光谱波数范围在12820~4000cm-1
,如图1(a)所示在波段7500~9000cm-1
的峰为c-h的伸缩振动峰,其中8321cm-1
左右的吸收峰是由脂肪中的c-h引起的。6846cm-1
处的吸收峰是由大米中氨基酸引起的,在谱区4000~5500cm-1
的吸收峰表征的是大米样品中蛋白质及淀粉的c-h、n-h、o-h及c=o键的振动特征峰。
[0095]
中红外光谱波数范围在4000~400cm-1
,如图1(b)所示,在波段3000~3500cm-1
的吸收峰为o-h或n-h伸缩振动吸收峰;在波段2500~3000cm-1
的吸收峰为c-h伸缩振动吸收峰;在波段1500~2000cm-1
的峰为c=o伸缩振动和n-h弯曲振动特征峰;在波段1000~1500cm-1
的峰为蛋白质、淀粉及脂肪中的o-h、ch3及o-c-c的振动吸收峰;1000cm-1
以下的的指纹特征峰为糖骨架振动吸收峰。
[0096]
拉曼光谱的波数范围在50~4000cm-1
,如图1(c)所示,在波段0-500cm-1
之间的峰是由大米中淀粉的环骨架振动和扭动振动形成;在波段500-1000cm-1
之间的峰表征的是直链淀粉c-o-h的变形振动,在波段1000-1300cm-1
之间的峰表征了直链淀粉c-o-h的弯曲变形振动、糖苷的c-o伸缩振动和c-o-h弯曲变形振动、蛋白质的c-n伸缩振动;在波段1300-1500cm-1
之间的峰为淀粉和糖苷的c-c伸缩振动、c-o-h的形变振动、糖苷的c-h弯曲振动;在波段2500-3000cm-1
之间的峰为h-c-c和h-n-h伸缩振动。
[0097]
(2)近红外、中红外及拉曼光谱鉴别模型的建立及验证
[0098]
表2
[0099][0100]
将近红外光谱、中红外光谱及拉曼光谱分别结合knn、lda及ls-svm三种化学计量学方法建立45个鉴别模型,较优模型鉴别结果如表2所示。研究结果表明,三种光谱法均可对大米产地进行识别和分析,不同预处理方法对模型识别效果的影响均有差异,预处理方法snv+2nd在knn和ls-svm算法最优模型中出现频率最高。
[0101]
近红外光谱鉴别模型中,ls-svm算法结合snv+2nd预处理方法模型最优,其校正集和预测集识别正确率分别为95.71%和86.96%,该模型将3个五常大米、1个南方大米和2个东北大米样品识别错误。knn算法结合snv+2nd预处理方法模型预测集正确率为86.96%,将1个五常大米、1个南方大米和4个东北大米样品错误识别。lda算法结合2nd预处理方法模型预测集正确率为76.09%,东北大米样品有9个误判为南方大米,2个南方大米误判为东北大米。
[0102]
中红外光谱鉴别模型中,ls-svm算法结合1st预处理方法模型最优,其校正集和预测集识别正确率分别为97.14%和91.30%,但是误判了1个南方大米样品和2个东北大米样品。knn模型预测集正确率为89.13%,五常大米和东北大米均有1个样品误判错误。lda模型预测集正确率为80.43%,无法正确识别南方大米和东北大米。中红外光谱最优模型预测集正确率较近红外光谱最优模型提高了4.34%,可能由于中红外光谱数据量大,可以获得更多的大米样品信息,但因数据量大导致处理速度慢。
[0103]
拉曼光谱鉴别模型中,ls-svm算法结合snv+2nd预处理方法模型最优,其校正集和预测集识别正确率分别为100%和93.48%,该模型预测集正确率较近红外光谱和中红外光谱最优模型分别提高6.52%和2.18%,说明拉曼光谱可以采集到更多大米样品信息,适合大米产地鉴别模型的建立。knn模型和lda模型均无法正确识别大米产地,但其预测集正确率较中红外光谱的knn模型和lda模型均有提高。
[0104]
结果表明,3种光谱法均可用于大米产地鉴别模型的建立且取得良好的效果,3种化学计量分析方法中ls-svm算法的模型鉴别正确率最高,3种光谱法中拉曼光谱法最适合大米产地鉴别研究。但是单一光谱模型预测集正确率均未达到100%,无法达到快速准确鉴别大米产地的需求。
[0105]
(3)数据融合鉴别模型的建立及验证
[0106]
采用基于近红外光谱-中红外光谱-拉曼光谱的三种融合方法:数据层融合、特征层融合和决策层融合,三种融合模型较优结果如表3所示,光谱特征层融合结合ls-svm算法鉴别模型最优,其校正集和预测集正确率均能达到100%,可以实现对五常大米、东北大米和南方大米产地快速准确的识别。
[0107]
表3
[0108][0109][0110]
数据层融合鉴别模型中,ls-svm算法结合snv+2nd预处理方法模型和knn算法结合snv+1st预处理方法模型最优,预测集正确率均达95.65%,均误判了1个五常大米和1个南方大米样品。lda模型将3个南方大米样品误判为东北大米。对比表2和表3可知,数据层融合最优模型预测集正确率较单一光谱最优模型提高了2.17%。
[0111]
特征层融合鉴别模型中,ls-svm算法结合snv+2nd预处理方法鉴别模型最优,其校正集和预测集识别正确率均达100%,较决策层融合最优模型预测集正确率提高了2.17%,说明特征层数据融合方法更适用于本次融合的数据类型,适合大米产地鉴别模型的建立。knn方法结合snv+2nd预处理方法模型和lda方法结合1st预处理方法模型预测集正确率均为95.65%,各误判了1个五常大米样品。特征层融合最优模型较单一光谱最优模型预测集正确率高6.52%,可以满足快速准确检测五常大米、南方大米和东北大米产地的需求。
[0112]
决策层融合鉴别模型中,将五常大米、南方大米以及东北大米样品分别定义为数值1、数值2及数值3,定义预测结果在0.5~1.5范围内为五常大米,1.5~2.5范围内为南方大米,2.5~3.5范围内为东北大米。ls-svm算法结合snv+1st预处理方法模型最优,其预测集识别正确率达到97.83%,将1个五常大米样品误判为南方大米,该模型校正集和预测集参考值和预测值关系如图2所示。knn算法结合snv+2nd预处理方法模型预测集正确率为95.65%,将2个南方大米样品误判为东北大米。lda算法结合2nd预处理方法模型预测集正确率为93.48%,将3个南方大米样品误判为东北大米。决策层融合模型预测集正确率较单一光谱最优模型提升了2.18%,但均未达到100%。
[0113]
本发明创造性地建立了3种光谱的数据层融合、特征层融合及决策层融合鉴别模型,综合比较3种层次的数据融合方法,特征层融合产地鉴别模型中,ls-svm算法结合snv+2nd预处理方法鉴别模型最优,其校正集和预测集识别正确率均达到100%,较单一光谱最优模型预测集正确率提高了6.52%,可以快速准确鉴别五常大米、南方大米和东北大米产地。
[0114]
实施例2
[0115]
本实施例用于验证模型的适用性。
[0116]
对实施例1中得到了snv+2nd预处理方法结合特征层融合以及ls-svm算法的鉴别模型的适用性进行验证。
[0117]
新增产地为泰国的大米10份,原有五常大米36份,东北大米108份,南方大米42份,共计大米196份。
[0118]
将大米样品磨成粉末并通过100目筛,筛过的样品放入样品瓶,不要挤压样品,以保持蓬松和好的混合度以供近红外光谱仪测试。准确称取100mg大米粉末样品,在20mpa压力下放置5min压成片,每个样品压六个片待中红外和拉曼光谱仪检测使用。
[0119]
使用原仪器和原参数采集泰国大米的近红外光谱、中红外光谱及拉曼光谱数据,将196份大米原始的光谱数据进行snv+2nd预处理,经cars算法筛选特征波长,将3种光谱筛选的特征信息串联到单个矩阵中,按照3:1的比例划分校正集和预测集,校正集数据结合ls-svm化学计量学分析方法建立大米类别鉴别模型,使用该模型对校正集光谱和预测集光谱进行鉴别。
[0120]
结果发现,该方法构建的模型校正集和预测集的正确率均能达到100%,可以准确快速的识别泰国大米、五常大米、东北大米及南方大米,说明本发明所述的snv+2nd预处理方法结合特征层融合以及ls-svm算法的鉴别模型具有普遍的适用性,且能够保证建立的模型具有极高的正确率。
[0121]
实施例3
[0122]
本实施例用于验证模型的准确性。
[0123]
对实施例1中得到了snv+2nd预处理方法结合特征层融合以及ls-svm算法的鉴别模型的准确性进行验证。
[0124]
分别选取泰国大米、五常大米、东北大米及南方大米各5份,共计20份样品。将大米样品磨成粉末并通过100目筛,筛过的样品放入样品瓶,不要挤压样品,以保持蓬松和好的混合度以供近红外光谱仪测试。准确称取100mg大米粉末样品,在20mpa压力下放置5min压成片,每个样品压六个片待中红外和拉曼光谱仪检测使用。
[0125]
使用原设备和原参数采集20份大米样品的近红外光谱、中红外光谱及拉曼光谱数据,对所有样品的原始光谱进行snv+2nd预处理,经cars算法筛选特征波长,将3种光谱筛选的特征信息串联,调用实施例1中建立的相应模型进行鉴别。
[0126]
结果表明,此模型可以正确识别五常大米、东北大米及南方大米,能够识别泰国大米并不属于五常大米、东北大米及南方大米,识别正确率达到100%,适合大米类别的鉴别。
[0127]
大米产地在模型内的大米样品检测结果与样品实际产地一致,而其他产地的大米样品(泰国大米)经检测与模型并不对应,说明本发明建立的模型准确性高,能够排除其他样品的干扰,能够用于鉴别大米的产地,也能够用于鉴别大米的真伪。
[0128]
以上详细描述了本发明的优选实施方式,但是,本发明并不限于此。在本发明的技术构思范围内,可以对本发明的技术方案进行多种简单变型,包括各个技术特征以任何其它的合适方式进行组合,这些简单变型和组合同样应当视为本发明所公开的内容,均属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1