一种基于混合蚁群算法的微波扫频数据的二段式特征优化方法
本发明涉及农产品水分检测及特征选择领域,尤其涉及一种基于混合蚁群算法的微波扫频数据的二段式特征优化方法。
背景技术:
0、技术背景
1、微波自由空间传输法可以基于微波与水分子之间的相互作用来间接测量湿物料的含水率,具有非接触、高穿透力和快速检测等优点,是一种理想的农业物料水分无损检测技术。其具体原理为,当微波穿透待测物料时,其中的水分子引起的微波能量损耗远远超过其他干物质引起的损耗,因此通过测量与物料介电特性相关的微波信号的基本特征(如衰减和相移)就可以计算出含水率值。ma和okamura等学者的研究已经表明,使用单一频率的微波信号难以充分探测多组分材料中不同化学物质所引起的不同的信号变化,使用一组包含不同频率的扫频微波信号可以有效拓宽水分检测范围,提升水分检测精度。然而,不同频率的微波信号对水分的响应灵敏度存在差异性,扫频微波数据呈现高度相关性和多重共线性,在实际应用中需要建立一种完备的方法来针对性地优化微波扫频数据,客观、准确的筛选出适合某一类物料的微波检测频率。本发明提出一种基于混合蚁群算法的微波扫频数据的二段式特征优化方法,去除扫频微波信号中的冗余和噪声数据,并降低样本集划分方式给优化结果注入的随机性,以此实现对扫频微波信号频率的客观、准确的优化。
技术实现思路
1、本发明的目的是提供一种基于混合蚁群算法的微波扫频数据的二段式特征优化方法,去除扫频微波信号中的冗余和噪声数据,并降低样本集划分方式给优化结果注入的随机性,从而有效、客观地优化微波检测频率。
2、本发明的技术方案如下:
3、一种基于混合蚁群算法的微波扫频数据的二段式特征优化方法,包括:
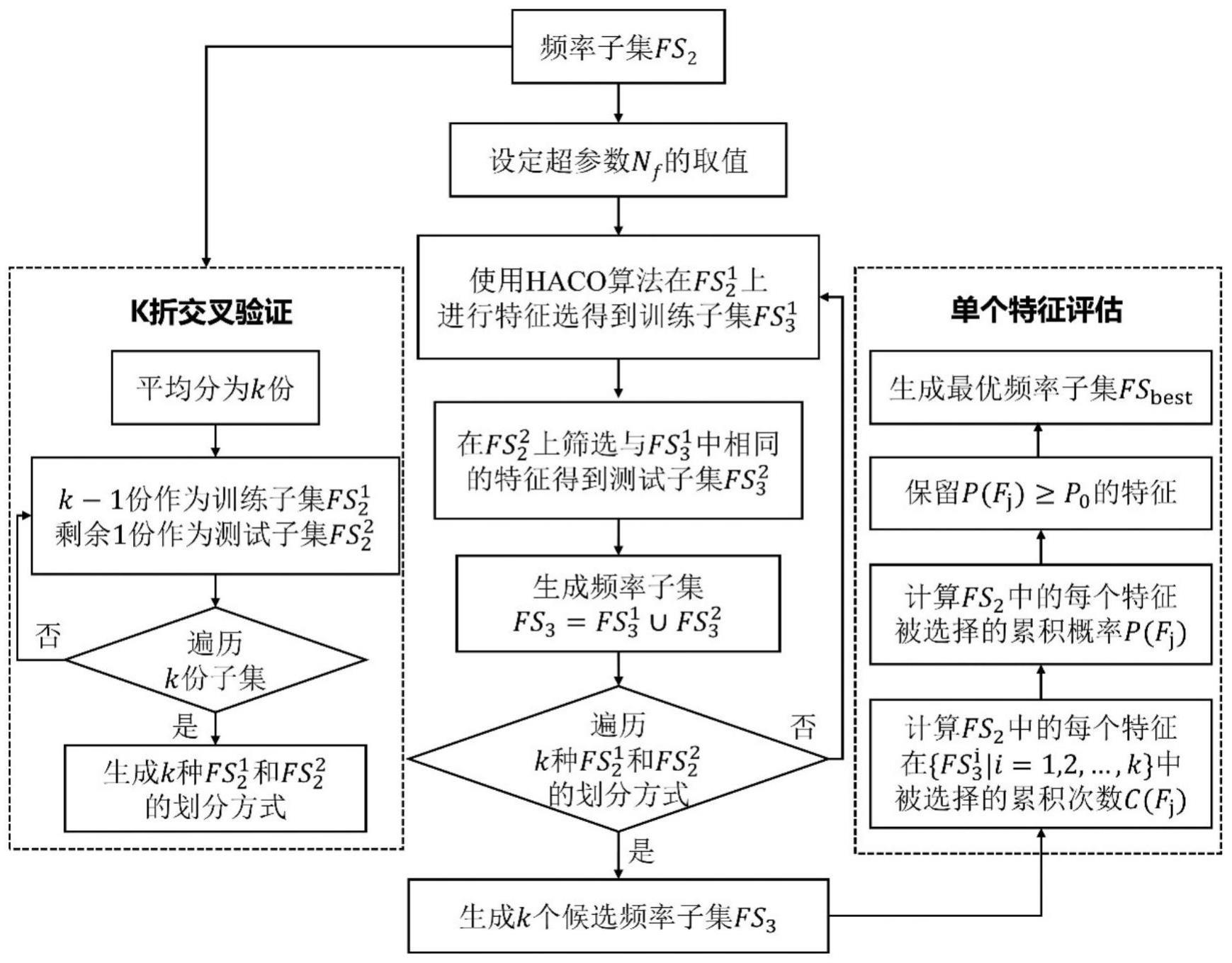
4、(1)使用扫频微波装置对待测样品进行检测,并标记所有样品的含水率标签值,获得扫频微波数据集fs;
5、第一阶段,基于过滤-嵌入式特征选择的特征空间精简,包括:
6、(2)使用最大信息系数评价法对获得的扫频微波数据集fs进行filter特征选择,生成第一频率子集fs1;
7、(3)使用岭回归—递归特征消除算法在第一频率子集fs1上进行wrapper特征选择,生成第二频率子集fs2;
8、第二阶段,基于混合蚁群优化算法的特征选择及评估,包括:
9、(4)使用k折交叉验证法对第二频率子集fs2进行划分,fs2被平均分成k份,取其中k-1份组合为训练集剩下1份作为测试集一共有k种训练集和测试集的划分方式;
10、(5)使用混合蚁群优化算法在训练集上进行特征选择,得到训练子集然后在测试集上筛选与训练子集相同的特征得到测试子集对训练子集和测试子集取并集,生成候选频率子集
11、(6)采用步骤(4)所述的k折交叉验证法和步骤(5)所述的混合蚁群优化算法在第二频率子集fs2上进行特征选择,遍历k种训练集和测试集的划分方式,生成包括k个候选频率子集的集合其中表示第i个候选频率子集;
12、(7)统计第二频率子集fs2中每个特征在所有候选频率子集集合中被选择的累积次数c(fj),再将每个特征的累积选择次数c(fj)除以交叉验证的次数k得到每个特征的累积选择概率p(fj);
13、(8)使用阈值分析法,选择累积选择概率p(fj)≥p0的特征,组成最优频率子集fsbest作为特征优化结果;其中,p0为阈值。
14、进一步地,所述步骤(1)中获得的扫频微波数据集fs表示为:
15、fs={(ft,yt)|t=1,2,…,m}
16、其中,ft={ft1,ft2,…,ftn}表示第t个样本的特征向量,yt表示第t个样本的含水率标签,n表示初始特征数量,对每一个初始特征进行编号,初始特征序号集合记为l0={1,2,…,n};m表示样本数量,ftn表示第t个样本的第n个特征值,所述的特征值为微波衰减值或微波相移值。
17、进一步地,所述步骤(2)具体为:
18、(2.1)基于最大信息系数理论计算扫频微波数据集fs中单个特征向量fj与样本的含水率标签之间的最大信息系数aj,具体计算公式为:
19、aj=mic(fj;y),j∈l0
20、其中,fj={f1j,f2j,…,fmj}表示第j个特征向量,fmj表示第m个样本的第j个特征值,y={y1,y2,…,ym}表示样本标签集合,ym表示第m个样本的标签,l0表示初始特征序号集合;
21、(2.2)设定筛选个数为n1,根据步骤(2.1)计算得到的最大信息系数的大小将扫频微波数据集fs中所有特征向量对应的编号倒序排列,保留编号排序靠前的n1个特征向量,生成第一频率子集l1表示第一频率子集fs1中的特征序号集合。
22、进一步地,所述步骤(3)具体为:
23、(3.1)采用岭回归算法训练基于第一频率子集fs1的样本含水率预测模型,获得每个特征对应的权重ωj,根据ωj的大小将第一频率子集fs1中所有的特征向量倒序排列,剔除权重最低的特征,更新第一频率子集fs1;
24、(3.2)设定筛选个数为n2,重复步骤(3.1),直至第一频率子集fs1中的特征数量达到预设的特征数量n2,保留第一频率子集fs1中剩余的特征,生成第二频率子集l2表示第二频率子集fs2中的特征序号集合。
25、进一步地,所述步骤(5)具体为:
26、(5.1)将步骤(4)中由第二频率子集fs2划分得到的训练集为目标数据集,将目标数据集映射为一张无向全连接图g,图中的每个节点都代表一个特征,其具体形式为:
27、g=(f,e)
28、其中,表示目标数据集中所有特征向量的集合,n2表示目标数据集中的特征数,m1表示目标数据集中的样本数,e={(fi,fj)|fi,fj∈f,i≠j}表示连接任意两个节点的路径,fi,fj分别表示第i个特征向量和第j个特征向量;
29、(5.2)算法参数初始化,包括选择的特征个数nf,蚁群中的蚂蚁个数na,蚁群迭代的最大次数imax,初始信息素浓度τ0,信息素权重α,信息素释放系数e,信息素蒸发系数ρ,启发因子权重β;
30、(5.3)基于皮尔逊相关系数理论计算特征向量之间的相似度,将相似度的倒数作为蚁群的启发因子η,具体计算公式为:
31、
32、
33、其中,i,j∈l2且i≠j,表示目标数据集中所有样本的第i个特征的均值,fti表示目标数据集中第t个样本的第i个特征值,∑t表示遍历目标数据集中所有样本求和,sim(.,.)表示目标数据集中两个特征向量之间的相似度;
34、(5.4)基于状态概率转移规则计算每个特征被第k只蚂蚁选择的概率pk,具体公式为:
35、
36、其中,表示当前选择特征fi的蚁群中的第k只蚂蚁的候选特征集合,fu表示候选特征集合中的任一候选特征,τj表示特征fj的信息素值,α和β分别表示信息素和启发因子的权重;
37、(5.5)根据步骤(5.4)计算得到的每个候选特征fj的转移概率值pk,采用轮盘赌规则决定第k只蚂蚁选择的下一个特征;
38、(5.6)重复步骤(5.4)-(5.5),直至第k只蚂蚁访问过的特征数量达到预设的特征个数nf;
39、(5.7)重复步骤(5.4)-(5.6),直至蚁群中所有的蚂蚁全部访问过nf个特征,生成na个候选特征子集l3表示候选特征子集s′中的特征序号集合;
40、(5.8)基于精英蚁群系统理论更新各节点的信息素值τ,具体公式为:
41、τi(t+1)=(1-ρ)τi(t)+eδτi(t)
42、
43、其中:e和ρ分别表示信息素的释放和蒸发系数,τi(t)表示第t代蚁群时特征fi的信息素浓度,δτi(t)表示第t代蚁群在特征fi关联的路径上释放的信息素值,ib表示被第t代蚁群中的适应度最高的精英蚂蚁访问过的特征子集,fitness表示适应度函数;
44、(5.9)重复步骤(5.4)-(5.8),直至种群迭代的次数达到最大迭代次数imax,保留适应度最高的特征子集,生成最优频率子集fshaco:
45、
46、其中,fshaco表示用haco算法进行特征选择得到的频率子集,记为训练子集l4表示最优频率子集fshaco中的特征序号集合;
47、(5.10)在测试集上筛选与训练子集特征序号相同的特征,得到测试子集对训练子集和测试子集取并集,生成候选频率子集fs3。
48、进一步地,所述步骤(7)中累积次数c(fj)和累积选择概率p(fj)的计算公式为:
49、
50、
51、其中,k表示交叉验证的折数,hi(fj)为二值标记,若频率子集fs2中的特征fj被第i个候选频率子集选中,hi(fj)则为1,否则为0。
52、本发明具有以下优势:
53、(1)本发明在第一阶段,基于filter-wrapper特征选择方法缩减微波扫频数据的特征空间,快速去除了低相关性和高冗余特征,有效提高了第二阶段haco算法的搜索效率;
54、(2)本发明在第一阶段采用mic计算特征与样本标签间的相关性,采用ridge的回归系数评价单个特征的重要性,在第二阶段采用pcc计算特征与特征间的相关性,采用svr的均方误差评价整个候选特征子集,从多个方面进行特征选择,有效提高了特征子集的最终质量;
55、(3)本发明考虑到数据集划分方式给扫频微波数据的优化结果注入的不确定性,结合多数投票法和交叉验证法评估各个特征被选择的累积概率,增强了对于微波频率特征优化的客观性和稳定性。
- 还没有人留言评论。精彩留言会获得点赞!