有限视场下结合双重卷积网络及循环神经网络的人群导航方法
本发明属于人工智能与机器人导航领域,特别涉及具有有限视场的机器人在动态密集人群中利用深度强化学习进行导航的方法。
背景技术:
1、移动机器人的一个主要目的是服务人类,保证人类安全是机器人开展工作的前提。移动机器人在人群环境中导航需要面对行走的行人,这就需要移动机器人具备面临突发情况的应变能力,使得规划的路径是安全、高效、舒适的。安全表示机器人在人群环境中导航不仅要保证自身安全还要和行人保持一定安全距离,高效表示机器人在人群环境中导航用最短的路径到达目标点,舒适表示机器人在进行路径规划时是不仅需要保证自身轨迹平滑,还不能驶入行人的舒适区。机器人在动态密集人群中进行导航任务时,由于只能对有限范围进行感知(有限视场),这对机器人的导航性能产生了极大挑战。目前人群导航算法根据是否具有自主学习的能力分为传统导航算法和基于学习的导航算法。
2、传统导航算法将行人当做简单的动态障碍物,当机器人遇到行人时会采取避障规则实现避免碰撞。传统导航算法原理简单,但需要人为设计模型来完成导航,目前并不清楚人类的复杂行为是否遵循这些精确的几何行为规则。当面临密集的人群环境,机器人不具备学习能力将限制器导航性能,无法服务于现实场景。
3、近年来快速发展的人工智能技术被引入进来解决人群导航问题,其中深度强化学习框架用于训练人群导航策略。基于深度强化学习的人群导航策略对机器人赋予学习能力,通过对与环境中的行人交互的经验进行学习,机器人根据学习到的导航策略在人群环境中进行导航。但是,现有人群导航策略并没有关注部分感知范围的机器人的情况,这导致机器人在具有有限视场情况下的导航性能急剧下降。
技术实现思路
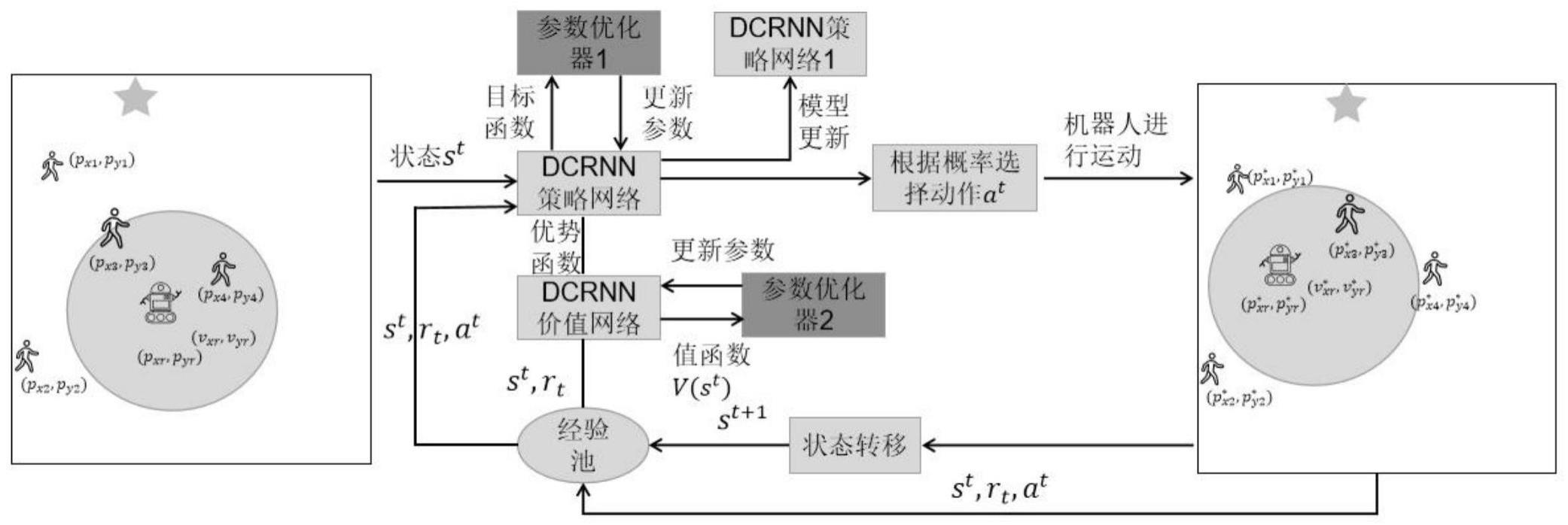
1、本发明的目的在于克服现有技术的上述不足,采用结合双重卷积及循环神经网络(double convolutional neural networks and recurrent neural network,dcrnn)算法的移动机器人人群导航模型。基于dcrnn的机器人人群导航模型包含dcrnn策略网络以及dcrnn价值网络。该算法是在机器人具有有限视场这一现实条件的情况下进行研究提出的。首先将人群环境中机器人导航决策作为强化学习(reinforcement learning,rl)决策问题进行描述,然后对环境中的机器人和人群进行建模,经过dcrnn更新状态信息计算出机器人最佳导航行为。如图1所示,该图是模型总体结构,这是一个对环境建模并将环境信息输入到模型后根据强化学习策略选择一个动作at的过程,机器人根据策略选取动作后得到一个奖励rt∈r。
2、本发明包括以下几个模块:
3、(1)环境建模模块:
4、1.1)将机器人和行人的部分交互行为建模为部分可观察马尔科夫决策过程(partially observable markov decision processes,mdp),用一个五元组<s,a,p,r,s*>表示。st∈s表示环境中智能体在时刻t的状态信息,
5、
6、其中,rt表示时刻t时机器人的状态信息,rt包含机器人位置(pxr,pyr),速度(vxr,vyr),目标点位置(gr,gy),转向角θ,感知半径α等信息。表示被机器人观测到的第i个行人的状态,包括第i个行人的位置信息(pxi,pyi),在本部分并不需要对行人的速度和感知半径进行观测,主要原因是现实场景中这两个参数是很难进行测量。在每次测试过程中,机器人总是从初始状态s0开始,根据策略π(at|st)在每个时间步采取动作at∈a后收到对应的奖励,并且根据为未知的状态转移概率函数p(st,st+1|at)将状态从st转变为st+1,同时其他行人也会根据既有的行为策略进行运动,变为下一状态。这个状态更新的过程会一直持续到机器人发生碰撞、到达目标点或者超时情况发生。
7、1.2)为了鼓励机器人对行人进行躲避并且快速到达目标点,设计了如下的奖励函数:
8、
9、其中表示时刻t机器人和行人的距离,距离行人越近,惩罚越大,相撞的惩罚最大。rs=20,表示到达目标点的奖励。朝向目标前进时获得奖励,远离获得惩罚。在时刻t,策略将观察到的动作空间选择一个动作是的奖励最大化:
10、
11、其中r(st,at,st+1)是奖励函数,γ∈(0,1]是累积奖励的折扣因子,假设机器人可以观察到行人,行人观察不到机器人,目的是防止机器人朝行人移动时,行人避开机器人。
12、(2)dcrnn神经网络模块设计
13、人群环境中包含各种各样的数据信息,机器人在收集信息训练时只考虑了机器人自身信息和行人位置坐标信息,并未将行人速度以及行人感知半径作为机器人导航考虑的信息,主要原因是现实场景中行人的速度和感知半径是难以精确测量。dcrnn神经网络内部结构如图2所示,将从环境中收集到的状态信息分别传递给dcnn网络模块和rnn网络模块,其中dcrnn编码器负责对环境中智能体(机器人和行人)之间的相对位置关系以及机器人运动趋势信息(速度、转向角)进行编码,rnn模块将机器人节点信息以及dcnn编码器输出拼接后与上一时刻隐藏状态信息作为输入,输出根据全连接层获得动作以及值函数的值。
14、2.1)dcnn模块设计
15、dcnn模块的主要作用是负责处理机器人自身运动趋势信息(机器人速度信息和转向角)以及机器人和行人相对位置关系信息。内部模型设计如图3所示,机器人和行人相对位置关系信息经过全连接层fedge后利用cnn1编码器编码,机器人速度信息先经过全连接层frobot扩充信息后再利用cnn2编码器编码,将两个编码后的信息利用mlp耦合,输出作为rnn网络模块输入的特征信息之一。
16、将机器人和感知范围内所有行人的位置相对关系用一个cnn网络进行编码,公式4如下:
17、
18、其中,机器人和感知范围内行人在t时刻位置相对关系,表示感知范围内行人和行人之间的相对位置关系,fedge表示全连接层。将机器人代表自身运动趋势的速度信息vpref=(vxr,vyr)和转向角θ输入到另一个cnn网络进行编码,公式5如下:
19、output2=cnn2(fv(vpref,θ)) (5)
20、其中fv()表示全连接层,利用一个mlp网络将两个网络输出进行耦合为rnn网络模块的特征信息之一,
21、 output3=mlp(output1,output2) (6)
22、output3这一特征信息有效表征了机器人和行人之间的潜藏关系,利用机器人状态信息rt作为rnn网络模块的另一特征信息。
23、2.2)rnn模块设计
24、rnn网络模块的内部结构如图4所示,该网络模块有三个输入,包括mlp输出的特征信息,机器人特征信息以及上一时刻隐藏状态信息,前两者经过一些计算后和上一时刻隐藏状态信息共同输入到gru单元进行状态更新。该网络模块的输出为x,表示机器人节点更新后的特征。
25、gru单元的输入之一input定义如下:
26、 <![cdata[output5=f<sub>cat</sub>(output3,f<sub>robot</sub>(r<sup>t</sup>))]]> (7)
27、其中,fcat()为矩阵拼接函数,frobot()为全连接层,rt为机器人的特征信息。gru单元定义如下:
28、
29、其中,为上一时刻隐藏状态信息,为当前时刻隐藏状态信息。rnn模块的输出将输入到全连接层分别获得动作和值函数的值。
30、(3)策略学习算法
31、使用一种无模型的策略梯度算法—近端策略优化(proximal policyoptimization,ppo)用于策略函数和价值函数的学习。ppo算法根据actor网络的更新方式可以分为含有自适应kl散度(klpenalty)的ppo-penalty和含有clippped surrogateobjective函数的ppo-clip,本发明主要使用ppo-clip这一梯度方法。如图1所示,机器人根据dcrnn策略选取动作后得到一个奖励rt∈r,其中(pxi,pyi)表示第i个行人的当前位置,(pxr,pyr)表示机器人的当前位置,(vxr,vyr)表示机器人的速度,经过dcrnn策略网络计算之后,根据概率分布预测下一最优动作为at以及利用dcrnn网络对动作价值进行评估,机器人根据预测的动作行动一步之后,得到下一环境状态信息st+1,表示下一时间步第i个行人的位置,表示下一时间步机器人的位置,表示下一时间步机器人的速度,下一状态经过状态转移后变为本时刻状态st,根据预测的状态与真实状态进行比较计算控制网络更新幅度。训练过程中运行12个环境实例来收集环境经验,通过将机器人人群导航问题分解为独立的小问题,使用两个卷积神经网络和一个循环神经网络有效学习对应问题的因子,通过ppo梯度算法训练dcrnn策略网络和价值网络来确定机器人在动态密集人群环境中选择的动作。
- 还没有人留言评论。精彩留言会获得点赞!