一种农用运输机械覆盖路径规划方法与流程
本发明涉及农用运输机覆盖路径规划,尤其涉及一种农用运输机械覆盖路径规划方法。
背景技术:
1、农业机械化是农业现代化的重要标志,然而尽管目前我国农业机械化成绩显著,但依然存在很多亟待解决的问题,比如不同地区的农业机械化水平差异较为明显和农机装备产业发展不平衡不充分,农机产品需求多样,农业机械科技创新能力不强等。随着农业机械化的推广,农业机械的智能化将会成为研究热点,也是“精细农业”的必然要求。
2、农业机械的自动导航是实现“精细农业”的基础,同时自动化路径规划是用于自动化导航系统的重要工具。在执行田间作业期间,它可以提供控制农业机器人和自动拖拉机所必须需的航路点,并且直接影响作业效果。因此,如何设计高效合理的路径规划算法是自动导航技术研究的关键。
技术实现思路
1、本发明的目的是根据农田路径规划覆盖率高的特点,利用深度强化学习方法进行农用运输机的路径规划,设计一个在尽可能短的时间内以尽可能小的消耗成本找到一个可行的最佳解决方案的覆盖路径规划算法。
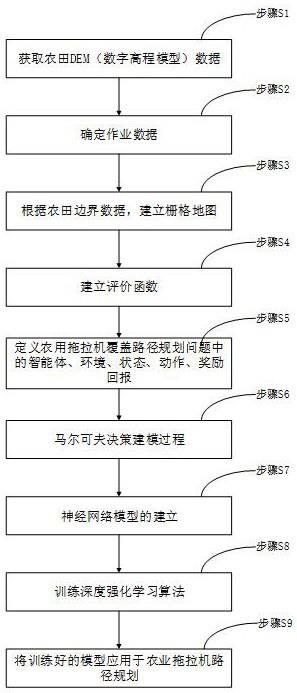
2、为了实现上述目的,本发明是采用以下技术方案实现的:所述的规划方法包括:
3、步骤1:获取农田dem数字高程模型数据,使用无人机搭载激光雷达采集农田的边界数据;
4、步骤2:确定作业数据;
5、步骤3:根据农田边界数据,建立栅格地图;
6、步骤4:建立评价函数;
7、步骤5:定义农用运输机覆盖路径规划问题中的智能体、环境、状态、动作、奖励回报;
8、步骤6:马尔可夫决策建模过程;
9、步骤7:神经网络模型的建立;
10、步骤8:训练深度强化学习算法;
11、步骤9:将训练好的模型应用于农用运输机路径规划。
12、进一步地,所述的步骤3根据农田边界数据,建立栅格地图,栅格地图根据车辆的大小将工作环境划分为大小相同的栅格。
13、进一步地,所述的步骤4建立评价函数;评价函数用于评价运输机的能量消耗,能量消耗指农用运输机按照覆盖路径规划结果行驶时的实际能耗,
14、平面行驶路径长度与能耗关系如下:
15、(1)
16、(2)
17、(3)
18、式中:表示路径中包含的栅格总数;表示地面摩擦系数;表示拖拉机平面行驶过程中耗能,,为农田dem数字高程模型数据中的坐标点,g为重力加速度;为拖拉机受到的地面摩擦力;
19、农用运输机作业行驶规划转弯过程,通过转弯时间来表征拖拉机转弯消耗,转弯时间和转弯次数是成正比,通过转弯次
20、数来表征拖拉机转弯能耗,因此,转弯次数与能耗关系如下:
21、(4)
22、(5)
23、(6)
24、式中:表示拖拉机航向角,单位;表示作业区域与轴夹角,单位;表示作业宽度,单位;为拖拉机受到的地面摩擦力;
25、综上可得拖拉机行驶过程中总耗能可表征为:
26、(7)
27、覆盖重复率指农用运输机在执行作业任务时,完成作业路径规划时,重复规划的作业面积与规划区域总面积之间的百分比,覆盖重复率表征方式如下:
28、(8)
29、式中:表示全覆盖重复率;表示行驶栅格总数;表示作业环境模型中障碍栅格总数;表示栅格面积;表示单个栅格的长度;表示单个栅格的宽度。
30、进一步地,所述步骤5中定义农用运输机覆盖路径规划问题中的智能体,智能体是做动作或决策的载体,在本问题中智能体就是农用运输机;定义农用运输机覆盖路径规划问题中的环境,环境是智能体交互的对象,在本问题中环境就是农田数据与栅格地图;
31、定义农用运输机覆盖路径规划问题中的状态,状态是对当前时刻环境的概况,在问题中就是t时间的栅格坐标;
32、定义农用运输机覆盖路径规划问题中的动作,动作是智能体基于当前状态所做出的决策,在问题中就是栅格地图的上、下、左、右方向的运动;
33、定义农用运输机覆盖路径规划问题中的奖励,奖励是指在智能体执行一个动作之后,环境返回给智能体的一个数值。
34、进一步地,所述步骤6马尔可夫决策建模过程:
35、随着时间的流动,农用运输机都会从环境中接收到一个状态,根据这个状态,车辆会做出一个动作,然后这个动作作用于环境,车辆便会接收到一个奖励,并且达到新的状态,因此,实际上车辆与环境的交互产生了一个序列:
36、
37、我们称之为顺序决策过程,因此可以使用马尔可夫决策过程来对该过程进行建模,模型可以由元组定义,其中为状态空间,为动作空间,为状态转移概率矩阵,为奖励函数,为折扣因子,
38、状态空间是指所有可能存在的状态的集合,记作字母
39、,分别代表时刻1的状态、时刻2的状态、时刻3的状态、…、时刻的状态,智能体当前状态;
40、动作空间是指所有可能动作的集合,记作字母
41、, 分别代表向上移动一个单位,向下移动一个单位,向左移动一个单位,向右移动一个单位和停在当前位置,农用运输机采取的动作;
42、状态转移是指智能体从当前时刻的状态转移到下一个时刻的状态的过程;用状态转移函数来描述状态转移,记作:
43、
44、表示发生下述事件的概率:在当前状态,智能体执行动作,环境的状态变成;
45、通常奖励是当前状态、当前动作、下一时刻状态的函数,把奖励函数记作定义机器人的奖励函数:
46、在当前状态下,采取动作后,如果农用运输机离最终点的距离更近,则给予奖励,如果农用运输机离最终点的距离更远,则给予奖励,如果农用运输机停留在原地,则给予奖励,如果农用运输机和其他单位发生碰撞,则给予奖励,如果农用运输机到达其最终点,则给予奖励;
47、(9)
48、其中,代表机器人在时刻机器人与目标点的距离,
49、代表机器人在时刻机器人与目标点的距离;
50、在马尔可夫决策建模过程中,通常使用折扣回报给未来的奖励打折扣,折扣回报的定义如下:
51、(10)
52、这里的是折扣因子;折扣因子代表智能体的远见,它的大小影响未来的动作的预测回报所占的权重,表示智能体只看重眼前动作的回报;时智能体将会把未来所有动作的回报值跟眼前动作的回报看的同等重要;当时表示越靠前的动作影响越大,而后面的动作影响变小。
53、进一步地,所述的步骤7神经网络包含当前网络q-eval和目标网络q-target两个q网络,其中当前网络用来根据当前的状态矩阵输出一个神经网络认为在此状态下最佳动作,目标网络根据移动机器人做完此动作后的环境给出q-target值;
54、在训练过程中,当前网络的输入只有当前栅格地图的状态矩阵,输出为当前环境下各个动作相对应的q值,移动机器人有很大概率选择q值最大的动作;目标网络的输入为在做出所选择的动作之后栅格地图的状态矩阵,输出也为各个动作相应的q值,选取最大的q值作为q-target;
55、当前网络和目标网络的结构相同神经网络的输入为与预处理后的栅格对应的状态矩阵,矩阵大小为 n*n 即栅格地图中栅格的个数,卷积层、全连接层、价值函数和优势函数构成了隐藏层;网络所采用的激活函数均为 relu 函数。
56、进一步地,所述的步骤9中,给农用运输机设置好起始点和目标点;中央控制器计算得到农用运输机的状态s,将状态s输入到深度强化学习网络中,得到各动作的q值;选择q值最大的动作作为待执行动作;中央控制器判断农业机器人的动作是否能够被执行,如果动作是可行的,则执行该动作,如果动作是不可行的,则让农用运输机停留在原地;如果农用运输机到达终点,则路径规划任务结束。
57、本发明有益效果:
58、本发明的目的是根据农田路径规划覆盖率高的特点,利用深度强化学习方法进行农用运输机的路径规划,设计一个在尽可能短的时间内以尽可能小的消耗成本找到一个可行的最佳解决方案的覆盖路径规划算法。
- 还没有人留言评论。精彩留言会获得点赞!