一种路径规划方法、装置、计算机设备及存储介质
本说明书涉及人工智能,尤其涉及一种路径规划方法、装置、计算机设备及存储介质。
背景技术:
1、目前,在自动驾驶车辆的路径规划模块设计过程中,基于强化学习的算法被广泛研究。通常,驾驶员在实际驾驶过程中遇到的问题复杂多样,且面对不同的问题应该基于不同的规则进行下一步的决策。由此,导致在训练用于实现端到端功能的强化学习算法时,样本需求量较大,且所面对原问题的解空间极大,由此,增加了强化学习算法的训练难度,以及需要消耗大量的计算资源。而基于规则的路径规划方法往往对场景进行划分,再单独对每类场景进行学习。因此,该类方法仅能在单一问题或特定几类问题的场景中应用,面对多种问题的行车环境表现较差。
2、如何实现在保证面对多种问题的行车环境时,提高决策的准确率的同时,降低计算机资源的消耗是现有技术中亟需解决的问题。
技术实现思路
1、为解决现有技术中的问题,本说明书实施例提供了一种路径规划方法、装置、计算机设备及存储介质,实现了在保证面对多种问题的行车环境时,提高决策的准确率的同时,降低计算机资源的消耗。
2、为了解决上述技术问题,本说明书的具体技术方案如下:
3、一方面,本说明书实施例提供了一种路径规划方法,包括,
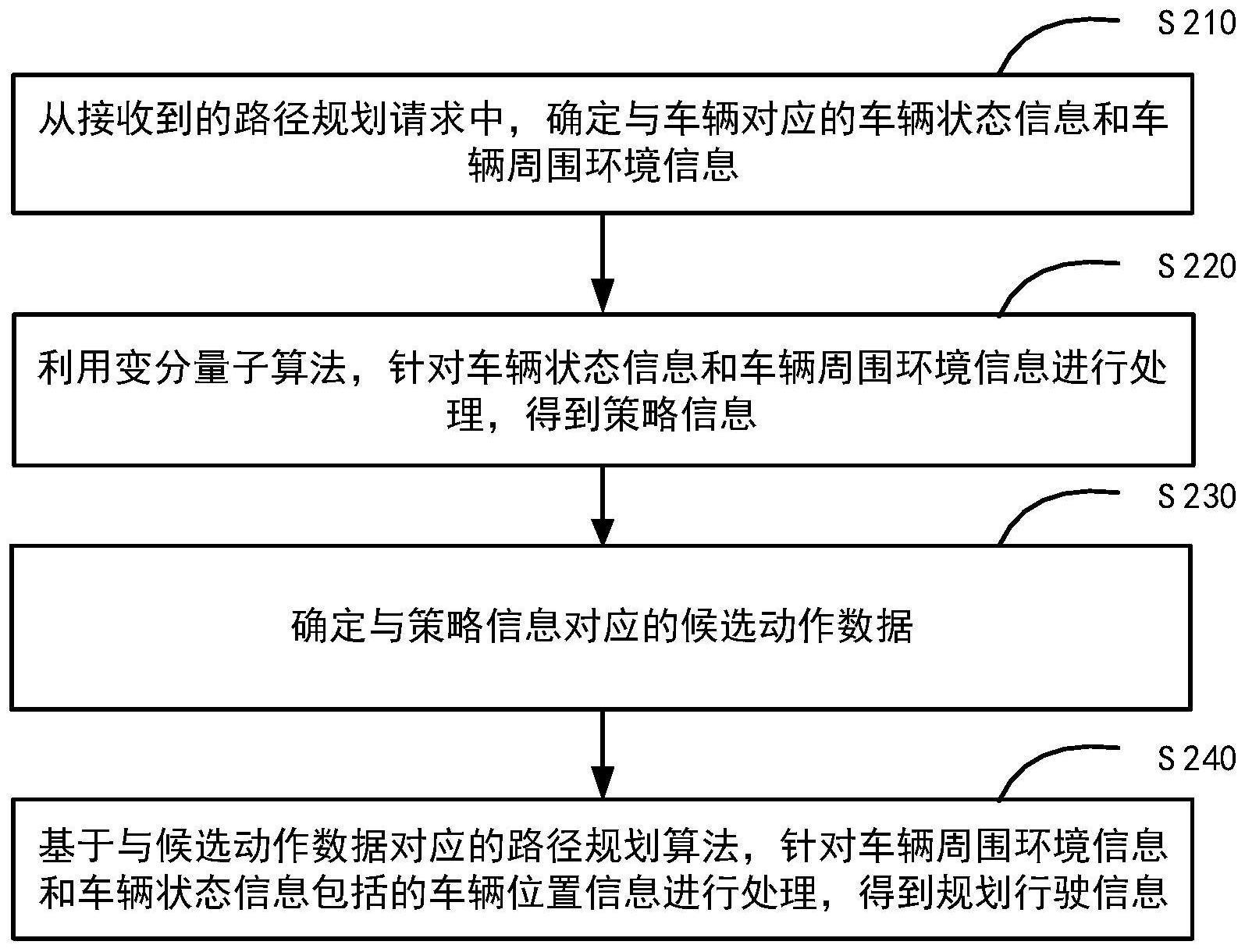
4、从接收到的路径规划请求中,确定与车辆对应的车辆状态信息和车辆周围环境信息;
5、利用变分量子算法,针对所述车辆状态信息和车辆周围环境信息进行处理,得到策略信息;
6、确定与所述策略信息对应的候选动作数据;以及
7、基于与所述候选动作数据对应的路径规划算法,针对所述车辆周围环境信息和所述车辆状态信息包括的车辆位置信息进行处理,得到规划行驶信息。
8、进一步,该在得到所述规划行驶信息之后,包括:
9、在车辆的行驶路径总个数满足预设条件的情况下,确定与每个时刻对应的安全信息、所述车辆状态信息、所述车辆周围环境信息和所述规划行驶信息,每个所述行驶路径与多个时刻相对应;
10、针对所述安全信息进行加权及折扣处理,得到与每个所述行驶路径对应的奖励函数值;以及
11、基于所述奖励函数值,对所述变分量子算法进行参数优化,得到优化后的变分量子算法,以用于下一时刻的路径规划。
12、进一步,该确定与所述策略信息对应的候选动作数据进一步包括,
13、确定所述策略信息表征的场景信息;
14、确定每个预设动作在与所述场景信息对应的场景中,被选择的概率;以及
15、基于所述概率,从所述预设动作中确定候选动作,并确定与所述候选动作对应的所述候选动作数据。
16、进一步,该路径规划算法包括轨迹跟踪算法和人工势场避障算法,所述与所述候选动作数据对应的路径规划算法的确定进一步包括,
17、在所述候选动作数据为第一数据时,确定所述轨迹跟踪算法为所述路径规划算法;以及
18、在所述候选动作数据为第二数据时,确定所述人工势场避障算法为所述路径规划算法。
19、进一步,该变分量子算法进一步包括:
20、
21、
22、其中,所述<oω>和所述<oω′>均表征由所述变分量子算法得到的厄尔米特观测值,所述厄尔米特观测值由所述车辆状态信息、所述车辆周围环境信息和所述变分量子算法的参数确定,所述ω和所述ω′均表征所述候选动作数据,所述pm表征量子态到特征值为m的本征空间m上的投影,所述πω表征所述策略信息,所述s表征所述车辆状态信息和所述车辆周围环境信息,所述ω表征策略参数,所述β表征玻尔兹曼探索方法的温度系数。
23、进一步,该针对所述安全信息进行加权及折扣处理,得到与每个所述行驶路径对应的奖励函数值进一步包括,
24、
25、
26、其中,所述gi,t表征与第i个行驶路径对应的所述奖励函数值,所述h表征与第i个行驶路径对应的总的时刻数,所述γ表征折扣因子,所述t表征所述时刻中的起始时刻,所述c表征加权后的所述安全信息,所述γ表征权重系数,所述j表征所述安全信息的类别,以及所述t′表征所述时刻。
27、进一步,该基于所述奖励函数值,对所述变分量子算法进行参数优化,得到优化后的变分量子算法,以用于下一时刻的路径规划进一步包括,
28、
29、
30、其中,所述ω表征所述策略参数,所述n表征在当前优化过程中的所述行驶路径总个数,所述h表征与第i个行驶路径对应的总的时刻数,所述ω表征所述候选动作数据,所述s表征所述车辆周围环境信息和所述车辆状态信息,所述g表征所述奖励函数值,所述q表征评价函数值,所述评价函数值根据所述车辆状态信息和所述车辆周围环境信息确定,所述a表征所述规划行驶信息,所述πω表征所述策略信息,所述<oω>和所述<oω′>均表征由所述变分量子算法得到的厄尔米特观测值,所述厄尔米特观测值由所述车辆状态信息、所述车辆周围环境信息和所述变分量子算法的参数确定,所述ω和所述ω′均表征所述候选动作数据,所述β表征玻尔兹曼探索方法的温度系数。
31、另一方面,本说明书实施例还提供了一种路径规划装置,包括,
32、第一确定单元,用于从接受到的路径规划请求中,确定与车辆对应的车辆状态信息和车辆周围环境信息;
33、第一处理单元,用于利用变分量子算法,针对所述车辆状态信息和车辆周围环境信息进行处理,得到策略信息;
34、第二确定单元,用于确定与所述策略信息对应的候选动作数据;以及
35、第二处理单元,用于基于与所述候选动作数据对应的路径规划算法,针对所述车辆周围环境信息和所述车辆状态信息包括的车辆位置信息进行处理,得到规划行驶信息。
36、进一步,该装置还包括,
37、获取单元,用于在车辆的行驶路径总个数满足预设条件的情况下,确定与每个时刻对应的安全信息、所述车辆状态信息、所述车辆周围环境信息和所述规划行驶信息,每个所述行驶路径与多个时刻相对应;
38、第三处理单元,用于针对所述安全信息进行加权及折扣处理,得到奖励函数值;以及
39、优化单元,用于基于所述奖励函数值,对所述变分量子算法进行参数优化,得到优化后的变分量子算法,以用于下一时刻的路径规划。
40、另一方面,本说明书实施例还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的方法。
41、另一方面,本说明书实施例还提供了一种计算机可读存储介质,其上存储有计算机指令,该计算机指令被处理器执行时实现上述的方法。
42、另一方面,本说明书实施例还提供了一种计算机程序产品,包括计算机程序/指令,所述计算机程序/指令被处理器执行时实现的方法。
43、利用本说明书实施例,在接受到路径规划请求时,确定与发送该路径规划请求的车辆对应的车辆状态信息和车辆周围环境信息;进而利用变分量子算法,对车辆状态信息和车辆周围环境信息进行处理,确定策略信息;利用与策略信息对应的路径规划算法,对车辆周围环境信息和车辆状态信息包括的车辆位置信息进行处理,得到规划行驶信息。从而,基于量子强化学习算法的量子纠缠减少参数量的特点,规避了强化学习算法的训练难度大和计算资源消耗大的问题;针对每一种训练场景,可以选择相应的路径规划算法,保证在面对多种问题的行车环境中,决策的准确性。
- 还没有人留言评论。精彩留言会获得点赞!