概率自更新的不确定环境机器人自适应导航方法及系统
本发明涉及机器人运动规划,尤其涉及一种概率自更新的不确定环境机器人自适应导航方法及系统。
背景技术:
1、运动规划是机器人研究领域的核心问题,因为它是机器人自主导航的重要组成部分,然而,移动机器人的工作环境具有高度的不确定性。例如,家庭环境中的机器人会受到人员移动、开门关门等动态干扰,环境的不确定性会影响任务执行的效率。目前大多数导航策略都是基于全局静态地图,忽视了环境中的不确定性,这可能导致机器人在复杂的不确定环境中反复重新规划路径。
2、目前,针对不确定环境下移动机器人的运动规划进行了一些研究,我们的工作更多地关注环境中的可穿越性变化,例如门的打开和关闭,而不是动态障碍物的不确定运动。此外,传统的导航系统大多采用反应性策略来应对不可预测的障碍物,并且对之前任务中遇到的障碍物没有记忆,因此无法利用过去的导航经验来改进策略。对于长时间部署在同一室内环境中的机器人来说,这种固定策略并不理想,并且机器人很可能总是执行被阻塞的路径。传统的运动规划算法大多采取乐观策略,即乐观地认为地图是静态不变的,直到遇到了意外的新障碍才会采取措施,重新规划一条绕开障碍的路径。
3、一个与移动机器人在不确定性下进行运动规划密切相关的问题被称为加拿大旅行者问题(the canadian traveler problem,简称为ctp),它最早由papadimitriou等人定义。简单来说,ctp就是在一张可能有一些边被阻塞的图中,找到从起点到终点的最优路径,只有当机器人走到边的末端才能确定这条边是否可以通过。针对这个问题也有一些求解方法的研究,但目前仍存在几大问题。一是大多数ctp求解算法需要知道某条边被阻塞的真实概率,然而,在真实的导航环境中,这些信息实际上很难获得,甚至不可能知道。另一个是现有的ctp算法大多是基于图的,很少与现有的移动机器人导航系统相结合,使机器人能够适应真实环境。此外,大多数算法将每次导航设置为独立的任务,仅在单次导航任务中进行策略优化,没有利用先前导航的经验来改进未来的策略,以适应环境的变化。
4、以a*(a-star)算法为例,a*算法是一种在确定图模型中通过访问并选取节点来搜索最短路径的路径规划方法,而在一些复杂动态的环境比如门很多的室内环境,可穿越性变化频繁的大型商超等不确定环境中,a*算法无法考虑此类不确定性,导致机器人始终采取乐观策略,忽视环境可穿越性变化,易使机器人在导航过程中出现被门反复阻塞,路径回溯等现象。其次,由于a*算法并不能利用先前导航的数据来改善其未来的导航策略,从而造成机器人无法适应环境变化,导航效率低;在启发式函数的设计上,传统a*算法简单地将欧式距离作为启发式代价的估计值,而忽视了环境特征,频繁导致搜索出的全局路径被阻碍,重规划次数太多,影响效率。综上,这三点都导致了机器人在复杂不确定环境中导航效率低的问题。
5、因此,我们为了解决这些问题,提出了一种考虑环境不确定性的路径规划算法,并在此基础上设计了自适应导航系统,使机器人在重复导航任务的过程中逐渐了解地图的不确定性,不断完善自身的规划策略,提高导航效率。
技术实现思路
1、为此,本发明实施例提供了一种概率自更新的不确定环境机器人自适应导航方法及系统,所要解决的技术问题为:由于传统a*算法忽视环境不确定性,在求解最优路径时,往往不能避开环境中可能关闭的门,此外,目前的机器人导航策略大多只考虑当前任务,并未利用过去的导航经验来指导未来的任务,以自主适应环境可能的变化。这些问题导致在不确定环境中导航时机器人频繁被意外出现的障碍(如门的关闭)阻碍原先规划的路径,进而需要多次重规划以进行调整,影响效率。
2、为了解决上述问题,本发明实施例提供一种概率自更新的不确定环境机器人自适应导航方法,所述方法包括:
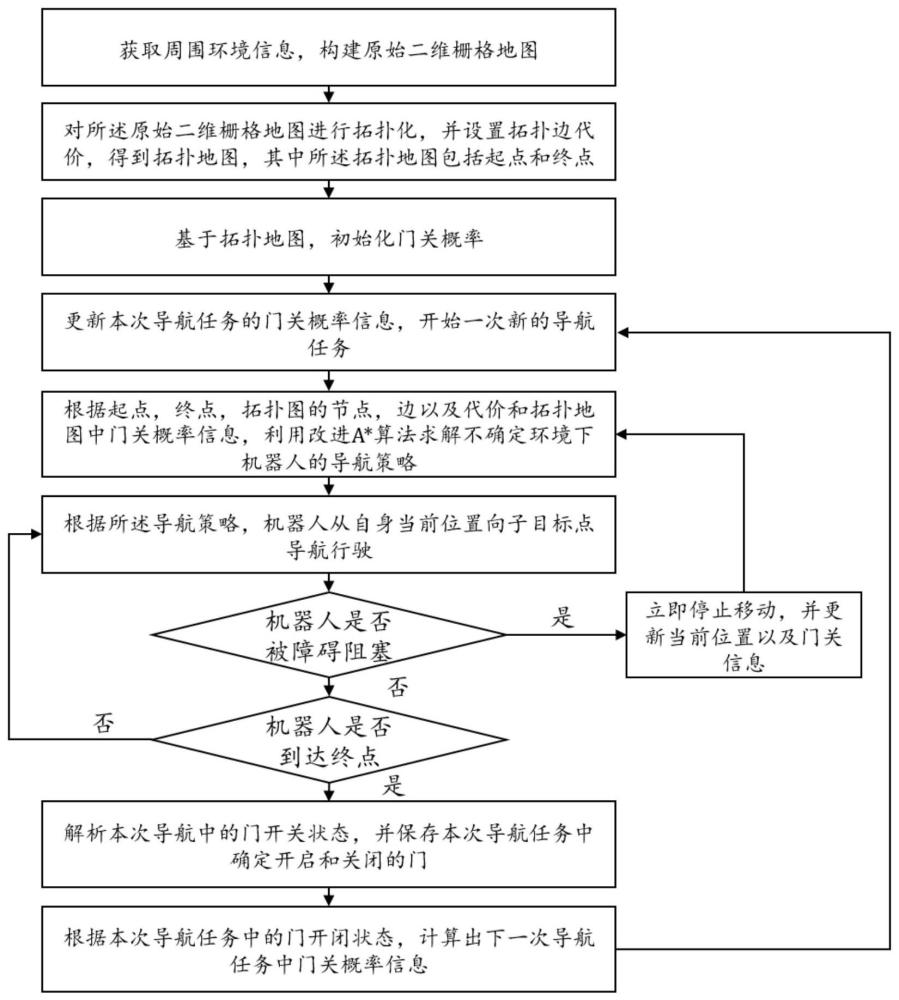
3、s1:获取周围环境信息,构建原始二维栅格地图;
4、s2:对所述原始二维栅格地图进行拓扑化,并设置拓扑边代价,得到拓扑地图,其中所述拓扑地图包括起点和终点;
5、s3:基于拓扑地图,初始化门关概率;
6、s4:更新本次导航任务的门关概率信息,开始一次新的导航任务;
7、s5:根据起点,终点,拓扑图的节点,边以及代价和拓扑地图中门关概率信息,利用改进a*算法求解不确定环境下机器人的导航策略;
8、s6:根据所述导航策略,机器人从当前位置向子目标点导航行驶;
9、s7:判断机器人是否被障碍阻塞,如果是,则立即停止移动,并更新当前位置以及门关信息并执行步骤s5;如果否,则执行步骤s8;
10、s8:判断机器人是否到达终点,如果否,则执行步骤s6;如果是,则解析本次导航中的门开关状态,并保存本次导航任务中确定开启和关闭的门;
11、s9:根据本次导航任务中的门开闭状态,计算出下一次导航任务中门关概率信息,并执行步骤s4。
12、优选地,在步骤s1中,获取周围环境信息,构建原始二维栅格地图的方法为:
13、机器人利用传感器获取环境信息,基于自适应蒙特卡洛定位来确定自身位姿,保证初始地图构建的精度,最终得到一张二维栅格地图作为任务的原始地图。
14、优选地,在步骤s2中,对所述原始二维栅格地图进行拓扑化的方法为:
15、首先,假设原始二维栅格地图中所有的门都是关闭的,将环境划分为各个区域;其次,根据任务需求设置起点和终点,并在地图中每个门的两侧分别设置对称的特征点,并根据导航参数确定对称点间距;最后,将每个区域的所有点两两连接形成拓扑边。
16、优选地,在步骤s2中,设置拓扑边代价的方法为:
17、当拓扑节点之间的直接连接不经过固定障碍物时,代价直接用欧氏距离表示;而当拓扑节点之间的连线穿过固定障碍是,则用迪杰斯特拉算法计算其绕过障碍的距离作为拓扑边代价。
18、优选地,在步骤s5中,改进a*算法的启发式估计代价h(n)的计算方法具体包括:
19、s51:设置采样轮数;
20、s52:基于门关概率信息,对拓扑地图中的穿越门的边进行随机采样,
21、得到所有边缘状态都确定的拓扑地图;
22、s53:在确定的拓扑地图中用迪杰斯特拉算法,得到从当前节点到终点的距离;
23、s54:将计算得出的距离进行累加;
24、s55:反复执行步骤s52~s54,直到达到采样轮数,最终取累加距离的平均值作为a*算法启发式估计代价h(n)的值。
25、优选地,在步骤s7中,判断机器人是否被障碍阻塞的依据为:
26、通过实时比对下一时刻发布的路径末尾点坐标是否与前一时刻发布的相同,若是,则机器人被障碍阻塞,若否,则机器人没有被障碍阻塞。
27、优选地,在步骤s8中,解析本次导航中的门开关状态的方法具体包括:
28、s81:根据导航策略,获取导航路径预计要穿越的门信息;
29、s82:将预计要穿越的门状态设置为开;
30、s83:判断机器人是否被门阻塞,如果是,则执行步骤s84;
31、s84:通过时定位与地图构建模块判断被哪个门阻塞,判断此门为关,并将机器人在此门之前经过的所有门设定为开,再执行步骤s81;
32、s85:反复执行步骤s81~s84,直到到达终点,本次导航任务完成,解析本次导航中的门开关状态。
33、优选地,在步骤s9中,根据本次导航任务中的门开闭状态,计算出下一次导航任务中门关概率信息的方法具体包括:
34、s91:在第一次任务开始前,对于所有的门关事件设置总例数为2,正例数为1;
35、s92:读取本次导航任务中的门开闭状态,对于所有状态为关的门,将正例数与总例数加1,对于所有状态为开的门,仅将总数加1;
36、s93:针对每扇门根据威尔逊置信区间分别计算置信区间均值mean作为概率估计的修正值,其中区间均值mean计算方法为:
37、
38、
39、式中,w-表示置信区间下限;w+表示置信区间上限;z表示正态分布的分位数,为固定参数,在95%置信水平下z取1.96;n表示实验中的总例数;p表示实验中的正例数占总数的比例,若k表示正例数,则
40、本发明实施例还提供了一种概率自更新的不确定环境机器人自适应导航系统,其特征在于,所述系统用于实现上述所述的概率自更新的不确定环境机器人自适应导航方法,具体包括:
41、栅格地图构建模块,用于获取周围环境信息,构建原始二维栅格地图;
42、拓扑地图构建模块,用于对所述原始二维栅格地图进行拓扑化,并设置拓扑边代价,得到拓扑地图,其中所述拓扑地图包括起点和终点;
43、门关概率初始化模块,用于基于拓扑地图,初始化门关概率;
44、门关概率更新模块,用于更新本次导航任务的门关概率信息,开始一次新的导航任务;
45、导航策略求解模块,用于根据起点,终点,拓扑图的节点,边以及代价和拓扑地图中门关概率信息,利用改进a*算法求解不确定环境下机器人的导航策略;
46、导航行驶模块,用于根据所述导航策略,机器人从当前位置向子目标点导航行驶;
47、第一判断模块,用于判断机器人是否被障碍阻塞,如果是,则立即停止移动,并更新当前位置以及门关信息并执行导航策略求解模块;如果否,则执行第二判断模块;
48、第二判断模块,用于判断机器人是否到达终点,如果否,则执行导航行驶模块;如果是,则解析本次导航中的门开关状态,并保存本次导航任务中确定开启和关闭的门;
49、下一次导航任务中门关概率信息计算模块,用于根据本次导航任务中的门开闭状态,计算出下一次导航任务中门关概率信息,并执行门关概率更新模块。
50、本发明实施例还提供了一种自适应导航机器人,所述自适应导航机器人包括上述所述的概率自更新的不确定环境机器人自适应导航系统,实现在不确定环境下的自适应导航。
51、从以上技术方案可以看出,本发明申请具有以下优点:
52、本发明实施例提供了一种概率自更新的不确定环境机器人自适应导航方法及系统,利用互信息感知原理来使机器人自主收集环境信息,并将其利用于未来导航任务。同时,在求解导航策略时将环境不确定信息纳入考虑,令机器人在导航时选取被阻塞概率更低的路径,这样能够使机器人在保证自主性的前提下,利用经验改善决策,适应环境变化,进而提高不确定环境中的导航效率。本发明优化了传统a*算法中的启发式代价,解决了忽视不确定性的问题,综合考虑路径长度和不确定性,使机器人选取更安全的路径。此外,本发明基于拓扑图表征方法,设计阻塞判断算法和门状态解析算法来获取导航经验信息,然后基于概率更新机制,自主利用过去经验优化导航策略,最终提高在不确定环境中的导航效率。
- 还没有人留言评论。精彩留言会获得点赞!