基于近端策略优化的多无人艇深度强化学习协同导航方法
本发明属于无人艇多目标导航,具体涉及一种基于近端策略优化的多无人艇深度强化学习协同导航方法。
背景技术:
1、近年来,随着无人艇技术的发展,无人艇已广泛应用于狩猎、救援、检测等任务。与单一的无人艇系统相比,多无人艇协同作业可以完成单一无人艇不能高效完成或者无法完成的复杂任务,所以多无人艇协同作业在军事和民用领域得到广泛的应用。
2、随着深度学习和强化学习的不断发展,逐渐衍生出一个新兴的交叉领域,即深度强化学习。它结合了深度神经网络的表征能力和强化学习的决策能力,为智能体提供了一种端到端学习策略的方式。一些基于深度强化学习算法多无人艇路径规划的相关研究,通过设计合理的奖励函数,完成了多无人艇在复杂多变的环境中自主导航的任务。
3、虽然无人艇的运动控制已经取得丰硕的研究成果,但是现有的研究仍然存在一些局限性,如在导航方面,现在有的研究主要集中在单无人艇的目标导航问题,但随着海上作业任务日益复杂,无人艇单体能力受限,在实际的应用中往往需要多无人艇协同作业;在航海安全方面,现有的避障避碰方法只考虑了单无人艇的避碰问题,约束条件单一,而多无人艇避碰避障问题则更为复杂。无人艇不仅要避免与海洋环境中动静态障碍物发生碰撞,而且要避免与无人艇之间发生碰撞,防止多个无人艇可能因为选择同一个目标点而产生冲突的问题。
技术实现思路
1、本发明所要解决的技术问题是针对上述现有技术的不足,提供一种基于近端策略优化的多无人艇深度强化学习协同导航方法,通过引入考虑无人艇与障碍物发生碰撞情况以及无人艇与其余的无人艇发生碰撞情况的差分奖励,解决了多个无人艇可能因为选择同一个目标点而产生冲突的问题,从而可以引导多个无人艇通过合作在避碰避障的前提下实现多目标导航。
2、为实现上述技术目的,本发明采取的技术方案为:
3、一种基于近端策略优化的多无人艇深度强化学习协同导航方法,包括:
4、步骤1、建立无人艇水平面运动的运动学模型及动力学模型;
5、步骤2、将多无人艇多目标导航问题建模为马尔科夫决策过程并确定单个无人艇的状态空间以及动作空间;
6、步骤3、根据多无人艇多目标导航的目标,建立考虑无人艇与障碍物发生碰撞情况以及无人艇与其余的无人艇发生碰撞情况的差分奖励函数;
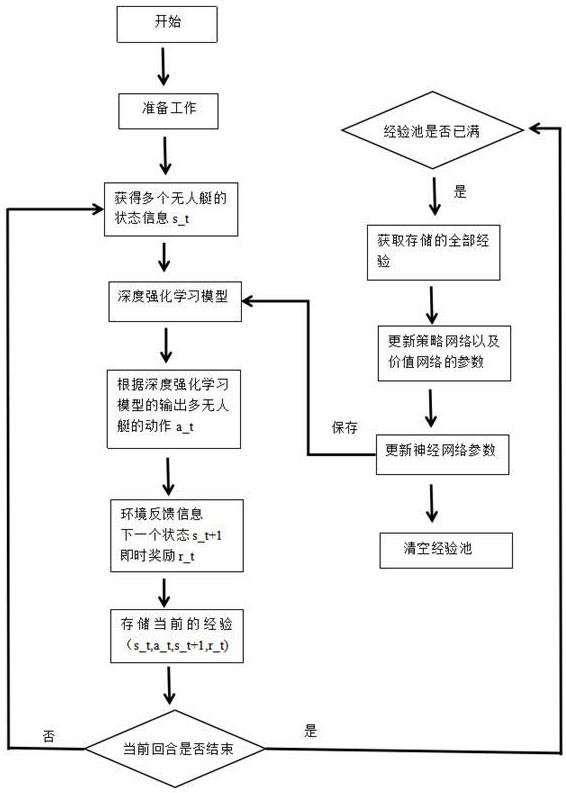
7、步骤4、基于步骤1-3,获取多个无人艇的状态信息,输入多智能体深度强化学习模型,结合多智能体近端策略优化算法,得到多个无人艇的动作;
8、步骤5、采用训练后的多智能体深度强化学习模型进行多无人艇多目标导航。
9、为优化上述技术方案,采取的具体措施还包括:
10、上述步骤1建立如下无人艇的三自由度水平面动力学模型:
11、;
12、所述步骤1建立如下无人艇的三自由度水平面运动学模型:
13、;
14、;
15、;
16、是加速度矢量,其中是激荡加速度、是摇摆加速度、是角加速度;
17、表示控制无人艇的力,表示控制无人艇的力矩;
18、[uc,wc]表示在坐标系b下的洋流的速度,[vx,vy]表示在坐标系c下的洋流速度,表示从坐标系b到坐标系c的旋转矩阵,其中c是惯性坐标系,b是以船体为固定框架定义的坐标系;
19、[u,w,r]是没有考虑洋流影响的速度向量,其中u表示激荡速度,w表示摇摆速度,r表示角速度;
20、[ur,wr]表示考虑洋流影响之后的相对速度向量,其中ur表示是艇的相对激荡速度,wr表示艇的相对摇摆速度;
21、分别表示水平方向的速度、垂直方向的速度,表示角速度,表示航向角。
22、上述的步骤2确定的单个无人艇的状态空间如下:
23、;
24、式中xi,yi表示无人艇i的横纵位置;表示航向角,ui表示无人艇的激荡速度,wi表示无人艇的摇摆速度,ri表示无人艇i的角速度,aui表示无人艇i的激荡加速度,awi表示无人艇i的摇摆加速度,ari表示无人艇i的角加速度,表示无人艇i相对于目标点的距离,无人艇i相对于其余无人艇的距离。
25、上述的步骤2确定的单个无人艇的动作空间如下:
26、;
27、tport,tstdb表示作用在艇左舷、右舷上的推力。
28、上述的步骤3建立的差分奖励函数为:
29、;
30、其中,r_o_collide表示无人艇与障碍物发生碰撞的情况,无人艇i与障碍物发生碰撞时r_o_collide为-1,其余的情况r_o_collide为0;
31、r_u_collide表示无人艇与其余的无人艇发生碰撞的情况,无人艇i与其余的无人艇发生碰撞时r_u_collide为-1,其余情况r_u_collide为0;
32、;
33、表示目标点1,表示目标点2,表示目标点3;
34、表示在时刻t无人艇1,表示在时刻t无人艇2;
35、表示在时刻t无人艇3,表示在时刻t+1无人艇1;
36、表示在时刻t+1无人艇2,表示在时刻t+1无人艇3;
37、表示在时刻t,三个无人艇中距离目标点1最近的距离;
38、表示在时刻t,三个无人艇中距离目标点2最近的距离;
39、表示在时刻t,三个无人艇中距离目标点3最近的距离;
40、表示、、这三个距离之和;
41、表示在时刻t+1,三个无人艇中距离目标点1最近的距离;
42、表示在时刻t+1,三个无人艇中距离目标点2最近的距离;
43、表示在时刻t+1,三个无人艇中距离目标点3最近的距离;
44、表示、、这三个距离之和;
45、表示在时刻t的差分奖励。
46、上述的步骤4包括:
47、步骤41、采用仿真环境生成多无人艇的状态向量,包括多个无人艇的出发点、多个目标点以及多无人艇的速度信息;
48、步骤42、将多无人艇的状态向量输入到多智能体深度强化学习模型的策略网络中,得到多无人艇的动作向量,对于仿真环境生成的多无人艇的状态向量是基于步骤2中的状态空间进行采样得到的,对于多无人艇的动作向量是基于步骤2中的动作空间进行采样得到的;
49、步骤43、将多无人艇的动作向量送给仿真环境,仿真环境基于步骤3建立的差分奖励函数、步骤1中模型返回奖励以及多无人艇执行动作向量之后的下一个时刻状态向量,返回步骤42,直到一个与环境交互回合结束,将本回合中产生的当前时刻状态,奖励值,动作,下一个时刻状态数据存储到经验池中;
50、步骤44、重复执行步骤41-步骤43直到经验池已满;
51、步骤45、从经验池中采样所有回合数据,基于多智能体近端策略优化算法更新多智能体深度强化学习模型的策略网络以及价值网络;
52、步骤46、清空经验池;
53、步骤47、重复步骤41-步骤46,直至达到最大训练回合数,完成对多智能体深度强化学习模型的策略网络以及价值网络的训练,得到训练后的多智能体深度强化学习模型。
54、上述的步骤41的具体过程为:调用仿真环境的reset方法,得到n个无人艇的出发点、n个无人艇要到达的目标点、n个无人艇初始的激荡速度、摇摆速度、角速度、n个无人艇的激荡加速度、摇摆加速度、角加速度,得到多无人艇的状态向量。
55、上述的步骤43的具体过程为:多无人艇的动作向量送给仿真环境后,仿真环境根据无人艇的动作向量以及步骤1中的数学模型,计算出无人艇的激荡加速度、摇摆加速度、角加速度,基于计算得到的加速度,进一步计算出激荡速度、摇摆速度、角速度,进一步计算出艇的位移以及偏航的角度;
56、基于艇的位移以及偏航的角度,仿真环境返回给多无人艇下一时刻的状态向量;
57、基于艇的位置,以及在步骤3建立的差分奖励函数,返回奖励值;
58、采用下一个时刻的状态向量返回执行步骤42,直到一个与环境交互回合结束;
59、将上述过程中的当前时刻状态,奖励值,动作,下一时刻的状态存储到经验池中。
60、上述的步骤45基于多智能体近端策略优化算法训练两个独立的网络,分别为参数是θ的策略网络和参数为的价值网络,其对所有同构的智能体共享网络权重;
61、策略网络由多层全连接层组成,用于将无人艇i的局部观测si 映射至连续动作空间的分布;
62、策略网络的损失函数为:
63、;
64、其中b表示批处理数,n是智能体,即无人艇的数量;表示优势函数;表示参数为θ的策略网络,表示参数没更新之前的策略网络,是固定常数,表示在时刻k智能体采取的动作,表示在时刻k智能体所处的状态,clip表示裁剪,具体如下:
65、;
66、价值网络由多层全连接层组成,用于将全局状态映射至状态价值的估计;
67、价值网络的损失函数为:
68、;
69、其中表示参数为的价值网络,表示参数没更新之前的价值网络,表示折扣累积奖励。
70、上述的步骤5具体包括:
71、(1)将多个无人艇的状态向量输入到训练后的多智能体深度强化学习模型中,得到无人艇的最优动作;
72、(2)执行无人艇的最优动作,得到一个新的多个无人艇的状态向量,返回(1),直到多个无人艇以最优的路径到达多个目标点。
73、本发明具有以下有益效果:
74、本发明建立无人艇的动力学模型和运动学模型;将水面多无人艇路径规划问题转换为马尔可夫决策过程;调用仿真环境的reset方法,得到n个无人艇的出发点、n个无人艇要到达的目标点、n个无人艇初始的激荡速度、摇摆速度、角速度、n个无人艇的激荡加速度、摇摆加速度、角加速度,得到多无人艇的状态向量;将状态向量输入到策略网络中,输出最优的动作值,最后将最优的动作值发送给多个无人艇去执行;将无人艇与环境交互过程中的时刻t的状态,奖励,动作,时刻t+1的状态放到经验池中进行存储;当经验池满了的时候,从经验池中采样数据,对策略网络和价值网络进行训练,更新策略网络以及价值网络的参数;清空经验池。重复上述过程直到达到最大训练回合数,完成对策略网络以及价值网络的训练;对训练好的深度强化学习模型进行测试,重新获取一个多无人艇的状态向量,输入到训练好的策略网络中,得到多无人艇的最优的动作,执行最优的动作,指导多无人艇实现多目标导航。
75、一方面,本发明设计了一种考虑无人艇与障碍物发生碰撞情况以及无人艇与其余的无人艇发生碰撞情况的差分奖励,解决了多个无人艇可能因为选择同一个目标点而产生冲突的问题,从而可以引导多个无人艇通过合作在避碰避障的前提下以最短的路径实现多目标导航。
76、另一方面,本发明将深度强化学习算法多智能体近端策略优化应用到多无人艇的多目标导航问题上,这种基于深度强化学习的控制方法不用对无人艇的动力学和环境干扰进行人工显示建模,并且通过参考航向角、位置信息、速度信息等生成状态值,能够在与环境交互过程中自主隐式建模环境干扰并学习到最优的控制策略,从而可以提高无人艇导航的准确性。
- 还没有人留言评论。精彩留言会获得点赞!