一种ROS的相机和激光雷达融合目标检测方法
本发明涉及传感器融合目标检测,尤其涉及一种ros的相机和激光雷达融合目标检测方法。
背景技术:
1、随着人工智能技术的飞速发展,互联网、通信技术的成熟。智能驾驶逐渐成为了未来汽车发展的趋势。智能驾驶的关键技术主要有感知、决策和规划三大方面,其中环境感知是自动驾驶技术的基础,目的在于探测和识别周围的道路、车辆、障碍物、交通信号灯等,是智能车辆的关键一环。智能车辆基于单一传感器在道路宽阔、光照充足、视野开阔等场景下目标检测性能优越,但单一传感器在光照强度低、环境复杂、目标多等场景下会出现较高误检、漏检率。而且受限于传感器自身的特点,相机无法准确得到目标的位置信息,激光雷达无法获取目标纹理信息,所以基于相机和雷达融合的目标检测实现了两种传感器的优势互补。目前主要有:基于数据层面相机和激光雷达融合的方法,基于特征层面相机和激光雷达融合的方法。
2、上述两种方法目前均存在一些问题,其中基于数据层面的融合方法需要处理大量的图像和点云数据,且点云和图像数据很难统一为同一维度。基于特征层面的融合方法检测精度较为依赖对图像及点云数据中目标特征提取的准确度。鉴于此,我们提出一种ros的相机和激光雷达融合目标检测方法。
技术实现思路
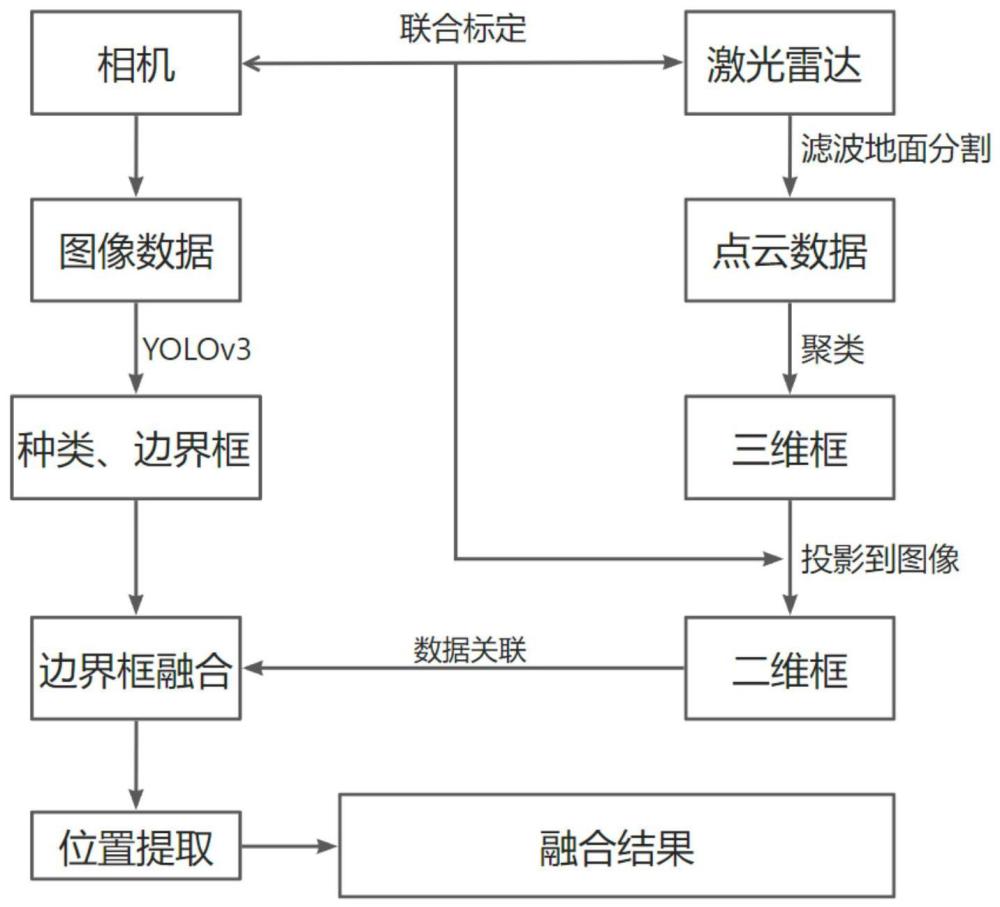
1、本发明的目的在于克服现有技术的不足,适应现实需要,提供一种低成本并可精确实现相机和激光雷达融合的ros的相机和激光雷达融合目标检测方法,融合方法使用深度学习模型和聚类的方法分别处理图像点云数据并得到目标检测结果,通过投影的方法从而进行融合,得到目标类别和位置信息。
2、为了实现本发明的目的,本发明所采用的技术方案为:
3、一种ros的相机和激光雷达融合目标检测方法,包括以下步骤:
4、s1、利用工业相机和激光雷达获取图像和点云数据,进行图像点云数据时间匹配,创建融合目标检测数据集;
5、s2、对相机激光雷达进行标定,求取相机到激光雷达的转换参数;
6、s3、将图像数据集输入yolov3模型进行处理得到目标类别及二维检测框;对点云数据进行地面和无关点云滤除,然后进行基于动态阈值的聚类处理,得到目标距离信息并拟合出目标三维检测框;
7、s4、利用步骤s2中已求得的转换参数将点云三维框投影到二维图像上,并与yolov3模型已检测到的目标二维框建立关联,然后根据权重和框坐标计算目标检测的融合框;
8、s5、在ros操作系统将各个步骤编写为节点并联立起来实现融合的目标检测。
9、本发明可低成本、精确地实现相机和激光雷达融合的目标检测,融合方法使用深度学习模型和聚类的方法分别处理图像点云数据并得到目标检测结果,通过投影的方法从而进行融合,得到目标类别和位置信息,而基于ros的方法可方便移植到嵌入式设备和车载平台上,解决了现有技术中传感器融合方法较为依赖硬件平台的性能且会增加车辆制造成本。
10、优选地,与步骤s1中的时间同步,在ros系统中分别订阅不同的需要融合的传感器的话题,通过ros中的timesynchronizer程序统一接收多个话题,只有当所有的话题都有相同的时间戳时,才会产生一个同步结果的回调函数,在回调函数里生成同步时间后的数据。
11、优选地,步骤s2具体方法如下:
12、s21、求取相机和激光雷达之间的转换矩阵参数,首先设空间一点p在激光雷达坐标系为(xl,yl,zl),在相机坐标系坐标为(xc,yc,zc),在图像坐标系标为(xp,yp),在像素坐标系坐标为(u,v);其中,激光雷达坐标系到相机坐标系通过式(1)转换:
13、
14、s22、rcl为激光雷达坐标系转换到相机坐标系的旋转矩阵,tcl为激光雷达坐标系转换到相机坐标系的平移向量;其中,相机坐标系和图像坐标系通过式(2)转换;
15、式(2)中的f为相机焦距:
16、
17、图像坐标系到像素坐标系之间通过式(3)转换,其中,dx,dy为x,y轴的像素转换单位,u0,v0为投影屏幕中心相对于光轴的偏移:
18、
19、s23、联立式(1)、(2)、(3)可将激光雷达坐标系和相机坐标系转换关系变换为:
20、
21、s24、将式(4)整理可得:
22、
23、其中,为相机的内参矩阵,为相机和激光雷达坐标转换的外参矩阵,则激光雷达三维坐标系下的点(xl,yl,zl)转换为像素坐标下点(u,v)的问题,转化为求取相机内外参数的过程。
24、优选地,步骤s3具体方法如下:
25、s31、对于图像的处理,直接调用opencv中的yolov3模型,在检测时加载yolov3在公开数据集上的预训练权重;
26、s32、对于点云首先进行地面分割,然后进行聚类处理;基于传统的欧式聚类,加入动态的阈值进行处理;选择车前方5米内点云密度最高的两点,初始阈值通过式(6)进行计算,x1,y1,y1;y2;分别为两点的坐标:
27、
28、点云的间隔距离随着障碍物越远而越大,则距离阈值由式(7)计算,式中e为补偿因子,di为初始聚类阈值,d为该点云至激光雷达中心的距离,随着距离增加,聚类阈值需要随之增加,补偿因子e由点云的密度进行确定:
29、dj=ed+di (7);
30、给聚类后的每个类添加一个最小外接长方体,计算每个聚类的外接长方体的体积,将体积过小或体积过大的类删掉,然后根据最小外接立方体计算三个约束条件(长宽比),(长高比),(宽高比),根据待检测目标的类别设定约束条件的范围,对聚类检测的目标进行筛选。
31、优选地,步骤s4具体方法如下:
32、s41、当前障碍物在点云和图像上均被检测,且激光雷达的三维框已经投影到图像上,则可以得到了障碍物的点云和图像识别的二维框的左上角和右下角角点坐标如下所示:
33、boundingbox(lidar)=(xl1,yl1,xl2,yl2) (7);
34、boundingbox(camera)=(xc1,yc1,xc2,yc2) (8);
35、s42、由角点坐标可通过式(9)式(10)计算相机和激光雷达检测框面积:
36、scamera=(xc2-xc1)*(yc2-yc1) (9);
37、slidar=(xl2-xl1)*(yl2-yl1) (10);
38、s43、iou(交并比)计算如下:
39、
40、s44、设置iou的阈值,在阈值范围内的点云和相机框则认为是统一物体的检测框;
41、s45、当出现多个检测框重叠的情况时,需要进一步筛选,设图像某个检测框的左上角及右下角坐标为:(acj,bcj),(ccj,dcj);点云检测框投影到图像上的检测框左上角及右下角坐标为:(alj,blj),(clj,dlj),定义关联比例为:
42、
43、式中j为第j个目标检测框,i为重叠的任意两框的交并比的值,对上一步保留的前三个匹配的i结果进行r值的计算,r值最大的一组重叠框认为是在点云和图像中检测到同一个目标,进行检测框的融合;
44、s46、关联后通过下式进行边界框融合:
45、
46、
47、
48、
49、式中xc1,xc2,yc1,yc2即关联后相机检测对象框的角点坐标;xl1,xl2,yl1,yl2即激光雷达检测对象框的角点坐标;xf1,xf2,yf1,yf2即目标融合框的角点坐标;p1,p2分别为相机检测到的目标置信度和激光雷达检测到的目标置信度,p1可由yolov3算法检测直接得出,p2由激光雷达检测框和相机检测框的面积之比和调整系数得到。
50、与现有技术相比,本发明的有益效果在于:
51、本发明可低成本、精确地实现相机和激光雷达融合的目标检测,融合方法使用深度学习模型和聚类的方法分别处理图像点云数据并得到目标检测结果,通过投影的方法从而进行融合,得到目标类别和位置信息,而基于ros的方法可方便移植到嵌入式设备和车载平台上,解决了现有技术中传感器融合方法较为依赖硬件平台的性能且会增加车辆制造成本。
- 还没有人留言评论。精彩留言会获得点赞!