一种冷萃、提纯、浓缩方法与流程
本发明涉及化学处理,尤其涉及一种冷萃、提纯、浓缩方法。
背景技术:
1、在当今科学和工程领域,处理和纯化化学物质、生物样本或其他复杂混合物的需求与日俱增。这些需求涵盖了从新药研发到环境监测等各个领域。冷萃、提纯和浓缩方法是在这些领域中必不可少的实验操作,它们允许科学家和工程师从原始样本中分离和获得纯度高、浓度适当的目标物质。然而,传统的冷萃、提纯和浓缩方法存在一些问题,例如操作的复杂性、耗时性、资源浪费以及实验的一致性和可重复性问题。随着技术的不断发展,智能化和自动化的趋势已经融入了许多科学实验室和工业过程。在这一背景下,寻求一种智能化的方法来改进冷萃、提纯和浓缩过程变得至关重要。这种方法的目标是通过利用先进的技术,如传感器、数据分析和机器学习,来提高实验过程的效率、精确性和可控性;因此,发明出一种冷萃、提纯、浓缩方法变得尤为重要。
2、现有的冷萃、提纯、浓缩方法无法进行全自动化的杂质检测,增加人工干预的需求,降低检测的可靠性和精确性;此外,现有的冷萃、提纯、浓缩方法冷萃提取效率低下,无法保证提取物的高纯度和高收率;为此,我们提出一种冷萃、提纯、浓缩方法。
技术实现思路
1、本发明的目的是为了解决现有技术中存在的缺陷,而提出的一种冷萃、提纯、浓缩方法。
2、为了实现上述目的,本发明采用了如下技术方案:
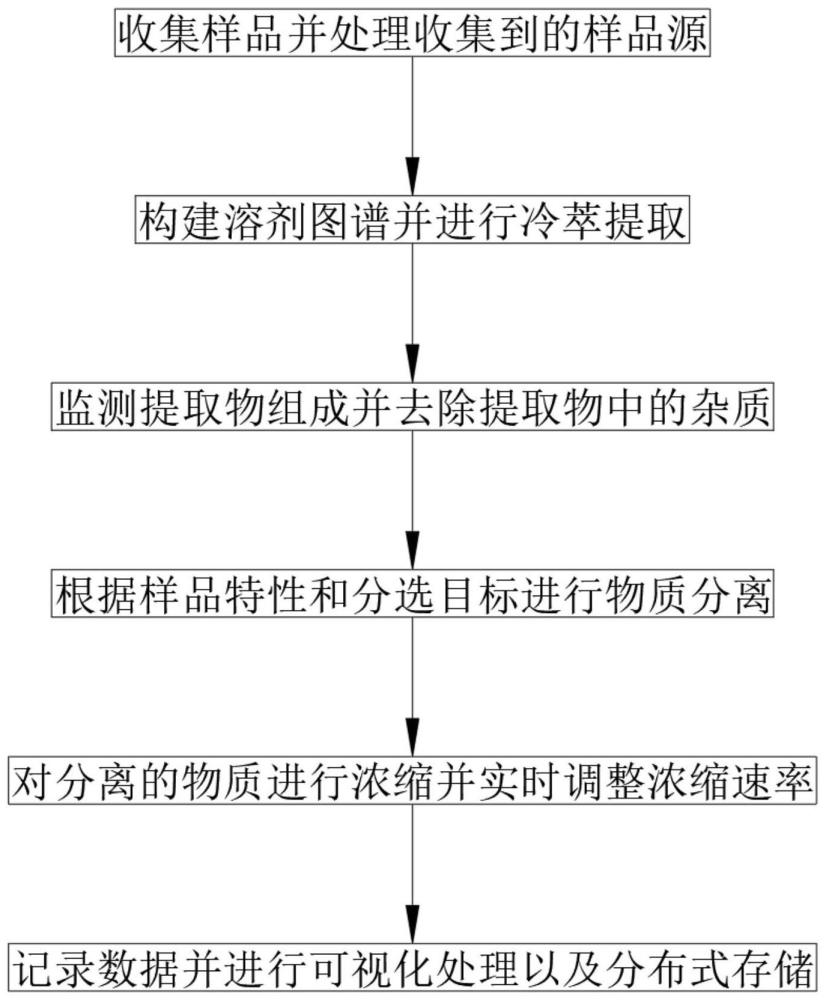
3、一种冷萃、提纯、浓缩方法,该冷萃、提纯以及浓缩方法具体步骤如下:
4、(1)收集样品并处理收集到的样品源;
5、(2)构建溶剂图谱并进行冷萃提取;
6、(3)监测提取物组成并去除提取物中的杂质;
7、(4)根据样品特性和分选目标进行物质分离;
8、(5)对分离的物质进行浓缩并实时调整浓缩速率;
9、(6)记录数据并进行可视化处理以及分布式存储。
10、作为本发明的进一步方案,步骤(1)中所述样品源处理具体步骤如下:
11、步骤一:根据研究目的或分析要求选择合适的样品源,并采集足够数量的样品,并依据各组样品信息为对应样品设置唯一标识,建立详细的样品记录,记录每组样品的处理步骤和实验条件;
12、步骤二:去除固体样品不需要的部分,并将研磨成粉末,依据液体样品的分析范围,将其进行稀释或浓缩,之后记录各组处理后的样品信息并保存。
13、作为本发明的进一步方案,步骤(2)中所述溶剂图谱具体构建步骤如下:
14、步骤ⅰ:从专家知识、互联网以及化学资料库中收集与提取溶剂相关的各种知识和信息,并对收集到的提取溶剂知识进行分类、去重以及筛选处理,通过nlp技术识别和抽取出处理后的提取溶剂知识中的实体;
15、步骤ⅱ:从相关的知识信息中提取每个实体的对应属性,并建立实体之间的关系,形成溶剂图谱的连接,采用三元组的形式将实体、属性和关系处理成对应图状结构,选择合适的图数据库来存储和管理溶剂图谱,并对溶剂图谱进行不断地更新和维护。
16、作为本发明的进一步方案,步骤(2)中所述冷萃提取具体步骤如下:
17、步骤1:将经过准备的样品装入提取器中,再根据样品特性和提取需求计算溶剂图谱中各组溶剂的适用性得分,并选择适用性得分最高的溶剂作为目标物质的提取溶剂;
18、步骤2:实时监测提取器中的温度,并根据预设条件自动控制冷却装置,并通过调整搅拌速度和时间将样品与提取溶剂混合均匀,再根据样品的特性和提取需求调整提取的持续时间,当冷萃提取完成后,停止提取器的操作并回收提取溶剂,并将提取物转移至准备好的容器中。
19、作为本发明的进一步方案,步骤1中所述适用性得分具体计算公式如下:
20、s=∑(|pi(溶剂)-pi(样品)|/δr)
21、(1)
22、式中,s代表适用性得分;pi(溶剂)代表提取溶剂的相对极性;pi(样品)代表样品的相对极性;δr代表不同溶剂的相对极性差异。
23、作为本发明的进一步方案,步骤(5)中所述提取物杂质具体去除步骤如下:
24、步骤①:采集提取物图像信息,提取图像特征并在不同尺度的特征图上执行目标检测,将检测出的特征送入双向特征金字塔,进行特征融合,再将融合结果进行分类回归以输出检测框,通过多组注意力层从不同角度对历史数据进行线性变换获取多组特征,将多组注意力头提取出的特征进行融合以获取多模态特征数据集;
25、步骤②:将多模态特征数据集按照预设比例分为训练集、验证集和测试集,构建一组杂质检测模型并根据原有设置初始化该杂质检测模型各项参数,之后使用训练集进行模型训练,在每次迭代中将一组训练数据输入模型,通过交叉熵损失函数计算此次杂质检测模型输出结果损失值,若损失值不满足预设要求,通过反向传播算法来更新权重和参数;
26、步骤③:通过验证集来监控杂质检测模型在验证集上的性能,若性能不再提升或开始下降,则停止训练,之后使用测试集来评估最终训练好的模型的性能,再将训练好的模型部署到相关平台中;
27、步骤④:将检测框信息输入杂质检测模型中,各组信息从杂质检测模型输入层经过模型的各隐藏层进行处理后,通过各层之间的权重和激活函数进行逐层传递,之后输出层输出一组或多组杂质的概率分布;
28、步骤⑤:依据各组预测的杂质结果,使用合适的杂质去除方法去除杂质,并将固体杂质进行回收,通过实时监测和数据记录来评估提纯效果,若提纯未达到预期目标,则发出警报,或根据历史数据进行调整,之后逐渐添加溶剂将提取物溶解或稀释,使用实时传感器监测提取物的浓度,若浓度达到所需水平,则停止溶剂添加。
29、作为本发明的进一步方案,步骤(5)中所述浓缩速率调整具体步骤如下:
30、第一步:设置初始浓缩条件,之后将目标物质通过旋转蒸发器进行液化处理,再将液化后的目标物质通过进料管道输入到浓缩设备中进行浓缩,并实时采集各组参数信息;
31、第二步:从数据库中收集历史浓缩数据,之后将历史浓缩数据分成不同的健康状态类别,并依据分类结果对各组历史浓缩数据进行标注,对历史浓缩数据进行标准化处理后,将各组数据整合归纳成样本数据集,之后按照预设阈值将样本数据集划分为两组特征子集;
32、第三步:随机选择一组特征子集,重复进行特征选择和数据集分割,直至决策树的深度达到预定值,将叶子节点的标签确定为该节点中样本数量最多的类别,之后通过递归分裂和叶子节点标签确定,构建出一个完整的决策树,将生成的多组决策树组成随机森林模型,对于每一组数据,选取任意一个子集作为测试集,其余子集作为训练集,训练随机森林模型后,通过测试集进行检测;
33、第四步:统计检测结果的损失值,再将测试集更换为另一子集,再取剩余子集作为训练集,再次计算损失值,直至对所有数据都进行一次预测,通过选取损失值最小时对应的组合参数作为数据区间内最优的参数并替换随机森林模型原有参数;
34、第五步:该随机森林模型接收实时采集的参数信息后,从随机森林模型的根节点开始,根据参数信息的特征条件逐步遍历树的分支,直到达到叶子节点,并将该叶子节点的标签作为预测结果并输出,同时依据预测结果自动调整浓缩速率快慢。
35、作为本发明的进一步方案,步骤(6)中所述分布式存储具体步骤如下:
36、第1步:按照预设的时间区间对各组处理数据进行分割,以获形成多组数据块,之后通过哈希算法生成各组数据块的标识,收集各组节点信息;
37、第2步:获取数据块划分规则以及节点负载情况,并通过负载均衡算法选择合适的节点来存储每组数据块,数据块存储完成后,根据系统的要求和可用资源进行配置复制规定数量的数据块到多组节点上;
38、第3步:当节点存储的数据发生变化时,通过数据同步算法将数据更新从一个节点传播到其他节点,之后自动检测节点运行情况,并对故障节点进行数据迁移或修复。
39、相比于现有技术,本发明的有益效果在于:
40、1、该冷萃、提纯、浓缩方法通过采集提取物图像信息,提取图像特征并在不同尺度的特征图上执行目标检测,将检测出的特征送入双向特征金字塔,进行特征融合,再将融合结果进行分类回归以输出检测框,通过多组注意力层从不同角度对历史数据进行线性变换获取多组特征,构建杂质检测模型并通过提取出的特征数据对模型进行训练以及测试,将检测框信息输入杂质检测模型中输出一组或多组杂质的概率分布,依据各组预测的杂质结果,使用合适的杂质去除方法去除杂质,并将固体杂质进行回收,通过实时监测和数据记录来评估提纯效果,若提纯未达到预期目标,则发出警报,或根据历史数据进行调整,之后逐渐添加溶剂将提取物溶解或稀释,使用实时传感器监测提取物的浓度,若浓度达到所需水平,则停止溶剂添加,能够实现全自动化的杂质检测,减少人工干预的需求,提高检测的可靠性和精确性,有助于建立历史数据的数据库,用于进一步的分析和改进提纯过程。
41、2、该冷萃、提纯、浓缩方法通过从专家知识、互联网以及化学资料库中收集与提取溶剂相关的各种知识和信息,并对收集到的提取溶剂知识进行分类、去重以及筛选处理,通过nlp技术识别和抽取出处理后的提取溶剂知识中的实体,从相关的知识信息中提取每个实体的对应属性,并建立实体之间的关系,形成溶剂图谱的连接,采用三元组的形式将实体、属性和关系处理成对应图状结构,选择合适的图数据库来存储和管理溶剂图谱,并对溶剂图谱进行不断地更新和维护,将经过准备的样品装入提取器中,再根据样品特性和提取需求计算溶剂图谱中各组溶剂的适用性得分,并选择适用性得分最高的溶剂作为目标物质的提取溶剂进行冷萃提取,有助于提高提取效率,保证提取物的高纯度和高收率,减少试错成本,提高实验的效率。
- 还没有人留言评论。精彩留言会获得点赞!