一种面向多源域不平衡数据的滚动轴承跨域故障诊断方法
本发明涉及故障诊断,尤其涉及一种面向多源域不平衡数据的滚动轴承跨域故障诊断方法。
背景技术:
1、旋转机械在航空航天、交通运输、石油化工等行业中发挥着重要作用。在旋转机械的众多部件中,滚动轴承是一个重要的部件。由于旋转设备运行条件的复杂性,滚动轴承常在相对恶劣的环境下运行,一旦发生事故,可能造成严重的财产损失,甚至威胁人员生命安全。因此,对滚动轴承进行故障诊断是十分必要的。旋转机械由于运行条件的变化、设备的磨损退化等原因,往往在不同的工况下运行,这阻碍了基于深度学习的故障诊断方法在实际工程中的应用。由可变工况引起的分布差异通常会导致深度诊断模型在其有效性方面显著恶化。因此,领域偏移是开发准确、可靠的故障诊断方法的一个关键挑战。最近,基于领域泛化的方法被设计用来解决跨域故障诊断问题,其核心思想是通过匹配不同领域样本在高层子空间中的分布,并提取域不变特征来消除跨域分布差异,这些方法已经被证实能够在跨域故障诊断中取得较好的性能。然而,这些方法大多假设用于模型训练的故障数据集中各个故障类别的样本数量相同,由于实际采集数据时往往会受到多种限制,这种假设并不一定成立,即存在域内标签不平衡和跨域标签分布差异问题。多源域故障类别不平衡问题会导致现有领域泛化方法诊断精度低和泛化能力差。
2、针对上述问题,本发明针对性地提出一种面向多源域不平衡数据的滚动轴承跨域故障诊断方法。既解决了跨域潜在的巨大分布差异,同时可以处理多源域的数据不平衡问题。
技术实现思路
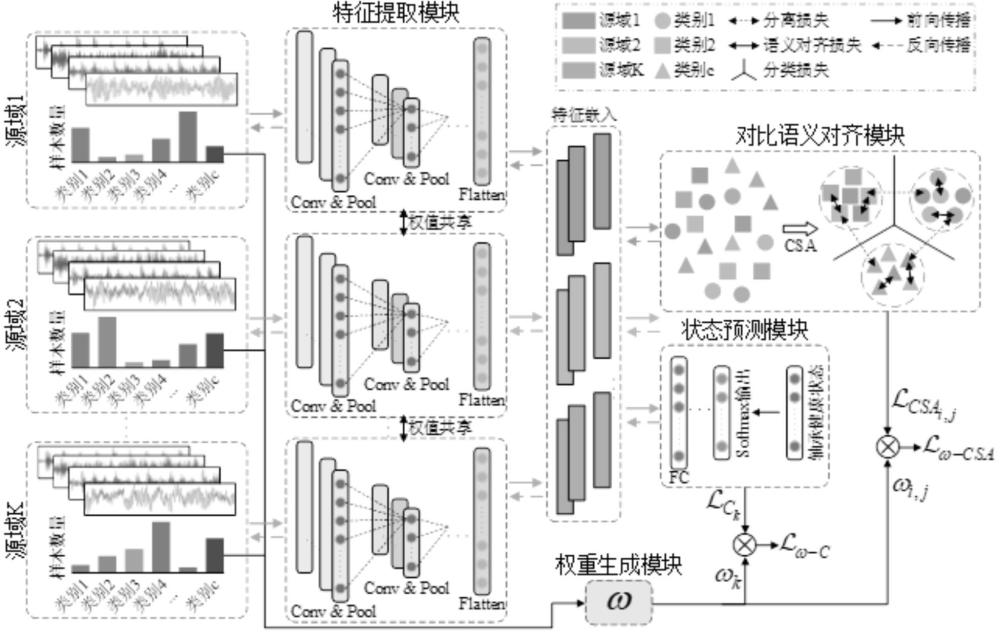
1、本发明提出了一种面向多源域不平衡数据的滚动轴承跨域故障诊断方法,其主要思想是既学习域不变特征,同时又鼓励从代表性不足的故障类别中学习。本发明主要基于四个模块实现。首先,采用特征提取模块从输入的原始振动信号中自动提取有效特征;然后,采用对比语义对齐模块最小化各个源域之间的分布差异,学习域不变特征;在此基础上,采用状态预测模块利用学习的嵌入特征预测轴承健康状态;最后,权重生成模块根据各个类别的样本数量分布生成权重,利用权重对分类和对比语义对齐损失加权,鼓励学习少数故障类别的特征。
2、本发明的技术方案如下:一种面向多源域不平衡数据的滚动轴承跨域故障诊断方法,建立一种跨域故障诊断模型;所述跨域故障诊断模型包括特征提取模块、状态预测模块、对比语义对齐模块和权重生成模块;
3、从第个源域样本集中采样个样本,构成样本集,代表第个源域中的第b个样本,第个源域中的第b个样本对应的标签,样本集经特征提取模块前向传播,得到嵌入特征;
4、将得到的嵌入特征经状态预测模块前向传播,得到预测输出;预测过程中最小化所有源域样本的分类损失;
5、所述对比语义对齐模块,用于促使特征提取模块学习域不变特征以抵抗未知域的分布偏移,根据特征提取模块提取的嵌入特征进行源域间特征的对比语义对齐,最小化来自不同源域但标签相同的样本嵌入特征分布之间的距离,最大化来自不同源域且标签不同的样本嵌入特征分布之间的距离;
6、
7、所述权重生成模块,根据每个类别的样本数量与其所在源域样本总数的比值倒数生成权重,通过权重对该类别的分类损失加权得到加权分类损失;将域和域中类别定义为域-类对,将分属于不同域中的相同类别的域-类对进行对齐;权重生成模块根据每个域-类对组合的样本数量与所有域-类对组合的样本总数的比值倒数生成权重,根据权重对该域-类对组合的对比语义对齐损失加权得到加权对比语义对齐损失;
8、根据加权分类损失和加权对比语义对齐损失的信息,以及上一迭代轮次的梯度信息,进行反向传播更新跨域故障诊断模型网络梯度,直到跨域故障诊断模型的准确度达到要求,得到最终的跨域故障诊断模型;
9、利用最终的跨域故障诊断模型中特征提取模块和状态预测模块进行跨域故障诊断。
10、所述特征提取模块采用多分支的孪生网络架构,每个分支对应一个特定源域;分支之间采取权值共享策略,孪生网络架构的所有分支共享相同的权重和偏置参数;在每个分支中,采用首层宽卷积核深度卷积神经网络,包括五个卷积层和五个最大值池化层;首层卷积层以外的其余各卷积层均采用3×1的卷积核;每层卷积操作后采用批量归一化和激活函数处理,再采用2×1的最大值池化;经过所有卷积层和最大池化层处理之后,进行整平操作,将提取的特征展平为一维特征嵌入,映射到嵌入空间。
11、所述状态预测模块包括两个全连接层、一个relu激活函数和一个softmax激活函数;首先,两个全连接层将特征提取模块提取的嵌入特征由嵌入空间映射到输出空间;然后,relu激活函数对输出空间中的特征进行非线性变换;最后,softmax激活函数对输出空间中的线性变换后的特征计算输入样本属于每个健康状态的概率,最终根据概率输出预测结果。
12、所述分类损失具体如下:
13、对于具有个源域,每个源域具有个健康状态的数据集,健康状态分类损失计算如下,
14、 (1)
15、其中,表示第个源域的健康状态分类损失,表示第个源域的样本个数,表示第个源域中第个样本在嵌入空间中的特征,表示状态预测模块,表示第个源域中第个样本的健康状态,表示用于训练状态预测模块的交叉熵损失函数;定义如下,
16、 (2)
17、其中,表示状态预测模块最后一层的输出向量,表示的第个元素,表示轴承健康状态标签,表示轴承健康状态个数,表示指示函数。
18、所述对比语义对齐损失包括语义对齐损失和分离损失;
19、所述语义对齐损失为最小化来自不同源域但标签相同的样本嵌入特征分布之间的距离;语义对齐损失定义如下,
20、 (3)
21、其中,表示第个源域中第个类别的样本集经过特征提取模块映射到嵌入空间中的嵌入特征;表示第个源域中第个类别的样本集经过特征提取模块映射到嵌入空间中的嵌入特征,表示轴承健康状态个数,表示嵌入特征的概率分布,表示嵌入特征和分布之间的距离度量;定义如下,
22、 (4)
23、其中,表示第个源域中第个类别的样本数量,表示第个源域中第个类别的样本数量,表示第个源域的第个类别中第个样本的嵌入特征,表示第个源域的第个类别中第个样本的嵌入特征,两个样本嵌入特征的距离,采用欧氏距离计算如下,
24、 (5)
25、其中,表示frobenius范数;
26、分离损失为最大化来自不同源域且标签不同的样本嵌入特征分布之间的距离;分离损失定义如下,
27、 (6)
28、其中,表示第个源域中第个类别的样本集在嵌入空间中的特征,表示第个源域中第个类别的样本集在嵌入空间中的特征,和是不同的故障类别,表示嵌入特征的概率分布,表示样本集和在嵌入空间中分布之间的相似性度量;对分布相似性增加一个惩罚,定义如下,
29、 (7)
30、其中,表示第个源域中第个类别的样本数量,分别表示第个源域中第个类别的样本数量,表示第个源域的第个类别中第个样本的嵌入特征,表示第个源域的第个类别中第个样本的嵌入特征,表示两个样本嵌入特征的相似性,采用欧氏距离计算如下,
31、 (8)
32、其中,表示frobenius范数,表示在嵌入空间中两个分布的分离程度,为惩罚项,表示取和中的较大值;对比语义对齐损失定义如下,
33、 (9)
34、其中,表示源域个数,和分别表示第个源域样本集和第个源域样本集,和是不同的源域,表示第个源域和第个源域之间的对比语义对齐损失;定义如下,
35、 (10)
36、其中,表示特征提取模块。
37、所述权重生成模块具体如下:
38、权重生成模块根据每个类别的样本数量与其所在源域样本总数的比值倒数生成权重,通过权重对该类别的分类损失加权得到加权分类损失;将域和域中类别定义为域-类对,将分属于不同域中的相同类别的域-类对进行对齐;权重生成模块根据每个域-类对组合的样本数量与所有域-类对组合的样本总数的比值倒数生成权重,根据权重对该域-类对组合的对比语义对齐损失加权得到加权对比语义对齐损失。
39、所述加权分类损失定义如下:
40、 (11)
41、其中,表示源域个数,表示第个源域的加权分类损失,表示健康状态个数,表示第个源域中第个类别的权重,表示第个源域中第个类别的分类损失,定义如下,
42、 (12)
43、 (13)
44、其中,表示在第个源域中,第个类别的样本数量与样本总数的比值,定义如下,
45、 (14)
46、所述加权对比语义对齐损失定义如下:
47、 (15)
48、其中,表示源域个数,表示第个源域和第个源域之间的加权对比语义对齐损失,定义如下,
49、 (16)
50、其中,表示健康状态个数,表示域-类对和之间的对比语义对齐损失, 表示域-类对和的组合被联合采样的权重,定义如下,
51、 (17)
52、其中,表示域-类对和组合的样本数量与所有域-类对组合的样本总数的比值,定义如下,
53、 (18)
54、其中,和分别表示第个源域和第个源域的样本总数,表示第个源域中第个样本的标签,表示第个源域中第个样本的标签,表示指示函数。
55、本发明的有益效果:为了实现准确预测,最小化所有源域样本的分类损失。为了学习域不变特征,最小化各个源域之间的对比语义对齐损失。设计了生成模块,促使特征提取模块和状态预测模块从代表性不足类别中学习,以鼓励从代表性不足的类别中学习。本发明在满足实际工程场景中存在多源域数据不平衡问题的前提下,既解决跨域潜在的巨大分布差异,同时可以处理多源域的数据不平衡问题,尽可能提高跨域故障诊断方法的诊断精度和泛化性能,以实现更加准确、可靠的滚动轴承故障诊断。
- 还没有人留言评论。精彩留言会获得点赞!