针对多目标柔性作业车间调度的含禁忌表的遗传与局部搜索算法的制作方法
本发明专利用于制订多目标柔性作业车间调度的生产调度计划。
背景技术:
柔性作业车间调度问题是传统作业车间调度问题的一般化,由于该情境下每个工序能够在多台机器上加工,因此问题的复杂性大大增加。现实生产中,生产调度又往往要同时优化多个目标,这无疑使问题的复杂性进一步加大。经典的遗传局部搜索算法被广泛应用于对于多目标柔性作业车间调度问题的求解,取得了不错的效果。然而,这种算法仍不够简洁高效,包括以析取图表示调度方案的方式。
技术实现要素:
本算法针对多目标柔性作业车间调度的遗传局部搜索算法,通过对编码的改进使算法更加简洁高效。本算法对传统遗传局部搜索算法的改进主要包括以下方面:第一,多目标柔性作业车间调度方案的编码方式的复杂性;第二,可行的解(调度方案)在经过交叉、变异操作后可能产生不可行的解(调度方案);第三,局部搜索可能作用于局部最优解,会产生无意义的搜索过程;第四,搜索过的解可能被重复搜索;第五,以加权法解决多目标问题时各目标函数的加权值不易确定;第六,一个解的邻域解数量非常多,占用计算时间过多;第七,已经产生的优良解(调度方案)可能在之后的迭代过程中被遗失。
本发明解决其技术问题所采用的技术方案是:第一,采用一种新的编码方式;第二,采用一种专门用于本编码方式的交叉算子和突变算子;第三,将局部最优解记录于禁忌表中,再次出现时直接进行遗传搜索;第四,将搜索过的邻域解加入禁忌表,再次出现时直接进行遗传搜索;第五,采用随机加权法为各目标函数赋加权值;第六,在局部搜索中,只随机选取每个当前解的部分邻域解进行检测;第七,设置精英组保存搜索过程中发现的非支配解。
本发明的有益效果:第一,简化了编码过程;第二,避免了可行的解(调度方案)经交叉和突变后出现不可行的解(调度方案);第三,避免了对局部最优解进行无意义的局部搜索;第四,避免了对搜索过的邻域解进行重复的局部搜索;第五,确定各目标函数加权值的过程变得十分简便;第六,避免了局部搜索占用过多的计算时间;第七,避免了非支配解的遗失。
附图说明
下面结合附图和实施例对本发明型进一步说明。
图1是柔性作业车间调度的示例图。
图2是编码结构的示意图。
图3是机器选择部分编码方式的示例图。
图4是工序序列部分编码方式的示例图。
图5是解码过程的示例图。
图6是非支配解的示意图。
图7是遗传搜索和局部搜索与本算法的比较图。
图8是两点交叉算子示意图。
图9是基于工序编码交叉算子的示例图。
图10是机器选择部分编码的突变算子的示例图。
图11是工序序列部分编码的突变算子的示例图。
图12是含禁忌表的遗传与局部搜索算法的流程的示意图
图13是算法详细流程的示意图。
具体实施方式
一、柔性作业车间调度问题
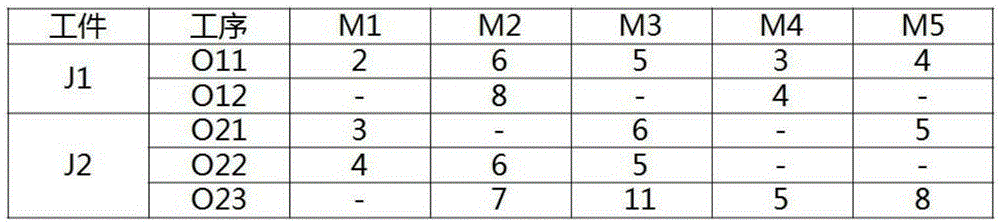
在传统的作业车间调度问题中,每个工序只能在唯一一台机器上加工。而对于柔性作业车间调度问题而言,每个工序能够在多台机器上加工,这从图1的示例中可以看出(图1中的“-”表示该机器无法加工此工序)。这种改变使问题模型更加符合实际的生产情境,但同时也加大了问题的复杂性。
二、生产信息的表示
1.n个工件:J1,J2,…,Jn。
2.m台机器:M1,M2,…,Mm。
3.工件Ji的第j道工序:Oij。
4.工序集W:将J1-Jn上的工序依次排列,
W={w1,w2,…},
(1)
“w”的下标为工序集中每个工序的编号,从1开始依次编号。
5.工件集中工序wi在第j台机器的加工时间:tij。
6.工序的机器集Mij:可加工工序Oij的机器的集合
Mij={m1,m2,…},
(2)
“m”的下标为机器集中每台机器的编号,从1开始依次编号。
7.全部工件的全部加工时间T:
每一行依次表示工序集(式(1))中的工序,每一列以此表示机器集(式(2))中的机器。如果工序i无法在机器j上加工,则tij=-1。
三、编码方式
如图2所示的编码结构,本编码方式对每个解的编码分为两个部分,分别为机器选择部分和工序序列部分。
1.机器选择部分的编码
如图3所示的编码示例(生产信息对应图1),编码的每一位依次对应工序集(式(1))上的工序,编码的每一位的值为加工该工序的机器在机器集(式(2))中的编号。
2.工序序列部分的编码
如图4所示的编码示例(生产信息对应图1),每个工件的每个工序都用此工件的编号表示,以同一编码值出现的顺序依次表示每个工件的各工序,编码的顺序表示各工序的加工顺序。
3.解码过程
如图5所示的解码示例(生产信息对应图1),首先将工序序列部分的工序依次在机器选组部分找到加工机器,然后将这些工序依次加入对应 机器,即可得到生产调度方案。
四、非支配解
对于最大化n个目标函数f1(x),f2(x),…,fn(x),当两个解x、y满足:
则称解y支配解x。
如果一个解不被多目标优化问题的任何其他解支配,那么这个解被称为一个非支配解。
对于两目标优化问题(最大化目标函数)的非支配解可以被图6形象地描述出来。
五、精英组
通过将每一代中的非支配解加入精英组,并在每一代更新精英组(即删掉加入新的解后精英组中不再是非支配解的解)。
六、随机加权法
对于多目标问题,我们采用随机加权法为每个目标函数赋予加权值,从而将多目标问题转化为单目标问题。对于每个解,随机加权法的加权值确定方式如下:
randomi为随机产生的数,wi满足:
则每个解适应度函数为:
七、禁忌表
禁忌表在禁忌搜索算法中被用于记录局部搜索中已搜索过的解,以避免重复搜索,同时禁忌表会在局部搜索的每一次迭代后更新。本算法引入禁忌表,用它记录局部搜索过程中搜索到的局部最优解和搜索过的邻域解。当禁忌表中记录的解再次出现在种群中时,直接进行遗传搜索而不再进行局部搜索。
八、遗传组
本算法中设置遗传组,用于暂时储存将要进行遗传搜索的解。
九、遗传算法和局部搜索与本算法的比较
如图7,以最大化目标函数为例。
1.局部搜索
如图7-(a),局部搜索仅仅能够搜索每个解周围的解,对于处于“山顶”的点则无法继续搜索更优的点,即陷入局部最优。
2.遗传算法
如图7-(b),遗传算法虽然能够在全局进行搜索,但是也可能无法快速抵达“山顶”。
3.本算法
如图7-(c),本算法将局部搜索得到的局部最优解加入禁忌表,再次出现时直接进行遗传搜索(本算法中禁忌表还被用于记录局部搜索过程中搜索过的邻域解,以避免重复搜索)。
十、只检测部分邻域解的局部搜索算法
预先指定邻域解检测个数k。
那么,对于当前解的局部搜索过程如下:
1.随机选择当前解的一个邻域解。
2.如果此邻域解比当前解更优,则邻域解作为新的当前解替换原来的当前解,并返回本步骤1;否则执行下一步。
3.如果已经检测了当前解的k个邻域解,即当前解被检测的k个邻域解中没有更优的解,则程序结束;否则返回本步骤1。
此外,由于本算法对每个解的各目标函数随机加权,因此每个当前解都有自己独特的局部搜索方向,从而使局部搜索方向多样化。
十一、锦标赛选择法
预先指定锦标赛选择法每次选择的个体数量n(n≤Npop)。
锦标赛选择法的步骤如下:
1.从种群中随机选择n个个体。
2.从选择出的n个个体中选择最优的一个个体。
3.重复步骤1、步骤2,直至选择到相应个数的个体。
十二、两点交叉算子
在本算法中,两点交叉算子被用于编码机器选择部分的交叉。
如图8所示,两点交叉算子的步骤为:
1.随机选择编码中两个不同的位置。
2.交换两个位置点之间的部分。
十三、基于工序编码交叉算子
在本算法中,基于工序编码交叉算子被用于编码的工序序列部分的交叉。
如图9的示例所示,基于工序编码交叉算子的步骤为:
1.随机地从工件中产生两个子工件集Js1和Js2。
2.把父代1中属于Js1的元素复制入子代1中的相同位置,把父代2中属于Js2的元素复制入子代2中的相同位置。
3.把父代2中除Js2所含元素以外的其他元素按顺序填入子代1的空位置,把父代1中除Js1所含元素以外的其他元素按顺序填入子代2的空位置。
十四、机器选择部分的突变算子
如图10的示例所示,机器选择部分的突变算子为:
1.在机器选择部分随机选择一个位置。
2.从该位置对应工序的机器集中随机选择一台机器(的编号)替换当前机器(的编号)。
十五、工序序列部分的突变算子
如图11的示例所示,工序序列部分的突变算子为:
1.在工序序列部分随机选择两个位置。
2.交换这两个位置对应的值(工序)。
十六、含禁忌表的遗传与局部搜索算法
如图12,含禁忌表的遗传与局部搜索算法的执行步骤为:
1.将局部搜索过程中搜索到的局部最优解和搜索过的邻域解加入禁忌表。
2.在对每一代进行搜索的过程中,对于禁忌表中出现的解直接加入遗传组,不再进行局部搜索。
3.对没有在禁忌表中出现的解进行局部搜索,将搜索到的局部最优解加入遗传组,同时将此局部最优解和搜索过的邻域解加入禁忌表(更新禁忌表)。
4.对遗传组中的解进行遗传搜索。
5.如果满足终止条件,即已经检测了指定个数的解,则算法结束;否则返回步骤1。
十七、算法详细流程如下
如图13。
设种群规模为Npop;交叉概率为Pc;突变概率为Pm;局部搜索中对每个当前解检测k个邻域解;对遗传组的选择采用锦标赛选择法,锦标赛选择法每一轮选择的解的数目为n,n<Npop;算法迭代的终止条件为已经检测了num个解。
步骤一—初始化种群
1.根据生产信息分别产生全部工件的工序集W(式(1))和全部工序的机器集Mij(式(2))。
2.按照工序集中工序的顺序,依次从相应工序的机器集中随机选择一台机器,以机器集中的编号组成机器选择部分的编码。
3.根据每个工件的工序数产生相应个数的数值为工件编号的数,并将这些数随机排列组成工序序列部分的编码。
4.机器选择部分的编码在前,工序序列部分的编码在后,将它们组合。
5.返回本步骤2,直至已经产生Npop个解。
步骤二—计算目标函数值
1.计算每个解的目标函数值。
步骤三—更新精英组
1.将当前种群中的非支配解复制入精英组。
2.检测精英组中的解,将被其他解所支配的解从精英组中删除。
步骤四—计算适应度函数值(对每个解)
1.通过式(6)确定各目标函数的加权值。
2.通过式(9)计算每个解的适应度函数值。
步骤五—更新禁忌表
1.将当前种群中在禁忌表出现的解加入遗传组。
步骤六—局部搜索(对每个解)
1.随机选择当前解的一个邻域解,邻域解通过遗传搜索中的突变算子产生。
2.将此邻域解复制入禁忌表。
3.如果邻域解优于当前解,则以邻域解作为当前解替换原当前解,返回本步骤1;否则,执行下一步。
4.如果已经检测了当前解的k个邻域解,则执行下一步;否则,返回本步骤1.
5.将检测到的局部最优解加入遗传组。
步骤七—(对遗传组)选择
1.从遗传组中随机选择n个个体。
2.根据适应度函数值,从被选择的n个个体中选择最优的一个个体。
3.返回本步骤1,直至选择到目标个数的个体。
步骤八—(对遗传组)交叉
1.根据交叉概率Pc计算进行交叉的解的数目,并随机选出相应数目的解。
2.随机将被选择的解两两一组作为一对父代解。
3.对每个解的机器选择部分使用如图8所示的两点交叉算子进行交叉,对每个解的工序序列部分采用如图9所示的基于工序编码交叉算子进行交叉。
步骤九—(对遗传组)突变
1.根据突变概率Pm计算进行交叉的解的数目,并随机选出相应数目的解。
2.对每个解的机器选择部分和工序序列部分分别采用如图10所示的突变算子和如图11所示的突变算子进行突变。
步骤十—迭代
1.如果算法已经检测了num个解,则执行下一步骤(更新精英组);否则,返回步骤二(计算目标函数值)。
步骤十一—更新精英组
1.将当前种群中的非支配解复制入精英组。
检测精英组中的解,将被其他解所支配的解从精英组中删除。
- 还没有人留言评论。精彩留言会获得点赞!