基于不确定环境下的多目标流水车间逆调度方法与流程
本发明属于车间调度领域,具体涉及一种不确定环境下的多目标流水车间逆调度方法。
技术背景
新一代信息化与工业化的深度融合,使得工业企业进入了智能制造新的发展阶段,车间调度系统作为实现智能制造的关键环节,亟需发展新型的车间调度理论与方法来应对工业背景下智能车间的挑战。传统的调度问题往往假设生产是在理想确定的环境下进行,每个工件的加工信息和车间状况都是理想状态,并且不可随意更改,依据这些给定加工参数或者现有资源按照效益最大或成本最低的原则在多项生产任务中进行分配。
然而,在市场经济环境下,车间系统中拥有的部分资源约束是弹性的,车间状况实际上具有动态不确定性,存在一系列突发事件干扰,例如工件随机到达、机器故障维修等,这使得初始优化的调度方案,往往由于车间状态的变化而失去最优性,有时甚至变为不可行。以往解决思路是进行重调度或者动态调度,这些方法通过不断调整调度方案来解决问题。但是,这可能导致:1)调整后的调度方案与实际加工工艺路线不相符,违背工艺路线约束;2)系统调整使得交货期发生变动,甚至可能影响上下游排产;3)多次调整调度顺序也会影响系统稳定性,这将与实际生产中所约束的某些特征相违背,传统的调度方法难以有效应用于动态不确定环境下的车间生产实践。
因此,一些研究者依据逆优化互补最优性条件,探讨基于车间调度模型的某些非可行解成为最优解的问题,称为“车间逆调度”,这是车间调度领域近年来出现的一种新思想。是指:如何对给定加工参数的估计值尽可能“小”的调整,在此基础上得到这些参数的改变值,从而使得原先的一个可行调度在该情况下变成最优调度。例如,针对某些生产车间(如汽车、飞机、造船等行业的数控加工车间),实际市场需求或交货期、原材料、设计方案等变化导致现有生产无法完成,往往需要通过对设备、刀具等车间生产状态的相关参数进行调整以保证生产平稳高效进行。那么,如何调整相关参数既保证方案满足期望,又使得相关成本最低或方案改变最小成为亟需解决的问题,这使得逆调度的研究具有实际意义。
然而,基于不确定环境下的车间逆调度方法研究还存在如下问题,当前,逆调度问题的研究尚处于起步阶段,缺乏相应的调度模型、策略和方法的研究。仅限于单机车间逆调度问题研究,并且采用简单的精确算法进行求解,智能算法求解该问题尚属空白。这并不是由于逆调度缺少实际应用,而是由于目前对该问题研究成果较少,问题本身具有各自特性和复杂性;并且,关于逆调度问题的研究背景不足,这些都限制了对逆调度问题的深入研究。据统计,在实际生产过程中,经常存在不确定干扰因素,影响车间调度系统运行,将逆调度的研究成果应用于实际生产,将改善原有调度系统的性能,提高生产效率,更好地适应多变的生产环境。
技术实现要素:
本发明提供一种基于不确定环境下的多目标流水车间逆调度方法,主要解决了采用传统的调度方法难以有效处理某些实际生产存在的干扰情况,保证车间生产平稳运行,同时提高调度效率及调度稳定性。
为实现上述目的,本发明的技术方案为:
一种基于不确定环境下的多目标流水车间逆调度方法,用于对车间调度系统存在的动态多变情况,进行及时响应的问题,实现车间系统有效运行。该方法包括如下步骤:
1)建立基于不确定环境下的多目标流水车间逆调度问题模型
此问题中主要考虑车间效率和车间系统波动情况,包括三个目标:
(1)尽可能小地调整加工参数,即:
(1)
其中,
(2)完工时间和尽可能接近原指标,即:
(2)
其中,
(3)最小化调度系统调整量,即:
(3)
其中,H 代表哈明距离,即两条染色体直接的个体差异
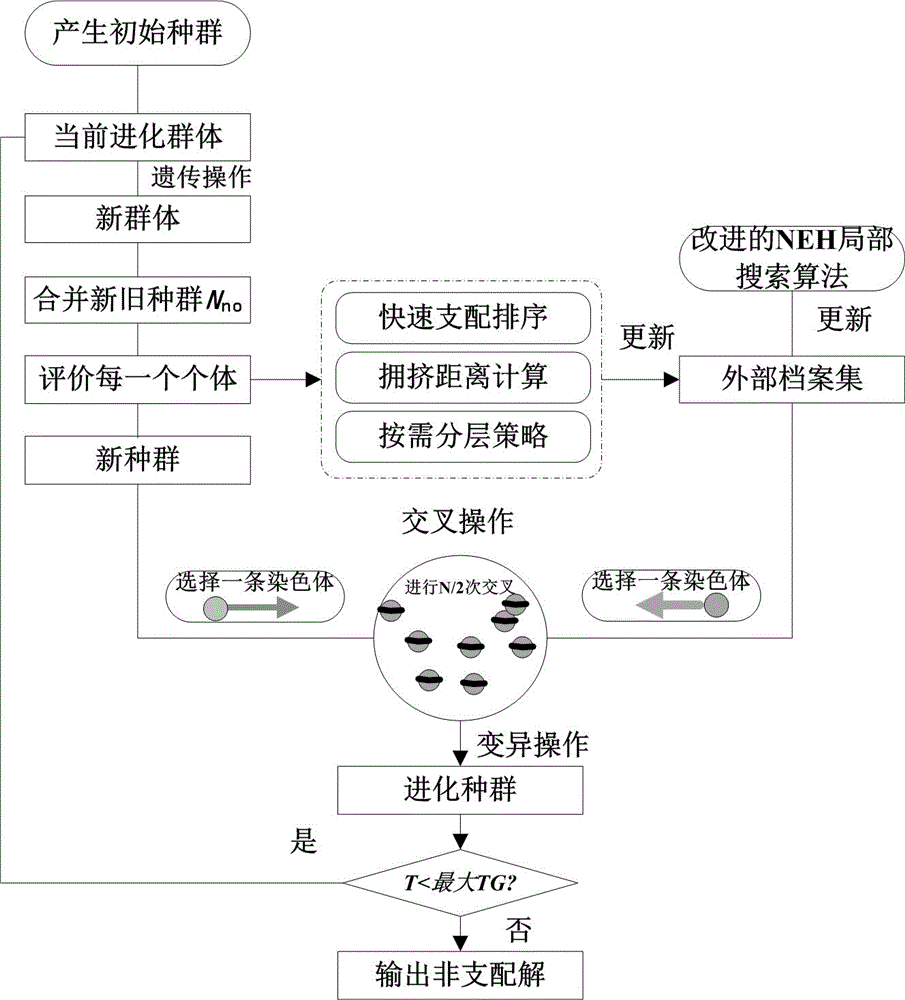
2)采用改进的混合多目标遗传算法求解上述问题模型,具体过程如下:
(1)设置种群个数为N,依据编码方案,采用混合初始化方式生产初始化种群;
(2)评价上述初始化的种群,并令迭代次数Gen=1;
(3)采用遗传操作,基于改进的变异操作和交叉操作更新当前种群;
(4)形成子种群,并与父代种群合并,形成种群数量为2N的新种群;针对2N个个体,采用NSGAII中的快速非支配排序法进行排序进行非支配解排序,获得非劣解集;
(5)采用比较的方式,将此非劣解集与外部档案集中的解依次对比,将新的非支配解替换旧解,更新外部档案集;
(6)挑选外部档案集中的部分个体,采用基于NEH局部搜索策略执行局部搜索,得到新的个体,重新更新外部档案集;
(7)通过交叉、变异操作,重新组合形成新的种群N;
(8)判断迭代次数Gen是否达到规定的阈值maxGen,若是,则结束算法,输出最后的非支配解集,若否,则令Gen=Gen+1,并跳转至步骤(3)继续操作。
作为本发明的进一步改进,所述的不确定环境下的多目标流水车间逆调度问题模型,通过最小地改变加工参数,使得原始调度顺序变为最优为核心,面向顾客与制造商考虑,建立了考虑最小化加工参数波动、系统波动以及完工时间和波动的问题模型。
作为本发明的进一步改进,所述的编码方案为基于实数表达的编码方案。编码设计上需要,加工工序的安排以及加工参数的波动等信息,采用传统的基于工序的编码方案或基于工件的编码方案,针对该问题在交叉、变异操作中易出现不可行解。因此,采用基于实数表达的编码方案避免此问题,具体为:该编码方案中每一个元素由(I.D)两部分组成:I是整数值,表示工件顺序,D是小数值,由三位小数组成[ABC],其中AB表示工件的加工工序,C不同工序相应的加工参数波动量。
作为本发明的进一步改进,所述的种群初始化方式,采用两种非最优调度混合的初始化方法,产生逆调度激发机制。具体为:第一种方式是通过随机产生AB部分,即随机生成工序部分,来初始化部分种群,然后,第二种方式是通过随机产生C部分,即随机生成加工参数部分,来初始化其余种群。
作为本发明的进一步改进,所述适应度值评价方式,在基于NSGAII中快速非支配排序方法的基础上,分别引入拥挤距离和分布函数,来增加种群多样性,同时使得非支配解集均匀分散。具体为:
引入拥挤距离截断外部档案集,使得外部档案中的解均匀分布,并且在基于NSGAII中快速非支配排序方法的基础上,采用分布函数:,其中ni为第i层曲面Fi上挑选的个体数量,| Fi| (i ≥1)代表第i层非支配曲面上非支配解的数量,r∈(0,1)。
作为本发明的进一步改进,所述的外部档案集更新方式采用混合方式,具体为:建立一个独立于进化群体的外部档案集,采用两种策略来更新外部档案集,一种是记忆库中的个体参与新种群的产生,通过优秀替换旧个体进行更新,另一种方式是采用基于NEH局部搜索方法对外部档案集中部分个体进行更新。
作为本发明的进一步改进,所述的外部档案集更新方式,采用基于NEH插入法的局部搜索方法进行更新,具体为:采用NEH插入构想,主要针对小数位基金进行插入变换,执行局部搜索,为了控制邻域搜索的个体数量,减少计算时间,采用公式nGB=max{NM×(1-t/TG),1},调整进化代数和执行插入操作工件数量,约束执行领域搜索的个体数量,其中,NM代表执行插入操作工件的最大数目;t是指当前进化代数;TG是指最大进化次数。另外两个变量需要指出:分布为插入工件的开始位置和终止位置:i和m=i+nGB-1。
作为本发明的进一步改进,所述的最后新种群的生产方式具体为:分布从外部档案集和新混合种群中挑选两个个体,执行交叉操作、变异操作,重复操作,直到种群个数达到N。
本发明的有益效果主要表现在:(1)针对动态多变的流水车间调度系统,基于逆优化思想,通过对工件加工参数进行微调来对预先给定的非最优调度顺序进行优化调整。针对多目标流水车间逆调度问题,面向顾客与制造商考虑,建立了考虑最小化加工参数波动、系统波动以及完工时间和波动的问题模型。
(2)提出了基于实数表达的编码方案,分块表达加工参数信息,协同优化不同工序和加工参数等信息。并且采用两种非最优调度混合的初始化方法,产生逆调度激发机制,提高初始种群多样性和个体质量。
(3)针对问题特征,基于NEH中的插入操作,设计了四种不同的邻域结构,通过邻域结构的切换,执行局部搜索。 同时引用数学公式来控制进行邻域搜索个体的数量,以此达到减少计算时间的目的,此操作可以保证在种群进化初期,执行较大规模的邻域搜索,而到了进化末期,较少邻域搜索的范围,这样不仅提高了算法局部搜索性能,同时减少了计算时间。
附图说明
图1为本发明的流程图;
图2为本发明的改进的混合多目标遗传算法流程示意图;
图3为本发明的基于实数的编码方案示意图;
图4为本发明的工序部分初始化方案示意图;
图5为本发明的加工参数部分初始化方案示意图;
图6为本发明的交叉操作示意图;
图7为本发明的变异操作示意图;
图8为本发明的基于NEH局部搜索方法示意图。
具体实施方法
下面结合附图和具体实施例对本发明做进一步说明。
参照图1,一种基于不确定环境下的多目标流水车间逆调度方法,包括如下步骤:
1、建立基于不确定环境下的多目标流水车间逆调度问题模型
此问题中主要考虑车间效率和车间系统波动情况,包括三个目标:
(1)尽可能小地调整加工参数,即:
(1)
其中,
(2)完工时间和尽可能接近原指标,即:
(2)
其中,
(3)最小化调度系统调整量,即:
(3)
其中,H 代表哈明距离,即两条染色体直接的个体差异
改进的混合多目标遗传算法流程如附图2所示,具体操作如下:
(1)参数设置
进行算法参数设置,主要包括最大迭代次数Tg、种群个数N、交叉概率Pc、变异概率Pm、复制概率Pr、锦标赛选择参数r、执行NEH局部搜索的最大个体数量Nm等。
(2)编码
编码方案采用基于实数表达的编码方案。编码设计上需要考虑加工工序的安排以及加工参数的波动等信息,采用传统的基于工序的编码方案或基于工件的编码方案,针对该问题在交叉、变异操作中易出现不可行解。因此,采用基于实数表达的编码方案避免此问题,具体为:该编码方案中每一个元素由(I.D)两部分组成:I是整数值,表示工件顺序,D是小数值,由三位小数组成[ABC],其中AB表示工件的加工工序,C不同工序相应的加工参数波动量。以4个工件的流水车间调度问题为例,其编码方式如附图3所示,编码= [+1.032,-3.014,+4.021,+2.042],编码方案由4个实数组成,其中第一部分为整数,依次解码为[1,3,4,2],表示工件1先加工,其他工价依次加工。小数部分由三位小数组成,前两位是工件加工顺序,解码为[03,01,02,04]依次代表第一工件第三道工序O13,其他依次为:O31,O42,O24。最末位小数是加工时间波动量,此染色体中解码为[2,4,1,2],正号“+”代表增加,负号“-”代表减少。例如+1.032代表第一个工件的第三道加工工序的加工时间增加2。
(3)初始化种群
种群初始化方法对进化算法有显著影响,好的初始解能够提高算法的求解质量和速度,这里采用采用两种非最优调度混合的初始化方法,产生逆调度激发机制。具体为:第一种方式是通过随机产生AB部分,即随机生成工序部分,来初始化部分种群。具体操作如图4所示,整数部分不变,小数部分末位不动,另外两位随机生成。通过此方式产生M个个体。
第二种方式是通过随机产生C部分,即随机生成加工参数部分,通过此方式来初始化N-M个个体,具体操作如附图5所示。
(4)遗传操作
选取种群中的部分个体,执行遗传操作,主要包括交叉操作和变异操作。常用的交叉策略:线性交叉操作和块交叉操作,在此基础上进行改进。线性交叉操作,如附图6所示,以7个工件的染色体为例。随机选取3、5作为交叉位置,将父代P1、P2中交叉位置内的基因直接复制到子代C1、C2中的相应位置;工件4和工件5已用,因此,将P2中工件4、5去掉,将P2中剩下的元素依次填入到C1中相应位置,形成新的染色体,同样方式生成C2染色体。
遗传算法中的变异操作,主要采用单点变异操作和插入变异操作,并在此基础上进行改进,如附图7所示。单点变异操作具体为:随机挑选一个基因位置,将此元素中的小数部分前两位基因执行变异操作。
(5)适应值评价方法
多目标优化问题,存在多个待优化的子目标,目标适应值分配是多目标问题求解中的一个关键部分,NSGA-II中采用基于优胜的快速非支配排序方法进行适应度赋值,在多目标优化领域具有广泛应用。在此所述适应度值评价方式,采用NSGAII中快速非支配排序方法,但是该算法具有较弱的全局搜索能力,分布不均,易收敛等缺陷。为了克服这些问题,在适应度值评价方式中分别引入拥挤距离和分布函数,来增加种群多样性,同时使得非支配解集均匀分散。具体为:
引入拥挤距离截断外部档案集,使得外部档案中的解均匀分布,并且在基于NSGAII中快速非支配排序方法的基础上,采用分布函数:ni =|Fi| ×ri,其中ni为第i层曲面Fi上挑选的个体数量,| Fi| (i ≥1)代表第i层非支配曲面上非支配解的数量,r∈(0,1)。
(6)外部档案集更新
外部档案集更新方式采用混合方式,具体为:建立一个独立于进化群体的外部档案集,采用两种策略来更新外部档案集,一种是记忆库中的个体参与新种群的产生,通过优秀替换旧个体进行更新,另一种方式是采用基于NEH局部搜索方法对外部档案集中部分个体进行更新。此外,新形成的外部档案集中采用基于NEH插入法的局部搜索方法进行更新,具体为:采用NEH插入构想,主要针对小数位基金进行插入变换,执行局部搜索,为了控制邻域搜索的个体数量,减少计算时间,采用公式nGB=max{NM×(1-t/TG),1},调整进化代数和执行插入操作工件数量,约束执行领域搜索的个体数量,其中,NM代表执行插入操作工件的最大数目;t是指当前进化代数;TG是指最大进化次数。另外两个变量需要指出:分布为插入工件的开始位置和终止位置:i和m=i+nGB-1。其基于NEH局部搜索方法如附图8所示。
(7)形成新种群
按照交叉概率Pc采用下面方式进行操作,直到产生的个体达到种群数,从外部档案集中随机选择一个个体作为父代1,从合并的新种群中选择一个个体作为父代2,执行改进的交叉操作;反复操作,直到个体数量达到N;依据变异概率Pm执行变异操作,将得到的新个体取代当前个体。
(8)算法终止条件
判断是否满足算法终止条件(终止条件是迭代次数达到最大迭代次数)。如果满足,停止迭代,返回最优解;否则,令Gen=Gen+1,并跳转至步骤(4)继续操作。。
本发明的效果可以通过以下仿真实验进一步说明:
(1)测试实例
采用流水车间调度问题中常用的问题实例,主要包括:Taillard benchmark测试集, Car类问题测试集和 Rec类问题测试集。
(2)仿真实验参数设置
为了验证改进的混合多目标遗传算法的优秀性能,采用NSGAII算法进行比较。两个算法均在相同环境下独立运行30次,将其进行结果比较。算法相关参数设置如表1所示。
表1算法参数设置
(3)结果对比
为了比较两种算法,采用三种性能评价指标来展示非支配解情况,三种性能评价指标分别为:反世代距离IIGD ,非支配解个数NNDS,非支配解比例(RNDS)。表2给出了两种算法为每个实例独立运行30次后得到的指标IIGD结果比较。
表2 改进的混合多目标遗传算法H1和NSGAII算法IIGD结果比较
表2给出两个算法求得119个问题实例的反世代距离比较结果。反世代距离反映了算法求得的解与问题真实解之间距离的远近程度,因此,其实越小越好,如果值为0,则表示算法所求得的解完全接近Pareto真实解。对于每一个问题实例,改进的混合多目标遗传算法所得到的平均值都远小于NSGAII算法求得的平均值。尤其是对于中、小规模的问题实例,所得到的反世代距离值接近于0,结果表明,改进的混合多目标遗传算法几乎可以找到所有Pareto最优解。
综上所述,针对不确定环境下的多目标流水车间逆调度问题,本发明在解的质量方面,以及稳定性方面明显优于NSGAII算法。
- 还没有人留言评论。精彩留言会获得点赞!
- 一种改进的布谷鸟搜索算法解决作业车间调度问题的制造方法与工艺
- 针对作业车间生产问题的排产算法的制造方法与工艺
- 一种新的解决作业车间调度问题的排产算法的制造方法与工艺
- 一种基于帝国主义竞争的算法解决车间工人调度问题的制造方法与工艺
- 一种改进的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种求解并行机作业车间调度的混合启发式转移瓶颈算法的制造方法与工艺
- 针对多目标柔性作业车间调度问题的含救济算子的混合遗传算法的制造方法与工艺
- 一种解决作业车间调度问题的排产算法的制造方法与工艺
- 一种改良的帝国主义竞争算法求解作业车间调度问题的制造方法与工艺
- 一种解决作业车间多个订单交付周期存在冲突问题的算法的制造方法与工艺