基于层次分析法和模糊融合的工业过程故障分类方法与流程
本发明属于工业过程控制领域,特别涉及一种基于层次分析法和模糊融合的工业过程故障分类方法。
背景技术:
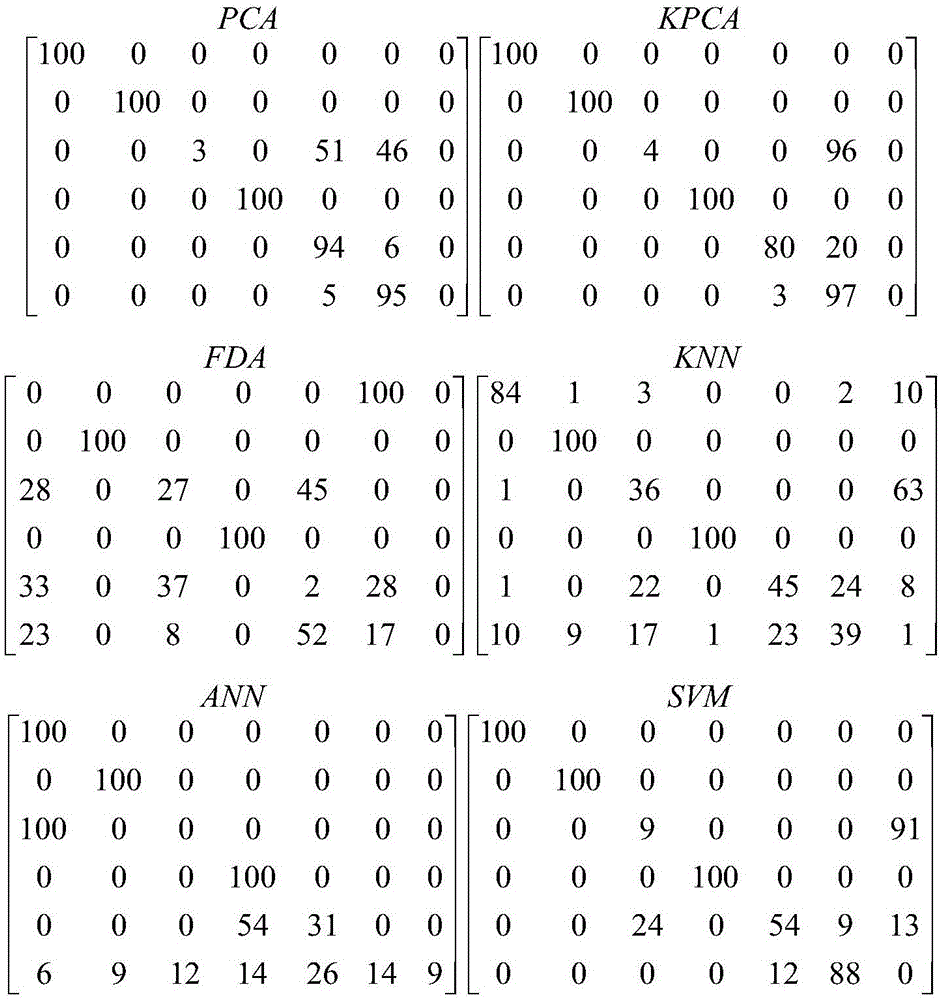
:近年来,工业生产过程的监测问题越来越得到工业界和学术界的广泛重视。一方面,实际的工业过程因为其过程复杂,操作变量多,存在非线性、非高斯、动态性等阶段,在单一假设下,运用某一种方法,其监测效果有很大的局限。另一方面,如果不对过程进行很好的监测,并对可能发生的故障进行诊断,有可能会发生操作事故,轻者影响产品的质量,重者将会造成生命和财产的损失。因此,找到更好的过程监测方法、并进行及时正确地预报已经成为工业生产过程的研究热点和迫切需要解决的问题之一。传统的工业过程监测方法除了基于机理模型的方法外,大多采用多元统计分析方法,比如主元分析方法(PCA)和偏最小二乘方法(PLS)等。在机理模型难以获取的情况下,基于数据驱动的多元统计分析方法已经成为工业过程监测的主流方法。但是,传统的多元统计分析方法都存在一些基本的假设条件,而实际工业过程却相对复杂,过程可能是一部分线性、一部分非线性或者一部分非高斯的结合,所以使用单一分类器方法存在一些局限性,很难找到合适的模型。而信息融合方法是将多种方法进行集成,可以克服单一方法的劣势,在处理复杂工业过程的监控和故障诊断方面有其自身的优势。本发明采用该方法替代原有的单一多元统计分析方法对过程进行监测。另外为了提高融合效果,采用层次分析法对单一模型进行评价,得到单一模型在融合中的权重,使得融合过程中能够最大化放大单一模型的优势,弥补单一模型的劣势。传统的监测方法假设过程运行在单一条件下,已经无法满足实际工业过程的监测要求。即使对过程的不同工作条件分别进行建模,也无法达到满意的监测效果。因为对新的过程数据进行监测时,需要结合过程知识对该数据的工作条件进行判断,并选取相应的监测模型,这就大大增强了监测方法对过程知识的依赖性,不利于工业过程的自动化实施。技术实现要素:本发明的目的在于针对现有方法的假设局限,提供一种基于层次分析法和模糊融合的工业过程故障分类方法。本发明的目的是通过以下技术方案来实现的:一种基于层次分析法和模糊融合的工业过程故障分类方法,包括以下步骤:(1)利用系统收集过程正常工况的数据以及各种故障数据组成建模用的训练样本集:假设故障类别为C,在加上一个正常类,建模数据的总类别为C+1,即Xi=[x1;x2;…;xn]i=1,2,…,C+1。其中Xi∈Rn×m,n为训练样本数,m为过程变量数,R为实数集,Rn×m表示X满足n×m的二维分布。所以完整的训练样本集为X=[X1;X2;…;XC+1],X∈R((C+1)*n)*m,将这些数据存入历史数据库。(2)收集与训练数据不同的样本数据作为离线测试数据,共C类,每一类数据为Yj=[y1;y2;…;yN],j=1,2,…,C,其中Yj∈RN×m,且N为测试样本数,m为过程变量数,完整的测试样本集为Y=[Y1;Y2;…;YC],Y∈R(C*N)*m,将这些数据存入历史数据库。(3)从数据库中调用训练数据X,对其进行预处理和归一化,使得各个过程变量的均值为零,方差为1,得到新的数据矩阵集为(4)按照上一步得到的训练样本均值和方差对测试数据Y进行预处理和归一化,使得各个过程变量的均值为零,方差为1,得到新的数据矩阵集为(5)调用不同的分类器方法,选择分类器的个数为G,在新的数据矩阵集下建立不同的分类器模型。(6)在测试数据集下,利用不同的模型和参数,计算每个分类器的融合矩阵Mg,g=1,2,…,G,并且Mg∈RC*(C+1)。(7)根据每一个分类器模型的分类结果和融合矩阵数据构造层次结构模型,通过层次分析法对单一分类器性能进行评价,给出打分排序结果。(8)将建模数据和各个模型参数存入历史数据库中备用。(9)收集新的过程数据Xnew,并对其进行预处理和归一化得到分别采用不同的分类器模型对其进行监测得到分类结果,根据分类结果和之前得到的融合矩阵中包括的各个模型先验知识计算得到判别矩阵D∈RG*C。(10)结合之前层次分析法对模型的评价结果以及判别矩阵,使用模糊融合方法,计算当前监测数据在所有分类器方法下的综合分类结果,做出最后决策。本发明的有益效果是:本发明通过对每一个故障数据分别进行不同分类器方法下的分析和建模。然后,通过层次分析法对不同分类器的分类效果做出打分评价,最后结合模糊融合方法将不同分类器方法下的分类结果进行集成融合,得到最终的分类结果。相比目前的其他故障分类方法,本发明不仅提高了工业过程的监测效果,增加了分类的准确性,使工业生产更加安全可靠,而且在很大程度上改善了单一故障分类方法的局限性,以及分类方法对过程知识的依赖性,增强了过程操作员对过程状态的掌握,更加有利于工业过程的自动化实施。附图说明图1是6种单一分类器模型融合矩阵图;图2是层次结构决策模型图;图3是模糊融合方法的故障分类结果图;图4是投票融合方法的故障分类结果图。具体实施方式本发明针对工业过程的故障分类问题,首先利用集散控制系统收集正常工作状态下的数据以及几种故障数据作为训练数据集,然后分别调用不同的分类器方法,建立相应的分类器模型,构造两个监测统计量T2和SPE及其对应的统计限和SPElim,以及类别标签。并且使用离线测试数据集进行离线测试,得到融合矩阵。然后通过层次分析法对不同的分类器模型进行打分评价,把所有的模型参数存入数据库中备用。对新的在线过程数据进行故障分类的时候,首先利用不同的分类器模型对其进行分类,得到相应的分类结果,根据分类结果和之前的融合矩阵包含的先验知识计算得到判别矩阵。最后结合之前的分类器打分结果使用模糊融合方法将不同分类器的分类结果集成融合得到最终的分类结果。本发明采用的技术方案的主要步骤分别如下:第一步、利用系统收集过程正常工况的数据以及各种故障数据组成建模用的训练样本集:假设故障类别为C,在加上一个正常类,建模数据的总类别为C+1,即Xi=[x1;x2;…;xn]i=1,2,…,C+1。其中Xi∈Rn×m,n为训练样本数,m为过程变量数,R为实数集,Rn×m表示X满足n×m的二维分布。所以完整的训练样本集为X=[X1;X2;…;XC+1],X∈R((C+1)*n)*m,将这些数据存入历史数据库。第二步、收集与训练数据不同的样本数据作为离线测试数据,共C类,每一类数据为Yj=[y1;y2;…;yN],j=1,2,…,C,其中Yj∈RN×m,且N为测试样本数,m为过程变量数,完整的测试样本集为Y=[Y1;Y2;…;YC],Y∈R(C*N)*m,将这些数据存入历史数据库。第三步、从数据库中调用训练数据X,对其进行预处理和归一化,使得各个过程变量的均值为零,方差为1,得到新的数据矩阵集为第四步、按照上一步得到的训练样本均值和方差对测试数据Y进行预处理和归一化,使得各个过程变量的均值为零,方差为1,得到新的数据矩阵集为第五步、调用不同的分类器方法,选择分类器的个数为G,在新的数据矩阵集下建立不同的分类器模型。选择G为6种不同的多分类器方法,具体包括:两种无监督方法主元分析(PCA)、核主元分析(KPCA),以及四种有监督方法:费舍尔判别分析法(FDA)、K近邻方法(KNN)、神经网络方法(ANN)、支持向量机(SVM)。以新的数据矩阵集作为训练样本,建立相应的分类器模型。具体实现步骤如下所示:5.1、进行PCA建模,可以得到数据矩阵的协方差矩阵S∈Rm×m、酉矩阵U∈Rm×m、特征值构成的对角矩阵Λ∈Rm×m如下所示:S=UΛUTΛ=diag(λi),i=1,...,mU=[u1,u2,...,um]其中,表示新的数据矩阵集,S表示协方差矩阵,U表示酉矩阵,n表示训练样本数,m为变量数,Λ表示特征值λi构成的对角矩阵,且其对角元素是按照由大到小的顺序排列的diag(·)表示将括号中的量按对角线排列,um表示第m个构成U的列向量。然后在其基础上得到负荷矩阵P∈Rm×k、残差负荷矩阵主元成分T∈Rn×k、残差矩阵如下所示:P=[u1,u2,...,uk]其中k为提取的主元个数,是通过累计方差贡献率(>80%)计算得到的。然后构造T2统计量并利用F分布给出监测统计限对残差矩阵建立SPE统计量并计算其相应的监测统计限SPElim。5.2、进行KPCA建模,利用径向基核函数,通过非线性映射将原输入空间映射到高维特征空间,然后在高维特征空间内进行主元分析如上述PCA方法。在高维空间通过求取特征值、特征向量和得分并利用累计方差贡献率(>80%)计算得到主元个数k,得到相应的负荷矩阵、主元。同样构造T2统计量并利用F分布给出监测统计限对残差矩阵建立SPE统计量并计算其相应的监测统计限SPElim。5.3、通过FDA方法,确定投影向量,使得类间离散度最大,类内离散度最小,并确定每一类的中心点位置。5.4、通过KNN方法,设近邻点个数为5,给数据加上类别标签。5.5、通过ANN方法,选择含有三个隐层节点的两层BP网络,隐层选择tansig函数,输出层选择purelin函数,然后进行训练。5.6、通过SVM方法,使用多类一对一的建模方法,在任意两类样本之间建立一个SVM模型。第六步、在测试数据集下,利用不同的模型和参数,计算每个分类器的融合矩阵Mg,g=1,2,…,G,并且Mg∈RC*(C+1)。对于归一化之后的新数据分别采用不同的分类器模型对其进行监测,然后根据分类结果得到融合矩阵,具体步骤如下:6.1、对于PCA分析,根据之前建模得到的参数,计算测试样本数据在C+1类模型下的T2和SPE值,通过两个统计量构造一个新的判别指数θi,具体如下所示:其中αi为得分Ti的累积方差贡献率,i的个数为在不同类别训练数据下通过PCA建模得到的不同模型方法个数,Ti2和SPEi为测试样本带入第i个模型得到的统计值,和SPElimi分别为步骤(5)第i类数据建模得到的检测统计限,最终选取θi最小的类别作为测试样本的分类结果,并且将测试数据中所有样本的分类结果以融合矩阵M∈RC*(C+1)的形式展现,矩阵中的行代表样本数据的实际类别,列代表模型分类结果;6.2、对于KPCA分析,同上述的PCA过程。6.3、对于FDA分析,计算测试样本与各个类别中心的欧氏距离,距离最小的类别作为分类结果,也同样将所有测试样本的分类结果以融合矩阵矩阵M∈RC*(C+1)的形式展现。6.4、对于KNN分析,计算测试样本和已知类别标签样本的距离,选取最近邻的K个样本,并将K个样本的标签类别进行统计,选取最多的一类作为测试样本分类,也同样将所有测试样本的分类结果以融合矩阵矩阵M∈RC*(C+1)的形式展现。6.5、对于ANN分析,将测试样本数据带入之前步骤建立的网络模型,得到输出分类结果,将所有测试样本的分类结果以融合矩阵矩阵M∈RC*(C+1)的形式展现。6.6、对于SVM分析,将测试样本带入之前建立的所有SVM模型中,然后采用投票的形式,得到最后的分类结果,将所有测试样本的分类结果以融合矩阵矩阵M∈RC*(C+1)的形式展现。第七步、根据每一个分类器模型的分类结果和融合矩阵数据构造层次结构模型,通过层次分析法对单一分类器性能进行评价,给出打分排序结果。7.1、首先根据上一步得到的每个分类器的融合矩阵计算每种分类器下不同评价指标的值,如下所示:其中Recall召回率指的是实际为某一类也被正确分为某一类的概率。7.2、然后通过层次分析法对单个分类器模型进行打分排序,具体步骤如下:7.2.1、建立层次结构模型选取准确率、漏报率、错分率、Precision、F值、模型运行时间六个评价指标作为准则层指标。选取PCA、KPCA、FDA、KNN、ANN、SVM作为方案层备选方案,构建决策评价层次模型。7.2.2、构造判断矩阵并进行层次单排序在准则层,因为F值结合了Recall和Precision的特性,所以将其作为第一级重要指标,因为在故障分类中出现漏报对于生产过程会造成很大影响,所以将漏报率作为第二级重要指标,将准确率、错分率作为第三级重要指标,将Precision作为第四级重要指标,将模型分类运行时间作为第五级重要指标。根据此排序构造各评价指标的成对比较矩阵,然后通过求取最大特征向量的方式计算各准则的相对优先值。在方案层,各个指标的优先值通过各分类器算法在不同评价指标上的量化值得到。7.2.3、层次总排序确定某层所有因素对于总目标相对重要性的排序权值过程,称为层次总排序。从最高层到最低层逐层进行。设:A层m个因素A1,A2,…,Am对总目标Z的排序为a1,a2,…,amB层n个因素对上层中A因素Aj的层次单排序为b1j,b2j,…,bnj(j=1,2,…,m)B层的层次总排序为B1:a1b11+a2b12+…amb1mB2:a1b21+a2b22+…amb2m…Bn:a1bn1+a2bn2+…ambnm即B层第i个因素对总目标的权值由此得到各个方案对总目标的权重,从而对各个分类器方法进行一个综合打分排序。第八步、将建模数据和各个模型参数存入历史数据库中备用。第九步、收集新的过程数据Xnew,并对其进行预处理和归一化得到分别采用不同的分类器模型对其进行监测得到分类结果,根据分类结果和之前得到的融合矩阵中包括的各个模型先验知识计算得到判别矩阵D∈RG*C。9.1、对于归一化后的新数据分别采用不同的分类器模型进行监测,得到不同模型下对于样本的分类结果,具体步骤如下:9.1.1、对于PCA方法其中为归一化之后的新数据,Tnew为新数据的主元,为残差矩阵,P为负荷矩阵,SPEnew为新数据的SPE统计量值,||·||表示2-范数,Dq表示前q个特征值构成的对角矩阵,Tnew2为新数据的T2统计量值,T为矩阵的转置。9.1.2、对于KPCA方法。同上述PCA过程。9.1.3、对于FDA方法,计算测试样本与各个类别中心的欧氏距离,距离最小的类别作为分类结果。9.1.4、对于KNN方法,计算测试样本和已知类别标签样本的距离,选取最近邻的K个样本,并将K个样本的标签类别进行统计,选取最多的一类作为测试样本分类。9.1.5、对于ANN方法,将测试样本数据带入之前步骤建立的网络模型,得到输出分类结果。9.1.6、对于SVM方法,将测试样本带入之前建立的所有SVM模型中,然后采用投票的形式,得到最后的分类结果。9.2、然后根据每个分类器的分类结果和之前得到的融合矩阵中包括的各个模型先验知识计算得到判别矩阵D∈RG*C如下:其中dki表示已知分类器k对样本的分类决策结果的前提下,样本实际来自第i类的可能性,G为分类器个数,C为类别数。dki的取值由融合矩阵计算得出,当分类器k对样本的分类决策结果为第j类时,样本实际来自第i类的可能性dki如下所示:其中pji指已知为第i类样本但被指派为第j类样本的概率,指的是第k个分类器方法将实际为第i类的样本判定为第j类的样本个数,C为类别数。第十步、结合之前层次分析法对模型的评价结果以及判别矩阵,使用模糊融合方法,计算当前监测数据在所有分类器方法下的综合分类结果,做出最后决策。10.1、由分类器评价得分和各分类器对可能分类结果的判断矩阵计算最终融合后的结果。如下所示:Y=X*D其中Y=(y1,y2,…yC)为模糊融合后各分类结果的可能性集合。10.2、最后,对于模糊融合后的结果,选取具有最大可能性的类别作为最终分类结果。以下结合一个具体的工业过程的例子来说明本发明的有效性。该过程的数据来自美国TE(TennesseeEastman——田纳西-伊斯曼)化工过程实验,原型是Eastman化学公司的一个实际工艺流程。目前,TE过程己经作为典型的化工过程故障检测与诊断对象被广泛研究。整个TE过程包括41个测量变量和12个操作变量(控制变量),其中41个测量变量包括22个连续测量变量和19个成分测量值,它们每3分钟被采样一次。其中包括21批故障数据。这些故障中,16个是己知的,5个是未知的。故障1~7与过程变量的阶跃变化有关,如冷却水的入口温度或者进料成分的变化。故障8~12与一些过程变量的可变性增大有关系。故障13是反应动力学中的缓慢漂移,故障14、15和21是与粘滞阀有关的。故障16~20是未知的。为了对该过程进行监测,一共选取了16个过程变量,如表1所示。表1:监控变量说明序号变量序号变量1A进料(流1)9产品分离器温度2D进料(流2)10产品分离器压力3E进料(流3)11产品分离器塔底低流量(流10)4总进料(流4)12汽提器压力5再循环流量(流8)13汽提器温度6反应器进料速度(流6)14汽提器流量7反应器温度15反应器冷却水出口温度8排放速度(流9)16分离器冷却水出口温度接下来结合该具体过程对本发明的实施步骤进行详细地阐述:1、采集正常过程数据以及6种故障数据作为训练样本数据,进行数据预处理和归一化。2、针对预处理和归一化后的训练样本数据,调用不同的分类器方法,分别建立不同的分类器模型并确定相应统计量的置信限和标签。经过剔除野值点和粗糙误差点以及归一化后的数据集为对新的数据矩阵进行模型建立:2.1、进行PCA分析和建模,选取6个主元成分,得到详细的PCA模型。然后构造T2统计量并用F分布确定其相应的监测统计限。同理,利用卡尔方分布确定SPE统计量的监测置信限。这里,我们选取两个统计量的置信度均为99%。2.2、进行KPCA分析和建模,选取5个主元成分,得到详细的KPCA模型。然后构造T2统计量并用F分布确定其相应的监测统计限。同理,利用卡尔方分布可以确定SPE统计量的置信限。我们选取两个统计量的置信度均为99%。2.3、通过FDA方法,确定投影向量,给建模数据加上类别标签1-7。2.4、通过KNN方法,设近邻点个数为5,给数据加上类别标签1-7。2.5、通过ANN方法,选择含有三个隐层节点的两层BP网络,将多类分类问题转化为二类分类,标签为0和1。2.6、通过SVM方法,使用多类一对一的建模方法,在任意两类样本之间建立一个SVM模型,给建模数据加上类别标签1-7。3、调用离线测试数据,进行离线监测,计算得到融合矩阵,如图1所示。4、通过层次分析法对各个分类器模型进行打分排序选取准确率、漏报率、错分率、Precision、F值、模型运行时间六个评价指标作为准则层指标。选取PCA、KPCA、FDA、KNN、ANN、SVM作为方案层备选方案,构建如图2所示决策评价层次模型。得到6种不同分类器模型的最终得分如表2所示,作为最终融合算法的权重。表2:不同分类器模型的得分结果分类器模型PCAKPCAFDAKNNANNSVM分数0.13350.13510.10130.22240.15280.25505、在线故障分类对于新来的归一化后的在线测试样本将样本分别输入6个不同分类器模型,得到六个分类结果,根据每个模型的预测分类结果,可以得到样本在某个分类器分类结果下实际来自某一类的概率,由此得到判别矩阵D,再利用之前得到的6个分类器模型的得分作为模糊融合的隶属度值,使用模糊融合方法得到样本最终分类结果,如图3所示。为了评价故障分类效果,使用错分率和漏报率作为评价指标。基于各个方法的故障分类结果如表3所示。表3:各单一分类器方法以及融合方法的故障分类效果从图3中可以看出模糊融合基本上能够将不同类别正确划分,并且与图4的投票融合结果相比较,具有更好的分类效果。从表3种也可以看出,单一分类器方法的错分率都较高,模糊融合的错分率为4%,低于单一分类器的错分率,明显提升了单一分类器的分类效果,使得分类结果更加可靠。并且相比投票融合方法,在故障漏报方面更具有优势,不会产生漏报现象,能够有效防止由于对故障的未识别造成的生产过程事故。上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明做出的任何修改和改变,都落入本发明的保护范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1