一种多Agent围捕‑觅食行为控制方法与流程
本发明涉及Agent围捕觅食技术,尤其是涉及一种多Agent围捕-觅食行为控制方法。
背景技术:
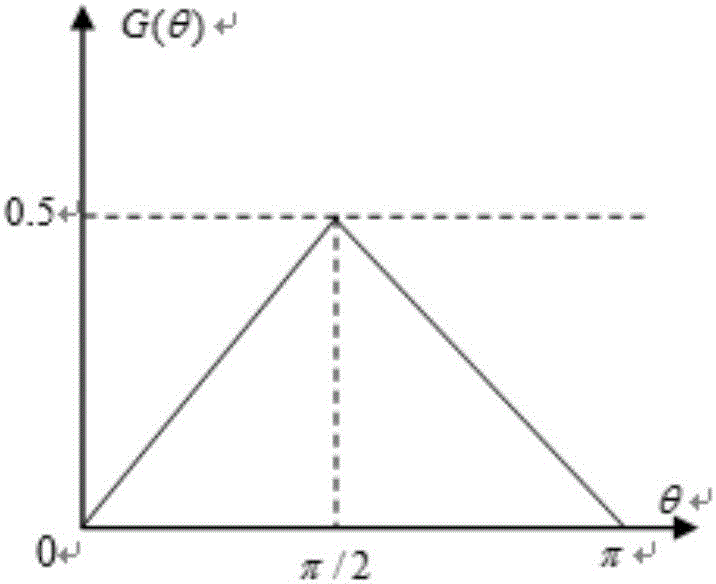
:多机器人系统作为分布式人工智能的一个非常重要的分支,具有容错性、鲁棒性强、分布性协调性等特点,近年来已成为人们广泛关注的热点。多机器人系统研究的主要问题包括群体结构、任务分配、通信方式、协作学习等。为了使得研究更具有在实际场景中的意义,研究者们集中对一些多机器人任务进行研究,包括编队协作、搜索、围捕等。多机器人协作围捕是检验多机器人工作效率的有效方法之一。多机器人围捕过程就是利用三个或者三个以上的轮式机器人,首先协作寻找到环境中移动的一个目标机器人,然后通过运动过程中围在目标周围来达到围捕目标的目的,最后目标没有运行的出口后,任务结束。多机器人围捕可以称为Agent的觅食问题,即指机器人模仿生物体的一系列动作以达到觅食的效果。多机器人的围捕-觅食问题涉及到许多方面的内容,如机器人编队、状态空间的划分、机器人动作的划分、多机器人控制策略的结构。前人在研究多Agent系统的围捕问题时一般采用栅格法。栅格法将机器人的状态空间按位置进行划分,虽然划分简单易懂,然而由于其粗糙的离散化方式,使得其精度不高,另一方面,倘若加大离散化的精度,则会产生“维数灾难”。因此,有必要重新对状态空间进行划分,使用某种连续的策略来更好的表现机器人的围捕-觅食行为,同时减小状态空间的数量。技术实现要素:本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种多Agent围捕-觅食行为控制方法。本发明的目的可以通过以下技术方案来实现:一种多Agent围捕-觅食行为控制方法,包括以下步骤:1)对多Agent和猎物当前所处位置形成的状态空间进行划分;2)设计奖赏函数;3)根据步骤1)划分的状态空间及步骤2)的奖赏函数进行强化学习,控制各Agent进行相应的原子动作,实现对猎物的围捕,在满足围捕成功条件时停止,达到觅食效果。所述步骤1)中,对状态空间的划分具体为:101)将n个Agent与猎物之间的角度进行划分;102)将各Agent与猎物之间的距离进行离散分段。所述将Agent与猎物之间的角度进行划分具体为:将两个Agent与猎物之间的夹角划分为如下表的10个状态所述划分为非均匀状态划分,所述离散分段为非均匀划分。所述步骤2)中,奖赏函数R为:R=a*J+rn其中,J为角度奖赏,J=G(θ)left+G(θ)right,G(θ)left为某一Agent的左夹角θleft对应的角度奖赏,G(θ)right为该Agent的右夹角θright对应的角度奖赏,rn为距离奖赏,a为J与rn之间的相对重要程度系数。每个角度θ对应的角度奖赏表达式为:所述距离奖赏rn通过以下表格获取:d0~0.5m0.5~1.0m0.5~1.4m1.4~2.0m2.0~3.5m3.5~5.0m>5.0mrn1.21.11.00.70.50.20其中,d表示Agent与猎物之间的距离。所述相对重要程度系数a在形成围捕包围圈与收缩包围圈两个任务中取值不同。所述原子动作包括朝向猎物、向左偏π/4、向右偏π/4、向左偏π/2以及向右偏π/2。所述围捕成功条件为:同时存在a)猎物位于多Agent组成的凸平面内;b)所有Agent与猎物之间形成的最大角度满足:其中,θstr为允许的包围角误差;c)所有Agent与猎物之间形成的最大距离dm满足:dm≤Dstr其中,Dstr为允许距离。与现有技术相比,本发明具有以下优点:1、本发明基于强化学习实现多Agent围捕-觅食,每个参与围捕的机器人可以通过知道自己相对整个群体的位置以及整个群体相对猎物的位置快速学习到该如何运动才能围捕到逃跑的个体,提高围捕效率。2、本申请对状态空间进行了划分,巧妙地设计了动作与奖赏函数,使得学习过程能够在合理的时间收敛。3、本申请进行状态空间划分时采用非均匀划分,有效提高精度和减小状态空间。附图说明图1是状态划分示意图;图2是奖赏函数示意图;图3是围捕条件示意图;图4是围捕初始环境示意图;图5是训练初期轨迹图,其中,(5a)为一种初期轨迹图,(5b)为另一种初期轨迹图;图6是训练初期追捕成功示意图,其中,(6a)为一种追捕成功示意图,(6b)为另一种追捕成功示意图;图7是训练后期形成包围图;图8是训练后期保持包围图。具体实施方式下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。本实施例提供一种多Agent围捕-觅食行为控制方法,该方法基于强化学习算法,并设置了奖赏函数,提高机器人的学习效率。在利用Option方法改进的强化学习算法进行多Agent围捕时需要首先对状态空间进行离散化,多Agent的围捕问题中每个参与围捕的机器人需要知道自己相对整个群体的位置以及整个群体相对猎物的位置才能根据这些信息学习到该如何运动才能围捕到逃跑的个体。本发明方法包括以下步骤:1)对多Agent(机器人)和猎物当前所处位置形成的状态空间进行划分;2)设计奖赏函数;3)根据步骤1)划分的状态空间及步骤2)的奖赏函数进行强化学习,控制各Agent进行相应的原子动作,实现对猎物的围捕,在满足围捕成功条件时停止,达到觅食效果。1、状态空间划分与动作选择对于状态空间的划分必须能够反映某个Agent与群体之间的位置关系,还应反映出个体与猎物之间的位置关系,这里设计了一种能够反映出围捕程度的状态空间划分:将各机器人与猎物之间的角度进行分割,为了节省状态空间加快收敛速度,采用非均匀状态划分。本发明将两个机器人与猎物之间的夹角划分为10个状态:表1角度划分注:其中j为left或right,i为Agent序号。本实施例选用4个机器人进行联合围捕,而围捕的最佳情况就是4个机器人均匀分布在猎物周围360°的范围内,故每个机器人与和它相邻的机器人之间的夹角最佳为90°。在围捕过程中由于猎物的智能性以及猎物自身的高速性,包围圈细微的漏洞都可能使猎物逃脱,因此对于在90°附近的状态空间需要做出细致的划分。但是当猎物处于包围圈外时,会出现相邻机器人之间的角度大于180°的情况,此时机器人需要移动使猎物首先进入包围圈的凸平面,因此对于角度的要求没有那么苛刻。本发明将大于180°的情况设为一种状态即是考虑了减小状态空间来加速收敛过程。如图1所示,为了确定每个Agent相对整体的位置,即包围情况,必须使用左右两个相邻角度来定位某个机器人所处的位置。对于Agenti来说知道了左右两个夹角θleft和θright就可以知道自身所处的位置与包围情况之间的关系,从而选择合适的动作来更严密地包围猎物。夹角θleft和θright划分如表1所示,各有10种状态,因此整个角度划分共有10×10=100个状态。只知道角度对于捕捉到猎物来说是不够的,还需要能够反映机器人与猎物之间的位置关系。将机器人与猎物之间的距离离散为7段,同样处于加大精度和减小状态空间的做法,这里采用非均匀划分:表2距离划分di0~0.5m0.5~1.0m0.5~1.4m1.4~2.0m2.0~3.5m3.5~5.0m>5.0m注:其中di为第i个Agent到猎物的距离。这样一来每个机器人的状态空间都是由自身与猎物之间的包围位置关系(共100个状态:左边角度10个×右边角度10个)×自身与猎物之间的位置关系(共7个状态)=700个状态组成。由于这样的策略既表示了自身的位置关系,又反映了团体的包围信息,故不论Agent的数量如何增多,状态空间不会再增长,由此便解决了维数灾难问题。在动作选择方面我们回归到机器人的原子动作,即将Agent的动作分为朝向猎物,向左偏π/4,向右偏π/4,向左偏π/2,向右偏π/2这五种。通常状况下动作还应该包括与朝向猎物相反的四个方向,但由于边界条件的限制,向后的动作很容易自使系统陷入死区,严重降低收敛速度。2、奖赏函数的设计强化学习中另一个难点就是奖赏函数的设计,只有恰当的设置奖赏函数,算法才能收敛。通常情况下奖赏函数设定为在吸收态给予较大的立即奖赏,而其他状态设定为0。这样可以使得Agent自主学习到完成目标的策略。然而由于本发明的任务较为复杂,如果仅仅采用吸收态奖赏的方案可能会使算法的收敛时间变的很长,这里引入过程奖赏的概念。所谓过程奖赏与吸收态奖赏可形象的比喻如下:吸收态奖赏就像远古人类在围猎时只根据能否捕到猎物来判断自己策略的好坏;而过程奖赏就好像现代人类将自己的知识传授给下一代的过程,即不仅仅看结果的好坏,更重要的是学习的过程中每一步是否到位。在本发明中,将整个围捕过程分为三个大的部分,即漫游寻找、围捕和运送,漫游寻找属于随机过程,运送属于确定过程,因此重点研究围捕过程,即发现目标时多Agent如何快速成功的将其围捕。对于围捕过程大致可分为两个Option,即形成包围圈与缩小包围圈。对不同过程的设置不同的奖赏函数是整个算法收敛的关键。在形成包围圈阶段,每个机器人首先计算自己的θleft与θright,并依据下式计算每个θ的奖赏:分别将θleft与θright的奖赏值记作G(θ)left和G(θ)right,则总的角度奖赏为:J=G(θ)left+G(θ)right(2)另一方面,还需要根据个体和猎物之间的距离定义奖赏函数来激励机器人靠近目标:表3距离奖赏函数d0~0.5m0.5~1.0m0.5~1.4m1.4~2.0m2.0~3.5m3.5~5.0m>5.0mrn1.21.11.00.70.50.20所以,总奖赏函数R为:R=a*J+rn(3)其中,a为J与rn之间的相对重要程度系数,在形成围捕与收缩包围圈两个任务中并不相同。本实施例中设定:当处于形成包围圈时,a为2,当处于收缩时,a为1。另外,当围捕成功时,给予额外立即奖赏10。3、围捕成功条件机器人对于猎物的围捕成功条件定义为:1)猎物位于机器人组成的凸平面内(这里严格限定为凸平面,凹平面尚不足以围捕)。2)所有机器人与猎物之间形成的最大角度满足如下条件:其中θstr为允许的包围角误差。3)机器人与猎物之间形成的最大距离dm满足如下条件:dm≤Dstr(5)其中Dstr为允许距离。图4给出了在有障碍物的情况下围捕任务的初始界面。图5为在学习过程的初期机器人的轨迹图,由图可以看到在初期机器人的轨迹凌乱,并没有能够形成对猎物的围捕,大多数情况下都是集体在追逐猎物。图6为训练初期在捕捉到猎物时的图像,在训练初期机器人在捕捉猎物时都是将猎物逼到墙角(如图中的右下角和左上角),这样的捕捉在本实验中被认为是无效的,因为实际的应用中(如公海缉私和导弹防御),环境是开放的且不存在边界。因此训练的目的是将高速运动的物体在仿真环境中间围住。如图7为经过成百次的训练后机器人在无障碍物的情况下的围捕情况。由图可见经过大量的迭代训练,机器人形成围捕的非常迅速,没有了训练初期凌乱的网络,而是直奔主题,对目标形成包围。图8为训练后期再形成包围圈之后保持包围的图像,形成包围之后由于猎物也具有一定的智能性,故如果不能保持住包围圈,则猎物又可能突破包围。从图8可看出,不论猎物采取什么方向逃跑,机器人总是能够及时的调整队形,包围住猎物,所以其轨迹如同圆形一般,将猎物牢牢地包围在中间。以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本
技术领域:
中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1