一种基于相异性递归消除特征的故障诊断方法及装置与流程
本发明涉及故障诊断领域,更具体地说,涉及一种基于相异性递归消除特征的故障诊断方法及装置。
背景技术:
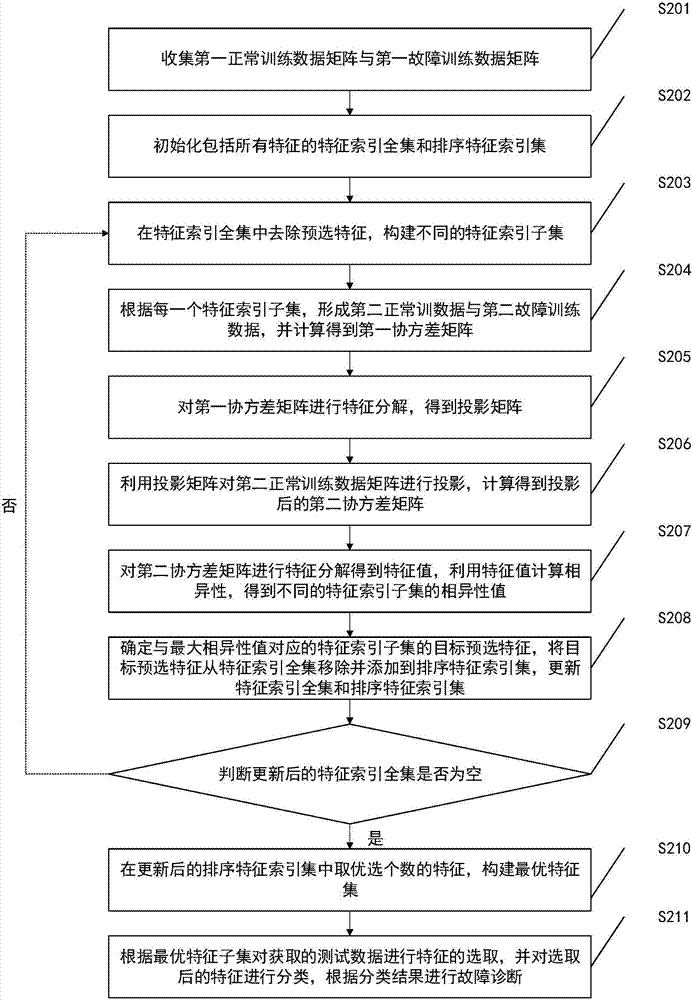
:现代工业系统十分复杂,对于其监控的过程中就会产生大量的监控数据,当系统检测到故障时,就要对故障数据进行分析,找出产生故障的部件和原因。但是由于数据数量庞大,如何从中挖掘出有价值的数据并加以利用成为一个十分重要的事情。一般情况下,故障数据与正常数据的差别可能只是由于几个关键特征引导的,如果可以甄别出这些导致差别的关键特征,就可以找到解决故障的方法。因此,特征选择在故障诊断领域中受到越来越多的重视,特征选择方法可以对大量数据进行筛选,得到特征子集,随后就可以对特征子集进行分类,识别出故障及故障的类型,完成故障诊断。但是现有的传统特征选择方法通常避免不了处理非线性、非高斯以及大规模复杂的数据,导致了特征选择的复杂性,无法准确找出与故障相关的特征子集,因此影响了后续分类结果的不准确。因此,如何准确找出与故障相关的特征,减少不相关特征对故障诊断的影响,是本领域技术人员需要解决的问题。技术实现要素:本发明的目的在于提供一种基于相异性递归消除特征的故障诊断方法及装置以准确找出与故障相关的特征,减少不相关特征对故障诊断的影响。为实现上述目的,本发明实施例提供了如下技术方案:一种基于相异性递归消除特征的故障诊断方法,包括:s101:收集第一正常训练数据矩阵与第一故障训练数据矩阵;s102:初始化包括所有特征的特征索引全集和排序特征索引集;s103:在所述特征索引全集中去除预选特征,构建不同的特征索引子集;s104:根据每一个特征索引子集,形成第二正常训练数据矩阵与第二故障训练数据矩阵,并计算相异性,得到不同的特征索引子集的相异性值;s105:确定与最大相异性值对应的特征索引子集的目标预选特征,将所述目标预选特征从所述特征索引全集移除并添加到所述排序特征索引集,更新所述特征索引全集和所述排序特征索引集;s106:判断更新后的特征索引全集是否为空,若否,则返回s103;若是,进行s107;s107:在更新后的排序特征索引集中取优选个数的特征,构建最优特征集;s108:根据所述最优特征子集对获取的测试数据进行特征的选取,并对选取后的特征进行分类,根据分类结果进行故障诊断。优选地,所述收集第一正常训练数据矩阵与第一故障训练数据矩阵,包括:收集第一正常训练数据矩阵与第一故障训练数据矩阵,并进行标准化处理。优选地,所述根据每一个特征索引子集,形成第二正常训练数据矩阵与第二故障训练数据矩阵,并计算相异性,得到不同的特征索引子集的相异性值,包括:根据每一个特征索引子集,形成第二正常训练数据矩阵与第二故障训练数据矩阵,并计算得到第一协方差矩阵;对所述第一协方差矩阵进行特征分解,得到投影矩阵;利用所述投影矩阵对所述第二正常训练数据矩阵进行投影,计算得到投影后的第二协方差矩阵;对所述第二协方差矩阵进行特征分解得到特征值,利用所述特征值计算相异性,得到不同的特征索引子集的相异性值。优选地,所述在更新后的排序特征索引集中取优选个数的特征,构建最优特征集,包括:采用支持向量机分类器在训练数据上进行10折交叉验证,得到优选个数;在所述排序特征索特引集中取出所述优选个数的特征,构建最优特征子集。优选地,根据所述最优特征子集对获取的测试数据进行特征的选取,并对选取后的特征进行分类,根据分类结果进行故障诊断,包括:收集测试数据,并进行标准化处理;根据所述最优特征子集对所述测试数据进行特征的选取,并对选取后的特征用支持向量机进行分类,根据分类结果进行故障诊断。优选地,所述训练数据收集模块具体用于收集第一正常训练数据矩阵与第一故障训练数据矩阵,并进行标准化处理。优选地,所述相异性值计算模块,包括:第一协方差矩阵计算单元,用于根据每一个特征索引子集,形成第二正常训练数据矩阵与第二故障训练数据矩阵,并计算得到第一协方差矩阵;投影矩阵计算单元,用于对所述第一协方差矩阵进行特征分解,得到投影矩阵;第二协方差矩阵计算单元,用于利用所述投影矩阵对所述第二正常训练数据矩阵进行投影,并计算得到投影后的第二协方差矩阵;相异性值计算单元,用于对所述第二协方差矩阵进行特征分解得到特征值,利用所述特征值计算相异性,得到不同的特征索引子集的相异性值。优选地,所述最优特征集构建模块,包括:优选个数确定单元,用于采用支持向量机分类器在训练数据上进行10折交叉验证,得到优选个数;最优特征子集构建单元,用于在所述排序特征索引集中去除所述优选个数的特征,构建最优特征子集。优选地,所述故障诊断模块,包括:测试数据收集单元,用于收集测试数据,并进行标准化处理;故障诊断单元,用于根据所述最优特征子集对所述测试数据进行特征的选取,并对选取后的特征进行分类,根据分类结果进行故障诊断。通过以上方案可知,本发明实施例提供的一种基于相异性递归消除特征的故障诊断方法,通过对同一特征子集计算相异性,并比较每个特征造成的相异性,对特征值按照其对应的相异性也就是造成两个数据集之间的差异进行排序,得到排序后的特征索引子集,再通过优选个数得到关键特征个数,就可以在排序后的特征子集中取出相应个数的关键特征。因此本方法是考虑的是整个数据集之间的相异性,不要求过程是线性的或高斯的,因此在非线性和高斯的过程上有较好的结果,降低计算复杂度,同时可以准确的找出符合要求的最优特征子集减少了不相关特征对故障诊断的影响。本发明还提供一种基于相异性递归消除特征的故障诊断装置,同样能实现上述技术效果。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例公开的一种故障诊断方法流程图;图2为本发明实施例公开的一种具体的故障诊断方法流程图;图3为本发明实施例公开的一种故障诊断装置结构示意图;图4为本发明实施例公开的一种具体的相异性值计算模块结构示意图;图5为本发明实施例公开的一种故障诊断方法与svm对故障21诊断的监控结果对比图;图6为本发明实施例公开的一种故障诊断方法与dsbs-svm对故障21诊断的监控结果对比图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明实施例公开了一种基于相异性递归消除特征的故障诊断方法。参见图1,本发明实施例提供的一种基于相异性递归消除特征的故障诊断方法,包括:s101:收集第一正常训练数据矩阵与第一故障训练数据矩阵;具体地,收集工业过程中的正常训练数据矩阵和故障数据矩阵,分别作为第一正常训练数据矩阵和第一故障训练数据矩阵。s102:初始化包括所有特征的特征索引全集和排序特征索引集;具体地,初始化包括所有特征的集合,即特征索引全集,并初始化排序特征索引集,排序特征索引集是用于存放按照特征对应的相异性值大小进行排序后的特征,此时排序特征索引集为空,没有特征。s103:在所述特征索引全集中去除预选特征,构建不同的特征索引子集;需要说明的是,预选特征是特征索引全集中的任意一个特征,根据每一个特征,构建出不同的对应每一个特征的索引子集。s104:根据每一个特征索引子集,形成第二正常训练数据矩阵与第二故障训练数据矩阵,并计算相异性,得到不同的特征索引子集的相异性值;需要说明的是,每去除一个预选特征,会在特征索引全集中减去这个特征构建成一个新的特征索引子集,对应这个特征索引子集,计算出新的正常训练数据矩阵和故障数据矩阵,作为第二正常训练数据矩阵和第二故障数据矩阵。第二正常训练数据矩阵和第二故障数据矩阵,计算出相异性值,这个相异性值就是针对这个新的特征索引子集的相异性值,也就是说是本次去除的预选特征造成的相异性。s105:确定与最大相异性值对应的特征索引子集的目标预选特征,将所述目标预选特征从所述特征索引全集移除并添加到所述排序特征索引集,更新所述特征索引全集和所述排序特征索引集;需要说明的是,相异性值越大说明去除预选特征后的第二正常训练数据矩阵与第二故障数据矩阵的差异越大,从而表明去除的这个预选特征对两种数据的差异影响越小。因此,对本次计算的每一个去除预选特征后的特征索引子集的相异性值进行比较,从特征索引全集中取出最大相异性值对应的预选特征,并将这个预选特征放到排序特征索引集中。s106:判断更新后的特征索引全集是否为空,若否,则返回s103;若是,进行s107;具体地,判断去除预选特征后的特征索引全集是否还有特征,如果有则再次在特征索引全集中选一个预选特征,返回s103进行循环;如果特征索引全集为空,则说明排序特征索引集已包括了所有按照相异性排序后的特征,则进行s107。s107:在更新后的排序特征索引集中取优选个数的特征,构建最优特征集;需要说明的是,一般状态下,只有几个关键特征引导着正常数据与故障数据之间的差异,因此可以通过现有分类方法确定出关键特征的优选个数,再根据优选个数从排序特征索引集中取出排序后的相应个数的特征就是关键特征,构建的集合即最优特征集。s108:根据所述最优特征子集对获取的测试数据进行特征的选取,并对选取后的特征进行分类,根据分类结果进行故障诊断。具体地,收集工业过程中的测试数据,根据最优特征集进行测试数据特征的选取,然后对选取的特征进行分类,将选取的特征分为正常数据和故障数据,从而判断测试数据是否有故障,即如果该测试数据是故障数据,则说明发生故障。因此,本发明实施例提供的方法通过对同一特征子集计算相异性,并比较每个特征造成的相异性,对特征值按照其对应的相异性也就是造成两个数据集之间的差异进行排序,得到排序后的特征索引子集,再通过优选个数得到关键特征个数,就可以在排序后的特征子集中取出相应个数的关键特征。因此本方法是考虑的是整个数据集之间的相异性,不要求过程是线性的或高斯的,因此在非线性和高斯的过程上有较好的结果,降低计算复杂度,同时可以准确的找出符合要求的最优特征子集减少了不相关特征对故障诊断的影响。本发明还提供一种基于相异性递归消除特征的故障诊断装置,同样能实现上述技术效果。本发明实施例公开了一种具体的基于相异性递归消除特征的故障诊断方法,区别于上一实施例,本发明实施例对s101做了具体地限定,其他步骤内容与上一实施例大致相同,详细内容可以参见上一实施例对应的部分,此处不再赘述。具体地s101包括:收集第一正常训练数据矩阵与第一故障训练数据矩阵,并进行标准化处理。需要说明的是,本发明中使用的训练数据均为标准化处理后的数据,通过对训练数据进行标准化处理,使得数据更为紧凑,可以避免一些数据值过大或过小而被认为是噪声数据或是关键数据,从而降低这些数据造成的实验误差,提高了优选特征选择结果的精度。本发明实施例公开了一种具体的基于相异性递归消除特征的故障诊断方法,区别于上一实施例,本发明实施例对s107做了具体地限定,其他步骤内容与上一实施例大致相同,详细内容可以参见上一实施例对应的部分,此处不再赘述。具体地s107包括:采用支持向量机分类器在训练数据上进行10折交叉验证,得到优选个数;需要说明的是,支持向量机作为一种推广能力较好的分类器,已被广泛应用到故障诊断领域中,通过支持向量机分类器在训练数据上进行10折交叉验证,可以得到优选特征的个数,这个个数就是优选的关键特征个数,在所述排序特征索特引集中取出所述优选个数的特征,构建最优特征子集。具体地,根据优选个数从排序特征索引集中取出排序后的相应个数的特征就是关键特征,构建的集合即最优特征集。本发明实施例公开了一种具体的于相异性递归消除特征的故障诊断方法,区别于上一实施例,本发明实施例对s108做了具体地限定,其他步骤内容与上一实施例大致相同,详细内容可以参见上一实施例对应的部分,此处不再赘述。具体地s108包括:收集测试数据,并进行标准化处理;需要说明的是,本发明使用的测试数据均为标准化处理后的数据,对于收集到的工业过程中的测试数据,同样进行标准化处理,使得测试数据更为紧凑,降低实验误差。根据所述最优特征子集对所述测试数据进行特征的选取,并对选取后的特征用支持向量机进行分类,根据分类结果进行故障诊断。在本方案中,采用支持向量机对选取的特征进行分类,根据分类结果进行故障选择。具体地,收集工业过程中的测试数据,根据最优特征集进行测试数据特征的选取,然后对选取的特征采用支持向量机进行分类,将选取的特征分为正常数据和故障数据,从而判断测试数据是否有故障,即如果该测试数据是故障数据,则说明发生故障。因此,采用支持向量机对标准化处理后的测试数据选取出的特征进行分类识别,进一步提高了分类的精度。本发明实施例公开了一种具体的基于相异性递归消除特征的故障诊断方法,相对于上一实施例,本发明实施例对技术方案做了进一步的说明和优化,参见图2,本发明实施例提供的一种基于相异性递归消除特征的故障诊断方法,包括:s201:收集第一正常训练数据矩阵与第一故障训练数据矩阵;具体地,收集工业过程中的正常训练数据矩阵和故障数据矩阵分别作为第一正常训练数据矩阵和第一故障训练数据矩阵,其中是正常数据,是故障数据,n1和n2分别是正常训练数据和故障训练数据的样本数,m是特征个数。可以通过上述实施例的方法对数据进行标准化处理,使得数据更紧凑,减小实验误差,标准化公式为其中为正常训练数据第j个特征的均值,σ1j为正常训练数据第j个特征的标准差。s202:初始化包括所有特征的特征索引全集和排序特征索引集;具体地,初始化包括所有特征的集合,即特征索引全集s={1,2,...,m},并初始化排序后的特征索引集,即排序特征索引集排序特征索引集是用于存放按照特征对应的相异性值大小进行排序后的特征,此时排序特征索引集为空,没有特征。s203:在所述特征索引全集中去除预选特征,构建不同的特征索引子集;需要说明的是,预选特征是特征索引全集中的任意一个特征p,根据每一个预选特征p,构建出不同的对应每一个预选特征p的特征索引子集sp={1,2,...,p-1,p+1,...,m}。s204:根据每一个特征索引子集,形成第二正常训数据与第二故障训练数据,并计算得到第一协方差矩阵;需要说明的是,对应特征索引子集sp={1,2,...,p-1,p+1,...,m},计算出新的正常训练数据矩阵x1p=[x11,x12,...,x1(p-1),x1(p+1),...,x1m]和故障数据矩阵x2p=[x21,x22,...,x2(p-1),x2(p+1),...,x2m],作为第二正常训练数据矩阵和第二故障数据矩阵。通过计算第二正常训练数据矩阵和第二故障数据矩阵,计算得到协方差矩阵从而进一步得到联合协方差矩阵作为第一协方差矩阵。s205:对第一协方差矩阵进行特征分解,得到投影矩阵;具体地,通过对第一协方差矩阵rp进行特征分解,得到特征向量和特征值,特征向量为一个正交化矩阵p0,特征值为对角化矩阵λ,满足rpp0=p0λ,从而得到投影矩阵p=p0λ-1/2。s206:利用所述投影矩阵对所述第二正常训练数据矩阵进行投影,计算得到投影后的第二协方差矩阵;利用所述投影矩阵对所述第二正常训练数据x1p矩阵进行投影,得到新投影矩阵根据新投影矩阵进行计算,得到第二协方差矩阵s1p。s207:对所述第二协方差矩阵进行特征分解得到特征值,利用所述特征值计算相异性,得到不同的特征索引子集的相异性值。具体地,对第二协方差矩阵进行特征分解,得到特征值λ1k,并根据特征值计算出相异性diss(x1p,x2p),相异性值用dp来表示:这个相异性值就是针对这个新的特征索引子集的相异性值,也就是说是本次去除的预选特征造成的相异性。s208:确定与最大相异性值对应的特征索引子集的目标预选特征,将所述目标预选特征从所述特征索引全集移除并添加到所述排序特征索引集,更新所述特征索引全集和所述排序特征索引集;需要说明的是,相异性值dp越大说明去除预选特征后的第二正常训练数据矩阵与第二故障数据矩阵的差异越大,从而表明去除的这个预选特征p对两种数据的差异影响越小。因此,对本次计算的每一个去除预选特征后的特征索引子集的相异性值进行比较,从特征索引全集中取出最大相异性值对应的预选特征,并将这个预选特征放到排序特征索引集中,即更新特征集s和r:s←s-{p},r←r∪{p}。s209:判断更新后的特征索引全集是否为空,即是否成立,若否,则返回s203;若是,进行s210;具体地,判断去除预选特征后的特征索引全集是否还有特征,如果有则再次在特征索引全集中选一个预选特征,返回s203进行循环;如果特征索引全集为空,则说明排序特征索引集已包括了所有按照相异性排序后的特征,则进行s210。s210:在更新后的排序特征索引集中取优选个数的特征,构建最优特征集;需要说明的是,一般状态下,只有几个关键特征引导着正常数据与故障数据之间的差异,因此可以通过现有分类方法确定出关键特征的优选个数,再根据优选个数从排序特征索引集中取出排序后的相应个数的特征就是关键特征,构建的集合即最优特征集f。s211:根据所述最优特征子集对获取的测试数据进行特征的选取,并对选取后的特征进行分类,根据分类结果进行故障诊断。具体地,获取实时收集工业过程的测试数据(m为特征个数),并可以按照上述实施例介绍的方法将数据标准化,使数据更紧凑,减小,标准化公式为根据最优特征子集f对获取的测试数据进行特征的选取,并对选取后的特征进行分类,将选取的特征分为正常数据和故障数据,从而判断测试数据是否有故障,即如果该测试数据是故障数据,则说明发生故障。因此,本发明实施例提供的方法通过对同一特征子集计算相异性,并比较每个特征造成的相异性,对特征值按照其对应的相异性也就是造成两个数据集之间的差异进行排序,得到排序后的特征索引子集,再通过优选个数得到关键特征个数,就可以在排序后的特征子集中取出相应个数的关键特征。因此本方法是考虑的是整个数据集之间的相异性,不要求过程是线性的或高斯的,因此在非线性和高斯的过程上有较好的结果,降低计算复杂度,同时可以准确的找出符合要求的最优特征子集减少了不相关特征对故障诊断的影响。本发明还提供一种基于相异性递归消除特征的故障诊断装置,同样能实现上述技术效果。下面对本发明提供的一种基于相异性递归消除特征的故障诊断装置进行介绍,可以与上文中的一种基于相异性递归消除特征的故障诊断方法相互参考。参见图3,对本发明实施例提供一种基于相异性递归消除特征的故障诊断装置,包括:训练数据收集模块301,用于收集第一正常训练数据矩阵与第一故障训练数据矩阵;具体地,训练数据模块301收集工业过程中的正常训练数据和故障训练数据矩阵,作为第一正常训练数据矩阵和第一故障数据矩阵。初始化模块302,用于初始化包括所有特征的特征索引全集和排序特征索引集;具体地,初始化模块302对初始化包括所有特征的集合,即初始化特征索引集,并且对排序特征索引集也进行初始化,排序特征索引集是存放按照特征对应的相异性值大小进行排序后的特征,此时排序特征索引集为空,即没有特征。特征索引子集构建模块303,用于在所述特征索引全集中去除预选特征,构建不同的特征索引子集;需要说明的是,预选特征可以是特征索引全集中的任意一个特征,在特征索引全集中去除每一个预选特征后,构建对应每一个预选特征的特征索引子集,即特征索引子集为特征索引全集减去预选特征。相异性值计算模块304,用于根据每一个特征索引子集,形成第二正常训练数据矩阵与第二故障训练数据矩阵,并计算相异性,得到不同的特征索引子集的相异性值;需要说明的是,每去除一个预选特征,会在特征索引全集中减去找个预选特征,构建成一个新的特征索引子集,对应这个特征索引子集,计算出新的正常训练数据矩阵和故障训练数据矩阵,作为第二正常训练数据矩阵和第二故障训数据矩阵。根据第二正常训练数据矩阵和第二故障训练数据矩阵计算出相异性值,这个相异性值就是针对新的特征索引子集的相异性值,也就是说是本次去除的预选特征造成的相异性。排序特征索引集更新模块305,用于确定与最大相异性值对应的特征索引子集的目标预选特征,将所述目标预选特征从所述特征索引全集移除并添加到所述排序特征索引集,更新所述特征索引全集和所述排序特征索引集;具体地,排序特征索引集更新模块305先对最大相异性值对应的特征索引子集的目标预选特征进行确定,相异性值越大说明去除预选特征后的第二正常训练数据矩阵与第二故障训练数据矩阵的差异越大,从而表明去除的这个预选特征对两种数据的差异影响越小。因此,对本次计算的每一个去除预选特征后的特征索引子集的相异性进行比较,从特征索引全集中去除最大相异性值对应的预选特征,并将这个预选特征放到排序特征索引集中。判断模块306,用于判断更新后的特征索引全集是否为空,若否,则调用所述特征索引子集构建模块303;若是,则调用所述最优特征集构建模块307;具体地,判断模块306对更新后的特征索引全集进行判断,判断其是否为空,即判断更新后的特征索引全集是否还有特征,如果有则再次在特征索引全集中选一个预选特征,调用特征索引子集构建模块303,如果特征索引全集为空,则说明所有特征已按对应的相异性值大小存放到排序特征索引集中,因此调用最优特征集构建模块307。所述最优特征集构建模块307,用于在更新后的排序特征索引集中取优选个数的特征,构建最优特征集;需要说明的是,一般状态下,只有几个关键特征引导着正常数据与故障数据之间的差异,因此最优特征集构建模块307可以通过现有分类方法确定出关键特征的优选个数,再根据优选个数从排序特征索引集中取出排序后的相应个数的特征就是关键特征,构建的集合即最优特征集。故障诊断模块308,用于根据所述最优特征子集对获取的测试数据进行特征的选取,并对选取后的特征进行分类,根据分类结果进行故障诊断。具体地,故障诊断模块308收集工业过程中的测试数据,根据最优特征集进行特征的选取,然后对选取的特征进行分类,将选取的特征分为正常数据和故障数据,从而判断测试数据是否有故障,即如果该测试数据是故障数据,则说明发生故障。因此,本发明实施例提供的故障诊断装置,通过相异性值计算模块304对同一特征子集计算相异性,并通过排序特征索引集更新模块305比较每个特征造成的相异性,对特征值按照其对应的相异性也就是造成两个数据集之间的差异进行排序,得到排序后的排序特征索引集,再通过最优特征集构建模块307得到优选个数得到关键特征个数,就可以在排序特征索引集中取出相应个数的关键特征。因此本方法是考虑的是整个数据集之间的相异性,不要求过程是线性的或高斯的,因此在非线性和高斯的过程上有较好的结果,降低计算复杂度,同时可以准确的找出符合要求的最优特征子集减少了不相关特征对故障诊断的影响。本发明还提供一种基于相异性递归消除特征的故障诊断装置,同样能实现上述技术效果。下面对本发明提供的一种具体的基于相异性递归消除的故障诊断装置,可以与上文描述的一种具体的基于相异性递归消除的故障诊断方法相互参考。本发明提供了一种具体的基于相异性递归消除的故障诊断装置,区别上一实施例,本发明实施例对训练数据收集模块301做了进一步的限定,其他内容与上一实施例与上一实施例大致相同,详细内容可以参见上一实施例对应的部分,此处不再赘述。上述实施例的训练数据收集模块301具体用于:收集第一正常训练数据矩阵与第一故障训练数据矩阵,并进行标准化处理。需要说明的是,对训练数据进行标准化处理,使得数据更为紧凑,可以避免一些数据值过大或过小而被认为是噪声数据或是关键数据,从而降低这些数据造成的实验误差,提高了优选特征选择结果的精度。本发明提供了一种具体的基于相异性递归消除的故障诊断装置,区别上述实施例,本发明实施例相异性值计算模块304做了进一步的限定,其他内容与上一实施例与上一实施例大致相同,详细内容可以参见上一实施例对应的部分,此处不再赘述。参见图4,上述实施例的相异性值计算模块304具体包括:第一协方差矩阵计算单元304a,用于根据每一个特征索引子集,形成第二正常训练数据矩阵与第二故障训练数据矩阵,并计算得到第一协方差矩阵。需要说明的是,每去除一个预选特征,会在特征索引全集中减去这个特征构建成一个新的特征索引子集,第一协方差矩阵计算单元304a对应这个特征索引子集,计算出新的正常训练数据矩阵和故障数据矩阵,作为第二正常训练数据矩阵和第二故障数据矩阵。进一步通过计算第二正常训练数据矩阵和第二故障数据矩阵,计算得到协方差矩阵,从而进一步得到联合协方差矩阵,作为第一协方差矩阵。投影矩阵计算单元304b,用于对所述第一协方差矩阵进行特征分解,得到投影矩阵。具体地,投影矩阵计算单元304b通过对第一协方差矩阵进行特征分解,得到特征向量和特征值,特征向量为一个正交化矩阵p0,特征值为对角化矩阵λ,满足rpp0=p0λ,从而得到投影矩阵p=p0λ-1/2。第二协方差矩阵计算单元304c,用于利用所述投影矩阵对所述第二正常训练数据矩阵进行投影,并计算得到投影后的第二协方差矩阵。具体地,第二协方差矩阵计算单元304c利用所述投影矩阵对所述第二正常训练数据矩阵进行投影,得到新投影矩阵,根据新投影矩阵进行计算,得到第二协方差矩阵。相异性值计算单元304d,用于对所述第二协方差矩阵进行特征分解得到特征值,利用所述特征值计算相异性,得到不同的特征索引子集的相异性值。具体地,相异性值计算单元304d对第二协方差矩阵进行特征分解,得到特征值,并根据特征值计算出相异性值,这个相异性值就是针对这个新的特征索引子集的相异性值,也就是说是本次去除的预选特征造成的相异性。因此可以通过本实施例提供的具体的相异性值计算模块可以实现对同一特征子集计算相异性,并通过排序特征索引集更新模块305比较每个特征造成的相异性,对特征值按照其对应的相异性也就是造成两个数据集之间的差异进行排序,得到排序后的排序特征索引集,再通过最优特征集构建模块307得到优选个数得到关键特征个数,就可以在排序特征索引集中取出相应个数的关键特征。因此本方法是考虑的是整个数据集之间的相异性,不要求过程是线性的或高斯的,因此在非线性和高斯的过程上有较好的结果,降低计算复杂度,同时可以准确的找出符合要求的最优特征子集减少了不相关特征对故障诊断的影响。本发明还提供一种基于相异性递归消除特征的故障诊断装置,同样能实现上述技术效果。本发明提供了一种具体的基于相异性递归消除的故障诊断装置,区别上一实施例,本发明实施例对所述最优特征集构建模块307做了进一步的限定,其他内容与上一实施例与上一实施例大致相同,详细内容可以参见上一实施例对应的部分,此处不再赘述。上述实施例的所述最优特征集构建模块307具体包括:优选个数确定单元307a,用于采用支持向量机分类器在训练数据上进行10折交叉验证,得到优选个数;需要说明的是,支持向量机作为一种推广能力较好的分类器,已被广泛应用到故障诊断领域中,优选个数确定单元307a通过支持向量机分类器在训练数据上进行10折交叉验证,可以得到优选特征的个数,这个个数就是优选的关键特征个数。最优特征子集构建单元307b,用于在所述排序特征索引集中去除所述优选个数的特征,构建最优特征子集。具体地,最优特征子集构建单元307b根据优选个数从排序特征索引集中去除所述优选个数的特征,构建最优特征子集。本发明提供了一种具体的基于相异性递归消除的故障诊断装置,区别上一实施例,本发明实施例对所述故障诊断模块308做了进一步的限定,其他内容与上一实施例与上一实施例大致相同,详细内容可以参见上一实施例对应的部分,此处不再赘述。上述实施例的所述故障诊断模块308具体包括:测试数据收集单元308a,用于收集测试数据,并进行标准化处理。需要说明的是,测试数据收集单元308a对收集到的工业过程中的测试数据进行标准化处理,使得测试数据更为紧凑,降低实验误差。故障诊断单元308b,用于根据所述最优特征子集对所述测试数据进行特征的选取,并对选取后的特征进行分类,根据分类结果进行故障诊断。在本方案中,故障诊断单元308b根据所述最优特征子集对所述测试数据进行特征的选取,并对选取后的特征用支持向量机进行分类,将选取的特征分为正常数据和故障数据,从而判断测试数据是否有故障,即如果该测试数据是故障数据,则说明发生故障。因此,采用支持向量机对标准化处理后的测试数据选取出的特征进行分类识别,进一步提高了分类的精度。本发明公开了一种基于相异性递归消除特征的故障诊断方法,具体包括:本实例在以本发明技术方案为前提下进行本发明在田纳西伊斯曼过程(tennessee-eastmanprocess,tep)数据集上进行了测试。tep数据集中包含正常数据集和21种不同故障的数据集。对于每一种故障,训练集有480个故障数据,测试集有960个观测数据组成,每个观测数据包含52个变量,测试集的数据以正常数据开始,到第161次采样出现故障,所有的数据每隔3分钟采样一次,所有数据均由tep仿真软件生成。我们取正常数据集中的500个训练数据和一种故障的480个训练数据作为训练集的输入,对每种故障的测试集进行故障检测。具体实施步骤如下:训练模块:s401,收集工业过程中的第一正常训练数据矩阵和第一故障训练数据矩阵是正常数据,是故障数据,n1和n2分别是正常训练数据和故障训练数据的样本数,m是特征个数,这里n1=500,n2=480,m=52。对训练数据进行标准化预处理,标准化公式为其中为正常训练数据第j个特征的均值,σ1j为正常训练数据第j个特征的标准差。s402,初始化特征集为数据的整个特征的集合,即特征索引集为全集s={1,2,...,m},初始化排序后的特征索引集,即排序特征索引集。s403,在特征索引全集s中去除第p个特征即预选特征后,构成特征索引子集sp={1,2,...,p-1,p+1,...,m},令l=|sp|为特征索引子集所包含的特征个数。对于不同的特征索引子集sp,可形成新训练数据矩阵即第二正常训练数据矩阵x1p=[x11,x12,...,x1(p-1),x1(p+1),...,x1m]和第二故障训练数据矩阵x2p=[x21,x22,...,x2(p-1),x2(p+1),...,x2m]。s405,计算新训练数据矩阵的协方差矩阵从而可以得到联合协方差矩阵作为第一协方差矩阵。s406,对第一协方差矩阵rp进行特征分解后得到特征向量和特征值,特征向量为一个正交化矩阵p0,特征值则为对角化矩阵λ,满足rpp0=p0λ,从而得到投影矩阵p=p0λ-1/2。s407,利用投影矩阵p对第二正常训练数据矩阵x1p进行投影,x1p投影后的矩阵可表示为s408,计算投影后矩阵b1p的协方差矩阵s1p,作为第二协方差矩阵,对之进行特征分解得到特征值λ1k,k=1,2,...,l。s409,利用特征值λ1k对同一特征子集的两个不同数据集之间的相异性diss(x1p,x2p)用dp来表示:这里,dp越小,表示两个数据集越相似;dp越大则表明两个数据集的差异也就越大,从而表明去除的第p个特征对造成两者之间的差异影响并不大。s410,从特征集中移除dp值最大的相对应的特征p。更新特征集s和r:s←s-{p},r←r∪{p},返回到s403,直至s411,采用支持向量机分类器在训练数据上进行10折交叉验证,取分类效果最好的特征数集,即为最优特征集。检测模块:s412,实时收集工业过程的测试数据(m为特征个数),在这里,有960个测试样本,特征数m=52,并按照训练模块s401将数据标准化:s413,根据训练得到的最优特征集选取测试数据的特征形成输入数据,再用支持向量机分类,输出结果,判断测试样本是否有故障,是否属于此类故障。本发明的效果可以通过如下实验验证:通过本发明提出的基于相异性的序列后向特征选择方法,以tep的正常训练数据集和故障训练数据集作为训练数据,tep的故障测试数据集测试,发现本发明可以对每类故障有效地完成特征选择,找出关键特征,剔除无用特征,大大减少了特征个数,从而提高故障检测率。实验表明本发明提出的基于相异性的特征选择方法和支持向量机结合(即dsbs-svm)可以改善传统的支持向量机(svm)的故障诊断结果,同时对于复杂的过程数据,基于相异性的特征选择方法的表现要远远优于一些传统的特征选择方法(如fscore和relief)。不同故障的故障诊断结果如表1所示,我们发现fscore-svm和relief-svm在故障19的检测率没有svm的高,说明这两个方法没有选出关键特征,无法从复杂的工业数据中挖掘出有价值信息。而在dsbs-svm的故障诊断模型中,故障11,16,19和21的检测率都有了很大的提升。除了故障检测率以外,对比fscore、relief和dsbs三种特征选择方法得到的最优特征集的特征个数,dsbs选择的特征个数最少,如表2所示,而且很大程度上改善了svm的诊断结果,特别是故障21的诊断表现最为明显,如图5、图6所示。表1不同故障用svm、fscore-svm、relief-svm和dsbs-svm的故障检测率故障类型svmfscore-svmrelief-svmdsbs-svm故障1183.50%76.88%84.75%87.38%故障1689.50%90.63%89.75%92.75%故障1987.75%88.50%87.38%92.00%故障2112.88%13.38%42.13%100%表2不同故障用fscore、relief和dsbs得到的最优特征集的个数故障类型fscorereliefdsbs故障11431510故障16352318故障1925308故障2133351本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1