机器人姿态路径目标航迹优化的认知发育方法与流程
技术领域:
本发明属于智能机器人技术领域,涉及了一种机器人姿态路径目标航迹优化仿真方法。
技术背景:
人与动物智能行为的体现是学习与记忆,其多种技能都是在神经系统由自学习和自组织的过程中慢慢形成并渐渐发展起来的,学习和模拟人与动物的神经活动和自我调节机制,并将其赋予给智能机器人,是人工智能与控制科学的重要研究课题。1996年,j.weng最早提出机器人自主心智发育思想,他认为智能体应该在模拟人脑的基础上,在内在发育程序的控制下通过传感器和效应器与未知环境交互来发展心智能力。brooks等强调机器人与教师、环境进行交互学习逐渐发展其智能,并通过结合神经科学的研究理论提出模拟人与动物的脑皮层中的前额叶、下丘脑、海马等区域的计算模型来处理复杂环境中复杂问题,这也就涉及到了感觉运动系统。最初的认知发育是从感觉运动系统协调机制的形成和发育开始,同时感觉运动系统又是在内在动机形成和发育的过程中不断协调和完善的。神经学相关文献表明,在人与动物学习的过程中,大脑皮层、基底核以及小脑会以自身特有的方法平行工作,并且在人与动物运动有关的相互关系中,小脑和基底核分布在大脑皮质到脊髓之间运动信号传递的路线的两侧,它们会参与任一行为动作的发起及控制。
很多学者早在20世纪80年代初就已经进行了相关研究。在2000年,moren等针对基于mower双过程学习理论提出了情感与行为选择相结合的体系。2007年wang等人在人体大脑情感回路的基础上提出了一种基于人工情感的智能模型,并应用于倒立摆系统使其成功学会平衡控制技能。2010年batto等人从进化的角度,以强化学习为理论框架,并采用内在动机驱动的主动学习,极大提高了智能体的学习效率。2013年oudeyer等人从生物的自我意识下的探索出发,结合内在动机思想,提出了系统状态转移误差学习机,实现对未知氛围的主动摸索学习。2014年沈孝文等人提出分层强化学习与潜在动作模型的研究与应用,研究障碍物的潜在动作模型,结合分层强化学习,对障碍物环境下机器人路径规划问题进行了的应用。
生物学相关文献得出结论,人与动物的感觉运动系统中存在动机与内在目标相关联的机制,称为内在动机机制。该机制是以感觉运动系统为理论基础,并由生物体好奇心,取向性所引导的一种学习机制。针对传统机器学习不能连续学习问题,受以上研究的启发,将感觉运动系统与内在动机机制相结合,模拟生物体认知行为并以学习自动机为基础框架,提出一种基于小脑-基底核-大脑皮层回路的认知发育算法,利用该算法使两轮机器人通过与未知环境的交互,逐渐掌握运动平衡控制技能,并实现实时认知发育,达到机器学习的连续学习的目的。
相关的专利如申请公开号cn106403948a的发明专利公开了一种用于输电线路巡检无人机的三维航迹规划方法,该发明对电力巡线无人机航迹规划方法进行了研究,基于序列规划思想,采用bp神经网络算法规划基准航迹,提高了航迹规划效率,减少了无人机电力巡线的三维航迹规划时间。
申请公开号cn106557844a的发明专利公开了一种基于聚类指导多目标粒子群优化技术的焊接机器人路径规划方法,建立焊接机器人的d#h参数模型,通过几何避障策略得到避障路径,并针对所述避障路径进行基于笛卡尔空间的轨迹规划。
但是以上两专利都没有涉及将人与动物的神经活动和自我调节机制赋予机器人的实践探索。
技术实现要素:
:
本发明提供一种针对两轮机器人连续行为的学习,提供一种模拟人类心理认知机理与脑部神经运动的机器人控制方法,使机器人模拟人的小脑--基底核--大脑皮层回路的认知发育算法(cbcla)的思维方式进行仿生认知发育,并运用到移动机器人路径规划研究当中,提供一种机器人姿态路径目标航迹优化的认知发育方法,具体为:
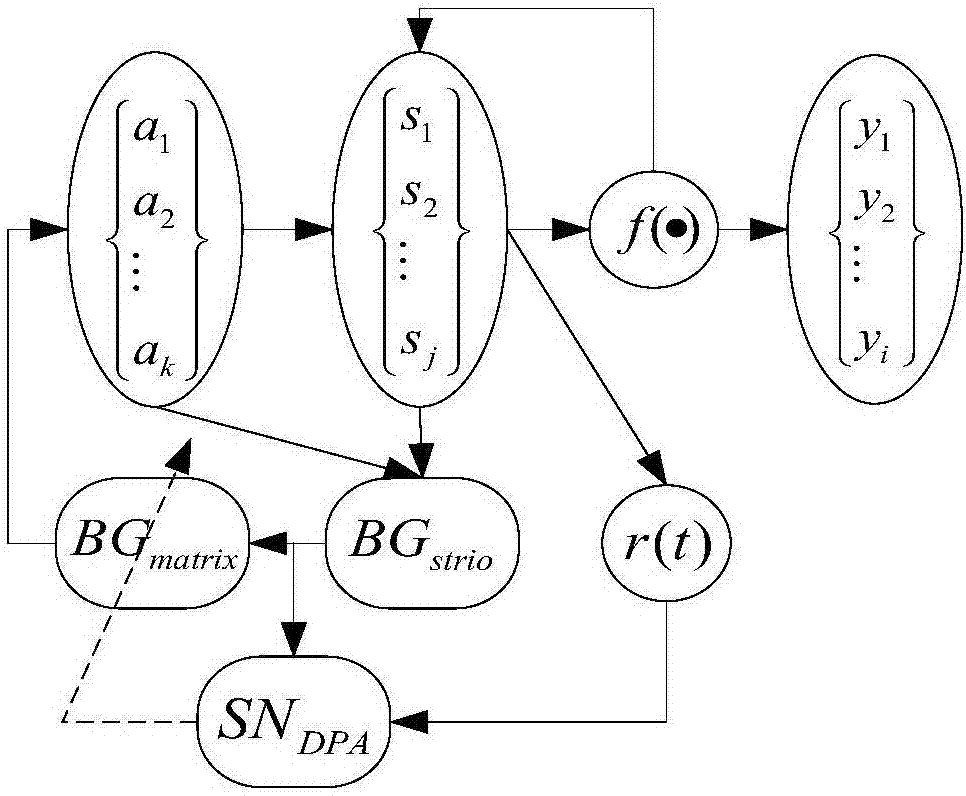
机器人姿态路径目标航迹优化的认知发育方法,本方法是将人的基于小脑--基底核--大脑皮层回路的认知发育算法(cbcla)思维与机器人结合,此机器人的认知发育过程分为八个部分,分别为有限的内部状态集合、系统的输出集合、内部操作行为集合,状态转移方程、系统在t时刻在内部状态、评价函数、纹状体基质的动作选择概率输出和多巴胺能,这八个部分的相互关联可以用一个八元数组表示:
cbcla={sc,mc,cba,f,r(t),bgstrio,bgmatrix,sndpa}
1)sc=[s1,s2,...sj]表示为有限的内部状态集合,相对应于大脑皮层中的感觉皮层,sj表示第j个状态,j为内部状态个数;
2)mc=[y1,y2,...yi]表示为系统的输出集合,相对应于大脑皮层中的运动皮层,yi表示第i个输出,i表示输出个数;
3)cba=[a1,a2,...ak]表示为内部操作行为集合,相对应于小脑区域,ak为第k个内部动作,k为内部动作个数;
4)f:s(t)×a(t)→s(t+1)为状态转移方程,即t+1时刻的状态s(t+1)由t时刻的状态s(t)和操作行为a(t)共同决定,一般有环境或者模型来决定;
5)r(t)=r(s(t),a(t))表示为系统在t时刻在内部状态为s(t)时所采取的内部操作行为a(t)后使状态转移到s(t+1)后的奖赏信号,相对于丘脑所发出的丘觉;
6)bgstrio为评价函数,纹状小体主要是预测生物体动作取向性好坏的评价机制,进一步说也是内在动机机制取向性好坏的评价机制;
7)bgmatrix纹状小体基质的动作选择概率输出,在基底神经节的学习过程中,纹状小体中的基质主要是动作选择功能;
8)sndpa多巴胺能,其作为行为评价的指导激励,作为提高由激励形成的未知最大奖励的行为表示,由此得到准确的执行动作。
由状态转移方程f:s(t)×a(t)→s(t+1)知,t+1时刻的外部状态s(t+1)∈s总是由t时刻的外部状态s(t)∈s与t时刻的外部智能体动作a(t)∈a决定,与其t时刻之前的外部状态和外部智能体动作无关。
上述的大脑皮层中的输入信号包含两部分,分别是感觉皮质信息和运动皮质信息,作为纹状小体的输入,因此:
cc={sc,mc}(1)
本发明定义评价函数bgstrio如下:
其中,γ∈[0,1]为折扣因子,由于内在动机机制存在的缘故,使得系统的评价函数bgstrio逐渐趋近于0,从而保证系统最终处于稳定状态;定义η为内在动机机制中的取向核心,主要功能是指导自主认知方向,一般定义取向核心η的取值范围在[ηmin,ηmax]之间,即取向性最好与取向性最差的函数值之间,那么在纹状小体中内在动机取向函数定义如公式(3)所示:
其中λ为取向函数的参数,定义两个相邻时刻的取向函数的差值为θ(t)=η(t)-η(t-1),来判别系统的取向性程度,如果θ(t)>0,说明t时刻比t-1时刻的取向值大,反之θ(t)<0,说明说明t时刻比t-1时刻的取向值小。
本发明采用boltzmann概率规则来实现基质的动作选择功能,实现学习自动机的概率选择机制,首先定义:
根据公式(4)中的定义,我们可以将纹状小体基质的动作选择概率输出用公式(5)表示:
其中,t为温度常数,表示动作的选择随机程度,t越大说明动作选择的程度越大,相反t越小说明动作选择的程度越小,当t逐渐趋于零时,则bgstrio(sc(t),aj)所对应的动作选择概率逐渐趋于1,系统中t的数值是随着时间逐渐减小的。
在t+1时刻由纹状小体所决定的评价函数为:
结合公式(2)和公式(6)可以得出公式(7):
bgstrio(t)=r(t+1)+γbgstrio(t+1)(7)
这表明,在t时刻时,评价函数bgstrio(t)可以用t+1时刻的评价函数bgstrio(t+1)来表示,但是由于预测初期所存在的误差的影响,使得用评价值bgstrio(t+1)来表示bgstrio(t)的值与实际值并不相等,这样由丘脑输出和纹状小体输出的奖赏信息需要在黑质致密部进行处理,并释放多巴胺能sndpa来调节评价值的表,可以用公式(8)来表示:
sndpa=r(t+1)+γbgstrio(t+1)-bgstrio(t)(8)
本发明模拟生物体感觉运动系统的神经活动,以学习自动机为框架,结合内在动机机制驱动生物体自主学习的特点,提出了一种机器人姿态路径目标航迹优化的认知发育算法,本认知发育算法运用到移动机器人路径规划研究当中,机器人在未知环境下,通过自主学习发育,逐渐掌握运动平衡控制技能,并实现目标的实时跟踪。
附图说明:
图1为本发明的算法控制结构图;
图2为认知发育自动机框架;
图3各状态响应输出曲线;
图4评价函数与误差仿真曲线;
图5抗干扰实验仿真结果;
图6cbcla算法与经典la算法的评价函数对比图;
图7cbcla算法与经典la算法的误差对比图。
具体实施方案
本发明针对两轮机器人连续行为的学习,模拟人类心理认知机理与脑部神经运动现象,基于人的小脑-基底核-大脑皮层回路的认知发育算法(cbcla)思维活动,提出了一种基于机器人的认知发育方法,并运用到移动机器人路径规划研究当中。机器人在未知环境下,通过自主学习发育,逐渐掌握运动平衡控制技能,并实现目标的实时跟踪。
依据上述思想创造一种机器人姿态路径目标航迹优化的认知发育方法,该方法将人的基于小脑--基底核--大脑皮层回路的认知发育算法(cbcla)思维与机器人结合,此机器人的认知发育过程分为八个部分,分别为有限的内部状态集合、系统的输出集合、内部操作行为集合、状态转移方程、系统在t时刻在内部状态、评价函数、纹状体基质的动作选择概率输出、多巴胺能,这八个部分的相互关联可以用一个八元数组表示:
cbcla={sc,mc,cba,f,r(t),bgstrio,bgmatrix,sndpa}
各个部分具体含义如下:
(1)sc=[s1,s2,...sj]表示为有限的内部状态集合,相对应于大脑皮层中的感觉皮层,sj表示第j个状态,j为内部状态个数。
(2)mc=[y1,y2,...yi]表示为系统的输出集合,相对应于大脑皮层中的运动皮层,yi表示第i个输出,i表示输出个数。
(3)cba=[a1,a2,...ak]表示为内部操作行为集合,相对应于小脑区域,ak为第k个内部动作,k为内部动作个数。
(4)f:s(t)×a(t)→s(t+1)为状态转移方程,即t+1时刻的状态s(t+1)由t时刻的状态s(t)和操作行为a(t)共同决定,一般有环境或者模型来决定。
(5)r(t)=r(s(t),a(t))表示为系统在t时刻在内部状态为s(t)是所采取的内部操作行为a(t)后使状态转移到s(t+1)后的奖赏信号,相对于丘脑所发出的丘觉。
大脑皮层中的输入信号包含两部分,分别是感觉皮质信息和运动皮质信息,作为纹状小体的输入,因此:
cc={sc,mc}(1)
(6)bgstrio为评价函数,纹状小体主要是预测生物体动作取向性好坏的评价机制,进一步说也是内在动机机制取向性好坏的评价机制,定义评价函数如下:
其中,γ∈[0,1]为折扣因子。由于内在动机机制存在的缘故,使得系统的评价函数bgstrio逐渐趋近于0,从而保证系统最终处于稳定状态。我们定义η为内在动机机制中的取向核心,主要功能是指导自主认知方向。一般定义取向核心η的取值范围在[ηmin,ηmax]之间,即取向性最好与取向性最差的函数值之间。那么在纹状小体中内在动机取向函数定义如公式(3)所示:
其中λ为取向函数的参数,定义两个相邻时刻的取向函数的差值为θ(t)=η(t)-η(t-1),来判别系统的取向性程度,如果θ(t)>0,说明t时刻比t-1时刻的取向值大,反之θ(t)<0,说明说明t时刻比t-1时刻的取向值小。
(7)bgmatrix纹状小体基质的动作选择概率输出,在基底神经节的学习过程中,纹状小体中的基质主要是动作选择功能。在由内在动机机制驱动的学习过程中最重要的一个特点就是依照概率大小来选择执行动作。我们采用boltzmann概率规则来实现基质的动作选择功能,从而实现学习自动机的概率选择机制。首先我们定义:
根据公式(4)中的定义,我们可以将纹状小体基质的动作选择概率输出用公式(5)表示:
其中,t为温度常数,表示动作的选择随机程度,t越大说明动作选择的程度越大,相反t越小说明动作选择的程度越小。当t逐渐趋于零时,则bgstrio(sc(t),aj)所对应的动作选择概率逐渐趋于1,系统中t的数值是随着时间逐渐减小的,表示系统在学习过程中经验知识的逐渐增多,并且从一个不稳定的系统逐渐演化为一个稳定系统。
(8)sndpa多巴胺能,其可以作为行为平价的指导激励,作为提高由激励形成的未知最大奖励的行为表示,由此得到更加准确的执行动作。在t+1时刻由纹状小体所决定的评价函数为:
结合公式(2)和公式(6)可以得出公式(7):
bgstrio(t)=r(t+1)+γbgstrio(t+1)(7)
这表明,在t时刻时,评价函数bgstrio(t)可以用t+1时刻的评价函数bgstrio(t+1)来表示,但是由于预测初期所存在的误差的影响,使得用评价值bgstrio(t+1)来表示bgstrio(t)的值与实际值并不相等,这样由丘脑输出和纹状体输出的奖赏信息需要在黑质致密部进行处理,并释放多巴胺能sndpa来调节评价值的表,可以用公式(8)来表示:
sndpa=r(t+1)+γbgstrio(t+1)-bgstrio(t)(8)
本发明算法收敛性证明:
将纹状小体输出的评价函数bgstrio(t)设为
bgstrio(t)=j(t)(9)
在markov环境下应用
证明:考虑任意一个状态动作对(s,a)的评价函数与其最优值差的绝对值为:
其中,发生转移后的状态和动作为s'和a',二次转移的状态为s”,
则有:
δjn≤γδjn-1≤γnδj0(12)
因为
本方法结合了动态规划与动物生理学知识,从而可以实现具有回报的机器在线学习。本认知发育算法运用到移动机器人路径规划研究当中,机器人在未知环境下,通过自主学习发育,逐渐掌握运动平衡控制技能,并实现目标的实时跟踪。
下面结合附图和实施方案对本发明作出进一步说明。
图1为本发明的算法控制结构图,按照图中所示顺序进行算法控制。图2为认知发育自动机框架,与图1表示的状态量相互对应。实验的前提获得能够自平衡的机器人,所以首先要对机器人的平衡进行控制。
为了验证本文所提出的基于小脑-基底核-大脑皮层回路的认知发育算法(cbcla)的有效性、鲁棒性以及优越性,以两轮机器人为实验对象,研究了在未知环境下机器人是怎样通过自主学习最后学会运动技能的。
机器人在实验过程中有四个输出量并满足相应条件,即左右两轮角速度θr和θl均小于3.489rad/s,机身自身倾角α<0.1744rad和机器人摆杆角速度β<3.489rad/s。折扣因子γ=0.9,采样时间为0.01s。机器人获得自平衡的标准是在一次试验中能保持20000步。失败的标准是尝试次数超过1000次或者每一次尝试实验的平衡步数超过20000步。在每次实验失败后,都要在一定范围内重新赋予初始状态和每一个权值随机值,再重新下一次学习。
(1)平衡控制实验:机器人在没有干扰的未知环境下,采用本文提出的cbcla算法,经过不断的学习,经过42次试探并在第43次试探中完成实验,大约需要经历220步左右,即2.2s左右就学会了平衡控制技能,表现了其较快的自主学习能力和算法的有效性,图3所示是实验中前3000步的各状态量响应曲线,图4所示是实验中前3000步的评价函数与误差仿真曲线。
(2)抗干扰实验:在系统实际的运行过程中,输入输出信号会或多或少的受到外部噪声的干扰,或检测装置的不精确,都会使状态量产生一定的误差。那么为了模拟实际环境,当机器人已经学会平衡控制后保持9800步时,将幅值为25的脉冲信号加入到各个输入状态量中,如果机器人能够经受脉冲信号的干扰并保持平衡,则认为实验成功并证明本文提出的cbcla算法具有一定的鲁棒性。图5为加入脉冲信号后各状态的输出响应,可以看出经过200步(即2s)左右后,机器人重新达到平衡位置。
(3)算法对比实验:由于本文算法引进了内在动机机制来驱动机器人的自主学习,有利于降低系统的误差,提高算法的收敛速度。为了证明cbcla算法的优越性,应用经典学习自动机(la)算法与cbcla算法对两轮机器人进行了平衡控制实验,并对其实验结果进行分析。实验中两种算法的参数设定相同。评价函数bgstrio对应系统是否能达到稳定,通过图6是la算法和cbcla算法的仿真曲线对比图,通过对评价函数的快速稳定性比较,可以看出cbcla算法在大约220步(即2.2s)就完成了平衡控制技能的学习,而经典la算法在大约600步(即6s)才完成学习,证明cbcla算法的收敛速度优于经典la算法。误差sndpa反映系统的稳定性,图7两种算法的误差对比图,由仿真结果表明cbcla算法的误差幅度小于经典la算法,更有利于系统的稳定。
- 还没有人留言评论。精彩留言会获得点赞!