基于时间序列模型系数的半导体批次过程故障诊断方法与流程
本发明属于用于控制系统的故障诊断技术领域,具体涉及一种基于时间序列模型系数的半导体批次过程故障诊断方法,用于提高半导体批次过程故障诊断的准确率。
背景技术:
批次控制(Run-to-run control或简记为R2R control),又称为批对批控制,是反馈控制的一种,与迭代学习控制和重复控制有很多类似之处。它通过对过程的历史批次数据的统计分析来改变下一批次的制程方案(Recip),解决间歇过程中因缺乏在线测量手段而造成难以进行实时过程控制的问题,从而降低批次产品的质量差异。
公开日为2005年3月9日的中国专利文献CN1592873A公开了一种具有状态和模型参数估计的半导体批次控制系统,其采用模型预测控制(MPC)原理估计R2R控制应用中组合的状态和参数。
MSPC是一种基于数据驱动的故障诊断技术,近几年来已经成功地应用于批次过程的在线监测,尤其是在半导体批次过程。很多文献在使用MSPC进行监测时,都只考虑了系统的输入输出数据。自动过程控制的引入会削弱外部干扰对系统输出的影响,不同的输入可能获得几乎相同的输出,因此闭环系统的输入输出数据提供有关系统动态特性的信息比较少。当故障处于早期阶段或者幅值较小时,一个比较好的反馈控制器总能保证系统的输出与原始的稳定状态保持一致。在这种情况下,传统的SPC只能在有限的窗口内检测出故障,导致了更高的漏报率。
为了解决这一问题,Zheng等人提出了基于时间序列模型系数的故障监测方法(Zheng Y,Wang Y,Wong D.S.H,et al.A time series model coefficients monitoring approach for controlled processes[J].Chemical Engineering Research and Design, 2015,1 0 0:228–236.)。时间序列模型的系数是一些过程变量的函数,它们包含着过程变量的信息。当系统遇到外界干扰,过程的输入输出关系发生改变时,时间序列模型的系数也会发生改变。
然而,上述研究的着重点集中在半导体批次过程的故障监测方面,很少考虑半导体批次过程的故障诊断。
支持向量机(SVM)是一种新型的机器学习算法,它基本上不依赖于系统的数学模型,比较适合于具有不确定性和高度非线性的系统,并具有较强的适应和学习能力。
技术实现要素:
为了改进现有的半导体批次故障诊断准确率低的问题,发明人将SVM引入到时间序列模型系数的故障诊断中,提出基于时间序列模型系数的故障诊断模型,并将其应用到半导体批次过程故障诊断中,用以提高半导体批次过程故障诊断中的准确率。
本发明要解决的技术问题是提供一种基于时间序列模型系数的半导体批次过程故障诊断方法,用以提高半导体批次过程故障诊断中的准确率。
为解决上述技术问题,本发明采用如下技术方案:
设计一种基于时间序列模型的半导体批次过程故障诊断方法,包括以下步骤,
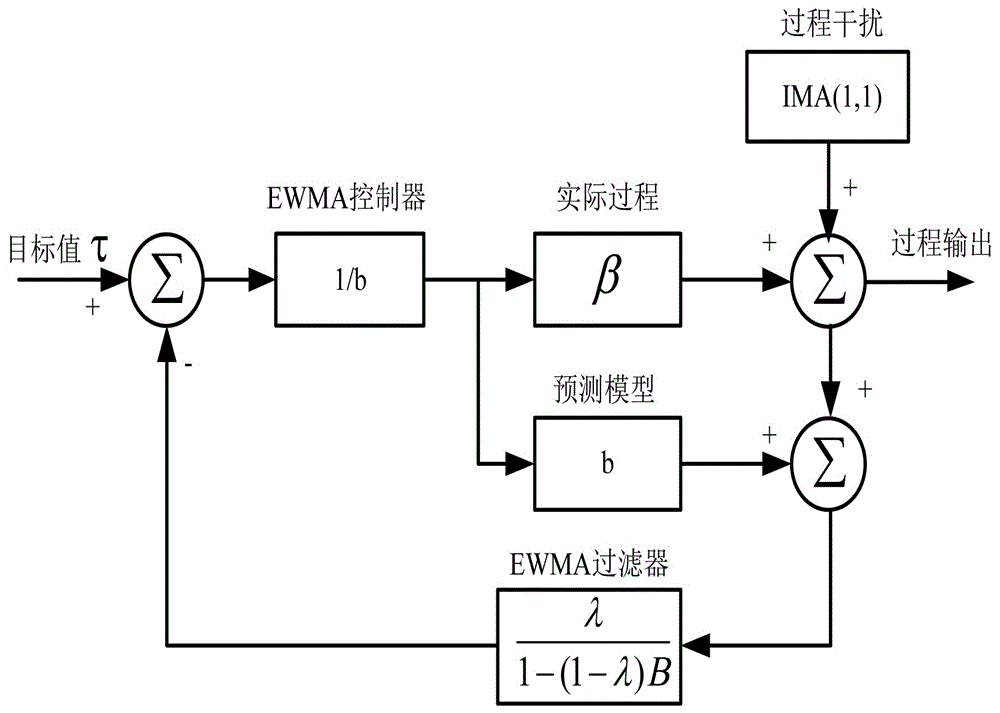
步骤一,基于指数加权移动平均控制器,建立半导体批次过程的时间序列模型
式(1)、(2)、(3)中,y(t)为半导体批次过程的输出数据,t表示批次序号, t=1,2,...,N,β为批次过程中的增益,b为β的起始估计值,λ为折扣因子,0≤λ≤1,δ是漂移项,ρ是批次过程干扰模型的系数,是ε(t-1)的估计值,属于白噪声序列,σε是白噪声序列的方差;
步骤二,估计所述步骤一中式(3)的白噪声序列
(1)获取半导体批次过程的输出数据y(t),建立如下高阶自回归AR(n)模型
y(t)=φ1y(t-1)+φ2y(t-2)+...+φny(t-n)+ε(t) (4)
其中,φn是高阶AR(n)模型的系数,n是模型的阶次,n=10~20;
(2)利用递推最小二乘法辨识高阶AR(n)模型的系数θ(t)=[φ1(t),φ2(t),...,φn(t)]:
其中,h(t-1)=[y(t-1),y(t-2),...,y(t-n)]T,K(t)是增益向量,P(t)是维度为p×p的矩阵,p是系数向量θ(t)中变量的个数,μ是遗忘因子,μ∈[0,1],I为维度p×p单位矩阵,p=n,c≥105;
(3)计算白噪声的估计值
(4)比较估计值和经验阀值υ的大小,当令t=t+1,重复循环本步骤中的(2)-(4)直至时结束循环,
步骤三,估计时间序列模型中式(1)和式(2)的系数θ0(t):
根据步骤二估计的白噪声构造:
利用递推最小二乘法辨识估计时间序列模型的系数θ0(t):
其中K0(t)是增益向量,P0(t)是维度为p0×p0的矩阵,p0是系数向量θ0(t)中变量的个数,μ0是遗忘因子,μ0∈[0,1],I0为维度p0×p0单位矩阵,c0≥105;
步骤四,定义标签向量f(t)以使f(t)的值与故障类别唯一对应,所述故障类别在半导体批次过程中表现为不同阶跃故障;
在运行状态下采集与所述故障对应的半导体批次过程的故障输出数据y(t),重复所述步骤二、步骤三以获取与该故障对应的模型系数θ0(t)的值,构成训练样本X,X包含两个类型的数据:
对所述训练样本X进行数据预处理,
其中Xi,j是样本第j维数据中的任意值,maxj和minj是第j维数据的最大值和最小值, [a′,b′]是缩放目标区间,N和m分别是X中样本和变量的个数;
基于预处理后的训练样本X数据进行SVM训练,确定下述分类器的参数a1(t)、b1、γ的值,并将参数a1(t)、b1、γ的值代入分类器以更新分类器,
其中a1(t)与b1均为常实数且a1(t)>0,Ψ(*,*)为核函数,γ是核函数的参数,sign是符号函数;
在当前运行状态下接收半导体批次过程的输出数据y(t),重复所述步骤二、步骤三对该输出数据y(t)进行处理以获取该输出数据的模型系数θ0(t)的值,将该模型系数θ0(t)的值输入到已建好的分类器(15)中,比较预测结果Δ(θ0(t))和标签向量f(t)的值,当Δ(θ0(t))与标签向量f(t)中的某一值相同时,则该待测样本为该值对应的故障类别。
本发明的有益效果是:采用基于时间序列模型系数的故障诊断与传统的基于过程数据的故障诊断的相比,将时间序列模型的系数引入到半导体批次过程的故障诊断中,此方法有效地解决了闭环系统过程数据动态信息量少的问题,采用先估计白噪声再辨识模型系数θ0(t)的两步模型辨识算法,有效的修正了直接估计模型系数的辨识率不高问题,提高了模型系数的辨识精度,然后将SVM算法引入到模型在半导体批次过程中故障的在线估计应用中,提高了在线诊断半导体批次过程故障的准确率。
附图说明
图1为一种基于时间序列模型系数的半导体批次过程故障诊断方法的原理图。
图2为一种基于时间序列模型系数的半导体批次过程故障诊断方法的流程图。
图3为一种基于时间序列模型系数的半导体批次过程故障诊断方法的输入输出数据图。
具体实施方式
下面结合附图和实施例来说明本发明的具体实施方式,但以下实施例只是用来详细说明本发明,并不以任何方式限制本发明的范围。
实施例1:
一种基于时间序列模型系数的半导体批次过程故障诊断方法,参见图1-2,包括以下步骤:
步骤一,基于指数加权移动平均(EWMA)控制器,建立半导体批次过程的时间序列模型:
其中,y(t)为半导体批次过程的输出数据,t表示批次序号,t=1,2,...,200,β=2.5为批次过程中的增益,b=3为β的起始估计值,λ=0.6是折扣因子,δ=0.05是漂移项,ε(t)~N(0,0.01)属于白噪声序列,ρ=0.5是批次过程干扰模型的系数。
令θ0=[φ0,δ,ρ],则公式(17)为:
y(t)=θ0*h0(t-1) (18)
其中是ε(t-1)的估计值。
步骤二:估计时间序列模型(18)的白噪声序列
(1)获取半导体批次过程的输出数据y(t),建立如下高阶自回归AR(n)模型:
y(t)=φ1y(t-1)+φ2y(t-2)+...+φny(t-n)+ε(t) (19)
其中φn是高阶AR(n)模型的系数,n是模型的阶次,取n=10。
(2)利用递推最小二乘法辨识高阶AR(n)模型的系数θ(t)=[φ1(t),φ2(t),...,φn(t)]:
其中h(t-1)=[y(t-1),y(t-2),...,y(t-10)]T,K(t)是增益向量,P(t)是维度为10×10 的矩阵,μ=0.99是遗忘因子,I为维度10×10单位矩阵,c为很大的实数,取c=105。
(3)计算白噪声的估计值
(4)比较估计值和经验阀值υ=0.01,当令t=t+1,重复循环本步骤中的(2)-(4)直至时结束循环,经验阀值υ由经验丰富的工程师设定。
步骤三,估计时间序列模型中式(18)的系数θ0(t):
根据步骤二估计的白噪声构造:
利用递推最小二乘法辨识估计时间序列模型的系数θ0(t):
其中K0(t)是增益向量,P0(t)是维度为3×3的矩阵,μ0=0.2是遗忘因子,I0为维度3×3单位矩阵,c0为很大的实数,取c0=105。
步骤四,定义标签向量f(t)为{1,-1},其中,f(t)=1对应于故障A,f(t)=-1对应于故障B,故障A、故障B在半导体批次过程中表现为不同阶跃故障;参见图1-2,
在运行状态下采集批次过程中两个不同阶跃故障β(β→β+0.5),ρ=0.5→ρ=1对应的半导体批次过程的故障输出数据y(t),重复步骤二、步骤三以获取与两个故障对应的模型系数θ0(t)的值,构成训练样本X,X包含两个类型的数据:
对所述训练样本X进行数据预处理:
其中Xi,j是样本第j维数据中的任意值,maxj和minj是第j维数据的最大值和最小值,[a′,b′]是缩放目标区间,一般取[-1,1]和[0,1],N=200和m=3分别是X中样本和变量的个数。
基于预处理后的训练样本X数据进行SVM训练,确定下述分类器的参数a1(t)、b1、γ的值,并将参数a1(t)、b1、γ的值代入分类器以更新分类器:
其中a1(t)与b1均为常实数且a1(t)>0,Ψ(*,*)为核函数,γ是核函数的参数,sign是符号函数。式(30)分类器的建立可以通过Libsvm(http://www.csie.ntu.edu.tw/~cjlin/)中的 easy.py函数来实现。
在当前运行状态下接收半导体批次过程的输出数据y(t),重复实施例1的步骤二、步骤三对该输出数据进行处理以获取该输出数据的模型系数θ0(t)的值,将该模型系数θ0(t)的值输入到已建好的分类器(30)中,就会被投影到数据空间里,将预测结果Δ(θ0(t))和标签向量 f(t)中的值一一对比,当Δ(θ0(t))=1时,即待测样本的故障类型为故障A,当Δ(θ0(t))=-1 时,即待测样本的故障类型为故障B。
经模拟仿真试验,发明人获取如下数据,见表1。
表1不同数据对象下故障诊断的准确率
现有技术中,通常采用过程输出数据y(t)或者过程输入x(t)与输出数据y(t)的结合建立分类器对半导体批次过程进行故障诊断,图3中,x(t)为过程输入数据,y(t)为过程输出数据;表1中,CR(y)对应于采用过程输出数据y(t)建立的分类器进行故障诊断的准确率, CR(x,y)对应于采用过程输入x(t)与输出数据y(t)的结合建立的分类器进行故障诊断的准确率,CR(θ)表示的是采用本发明的模型系数θ(t)建立的分类器进行故障诊断的准确率。从表1 可以看出,当过程参数β发生故障时,采用模型系数建立分类器时,准确率达到89.17%,而采用现有技术中的模型,其根据输出数据,或者输入输出数据的准确率分别为45.42%和 52.5%,远低于前者。同样,当过程参数ρ发生故障时,采用模型系数建立分类器也获得了较高的正确率。因此,采用模型系数进行故障诊断具有较高的正确率。
上面结合附图和实施例对本发明作了详细的说明,但是,所属技术领域的技术人员能够理解,在不脱离本发明宗旨的前提下,还可以对上述实施例中的各个具体参数进行变更,形成多个具体的实施例,均为本发明的常见变化范围,在此不再一一详述。
- 还没有人留言评论。精彩留言会获得点赞!