一种基于记忆关联强化学习的嵌入式实时水下机器人智能决策方法与流程
本发明涉及一种基于记忆关联强化学习的嵌入式实时水下机器人智能决策方法,具体说是一种基于rbf神经网络和q学习结合的水下机器人路径规划的智能决策方法,属于算法领域。
背景技术
水下机器人具有无碰撞规划的能力是顺利执行任务的一个先决条件,路径规划任务就是搜索一条从起始位置到目标位置的无碰撞路径,同时优化性能指标如距离,时间或能耗,其中距离是最常采用的标准。根据机器人所具有的先验信息的多少,可将路径规划方法划分为全局和局部两种算法,其中局部的路径规划可以通过传感器在线探测机器人的工作环境信息,根据每一时刻的环境信息,来进行此时刻auv的行为决策。全局路径规划是根据已知的全部环境信息来进行最优路径的搜索。全局路径规划方法有可视图法,自由空间法,栅格法等。局部路径规划方法常用的有人工势场法,遗传算法,神经网络法,模糊逻辑方法等。
目前,模糊逻辑、人工势场法、遗传算法、随机树、神经网络等都是较为成功有效的机器人路径规划方法,但这些方法通常需要假设完整的环境配置信息,然而,在大量的实际应用中需要智能体具有适应不确定性环境的能力。强化学习(reinforcementlearning,rl)方法通过智能体与未知环境交互,并尝试动作选择使累积回报最大,该方法通常运用马尔可夫决策过程(mdp)进行环境建模,通常mdp模型主要针对理想情况下的单智能体系统。另外智能体环境状态的不确定性也可由部分可观测马尔可夫决策过程进行描述。强化学习算法通过智能体与环境的交互进行学习并优化控制参数,在先验信息较少的复杂优化决策问题中具有广阔的应用前景。
技术实现要素:
本发明提供了一种基于记忆关联强化学习的嵌入式实时水下机器人智能决策方法,此模型经过大量的训练后,最终可建立环境状态与行为动作的最优映射关系,训练好的模型可用于水下机器人在未知环境下的智能决策。
本发明提供的方法通过以下步骤实现:
1.auv在起点由声纳感知环境状态s;
2.感知当前环境状态,根据策略(开始为随机选择)选择一个auv转角行为(a);
3.执行该转角动作(a),得到奖励(r),状态转移到s_;
4.将获得的(s,a,r,s_)样本存储到样本池中,并判断样本池中的样本个数是否达到规定数目100:达到,样本中随机抽取30个样本作为神经元中心ci,初始化神经网络,转到步骤5,以后将不再执行次步骤;未达到,转到步骤2;
5.在样本池中随机抽取60个样本,将s作为网络输入,得到以a为动作的q(st,at),得到所有动作的q(st+1,at+1)值;
6.根据公式计算出q值对应的target_q值:使用q和target_q训练网络,表达式如下:
7.判断s_是否终止点:是终止点,回到步骤1;非终止点,则当前状态更新为s_,返回到步骤2。
8.训练结束,获得训练好的决策神经网络。
本发明提供的方法的优势在于:在本发明提供的方法的作用下,水下机器人可以实时的避开周围障碍物,并规划出从起点到终点的一条最短路径。
附图说明
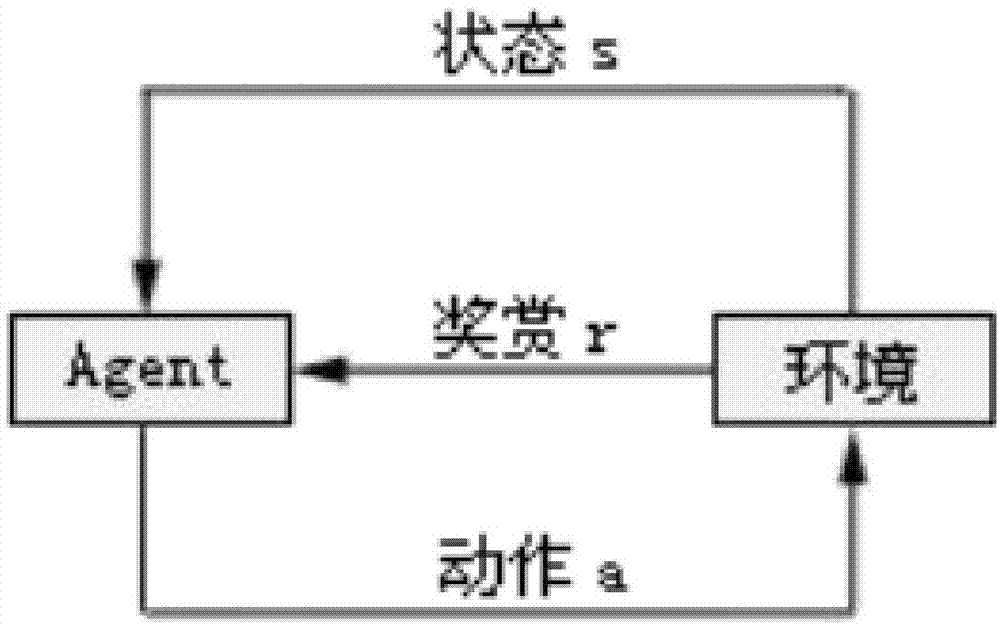
图1是强化学习的基本原理图;
图2是本发明提出的基于神经网络和q学习结合的水下机器人智能决策方法示意图;
图3是本发明中auv在时间和空间运动示意图;
图4是神经网络结构示意图。
具体实施方式
下面结合附图对本发明做进一步说明:
图1为强化学习的基本原理图,强化学习算法是一种可以与环境进行交互的在线学习算法,分为训练阶段和执行阶段,在训练阶段,agent处于某一环境状态中,在此环境状态下执行某个动作,状态发生转移,同时获得即时的得分,此得分表示对于执行此动作好坏的一种评价。并将此得分以q值的方式存储起来,重复以上状态转移的过程,agent可在与环境的交互中学得有利于自身即得分大的行为,从而避免不利行为的发生。
图2为本发明结合神经网络和强化学习算法来实现水下机器人的智能决策算法,具体设计如下:
1.基本问题描述
如图3所示,路径规划的环境设置为二维平面,建立环境地图的全局坐标系o-xy。当auv获取需要的周围环境信息后,这些信息包括目标点的位置,auv的位置速度大小和艏向角,以及障碍物位置信息。在这里,u为auv的速度大小,ct为艏向角,(xt,yt)为t时刻的位置坐标,dt为时间间隔,auv的决策输出包括速度和艏向角。假设(fx,fy)为下一时刻auv的位置坐标,可以表示为下式:
fx=xt+u×cos(ct)(1)
fy=yt+u×sin(ct)(2)
2.基于强化学习的auv智能决策方法
强化学习算法是一种可以与环境进行交互的在线学习算法,其基于马尔科夫过程(mdp)来进行决策,马尔科夫五元组由(s,a,t,r,v)来表示,s表示状态空间的集合,a表示动作空间的集合,t表示状态转移函数,r表示s状态下采取动作a的回报函数,v为决策目标函数。强化学习基于此马尔科夫四元组期望得到最优的策略π。π表示,在任意的状态s下,agent采取某个动作a,可以使得期望总回报值最大,也就是决策目标v最大。
(1)马尔科夫五元组的定义
对于水下机器人智能决策问题来说,状态s代表任意时刻水下机器人感受到周围环境信息,此信息包括周围障碍物的方向和距离以及此刻艏向角和目标点的夹角信息。具体表现为声纳在7个方向上探测的障碍物距离信息加上此刻auv艏向角和目标位置的夹角tr,7个方向分别为:以艏向方向为基础的0°,30°,60°,90°,-30°,-60°,-90°。同时将感知到的距离信息进行量化处理,声纳最远可探测距离为5,障碍物距离auv的距离为d,di为声纳第i个方向的量化结果,量化规则如下:
tr为艏向角和目标点夹角,量化规则为:
动作a表示水下机器人不同的转角和速度信息。为简化问题,动作设为auv定速下的转角运动,转向角分别为0°,10°,20°,30°,-10°,-20°,-30°。行为选择策略定义如下:随机选择概率ε=0.1,每次选择动作前产生随机数rand,则
回报函数r表示水下机器人在某一状态s1采取动作a1后,进而状态转移到s2,auv所获得的即时回报值r。本专利采用以下简单的方法定义强化信号,在每一步均能对权值进行修正,且计算简单。设某时刻水下机器人到障碍物的最小距离为mind,水下机器人t时刻到目标的距离为d1,前一时刻到目标的距离为d0,ds为设定的安全域值,则评价规则r如下确定:
目标函数v指的是初始状态s0下执行相应策略π得到的折扣累计回报,rt为t时刻即使评价值(策略π表示在任意状态s下,得到的某一动作a),公式如下:
其中γ为折扣值,一般取为0.9。
本发明选用强化学习中的q_learning算法,这是一种与模型无关的强化学习算法,每次通过在环境中采样的方式进行学习,采用状态动作对q(s,a)作为估计函数,q(s,a)表示在任意状态s下,采取任意动作a,并且状态持续转移下去,总的期望得分。q学习迭代时,智能体需要在迭代时考虑每一个状态动作对的值。q算法的更新方式如下:
其中maxq(st+1,a)为在st+1状态下可获得的最大q值,rt+1为即时得分。α为学习率。
(2)利用强化学习实现auv决策的作用方式
水下机器人与环境交互学习的过程为:在初始环境状态下s0下,采取动作a0,状态转移到s1,同时获得即时回报r0,在s1状态下,采取某一动作a1,状态转移到s2,获得即时回报r1,将产生的样本(st,a,r,st+1)先存储到记忆池中,记忆池可以设计为一个矩阵,维持记忆池容量为某个值n,若样本数量多于记忆池容量n,则将最先进入记忆池中的样本剔除,加入新产生的样本。此过程持续进行下去,直到达到目标状态为止,转而水下机器人再次回到起始点,重复以上过程继续学习。将每一步产生的即时得分r进行折扣累加和,即时回报的折扣累计和作为q(s,a)的期望回报值,本专利由上面递推公式得到折扣累计和作为q(s,a)。通过强化学习,最终可以得到一个关于所有(状态-动作)对的q值得分表,也就是期望回报值。强化学习算法的学习过程就是更新此q值表的过程。学习结束后,任意状态下最大q值所对应的动作,即为最优动作。
3.神经网络拟合q值表
对于水下机器人智能决策问题来说,由于状态空间较大,会造成状态组合爆炸的问题,基于查表法的更新方式不再满足任务要求,本专利引入rbf神经网络代替q值表,做值函数的近似。rbf网络能够逼近任意的非线性函数,可以处理系统内的难以解析的规律性,具有良好的泛化能力,并有很快的学习收敛速度,具体做法如下:
根据图4建立rbf神经网络,rbf网络使用径向基函数作为隐层神经元的的激活函数,输出层则是对隐层神经元输出的线性组合,本专利的径向基函数采用常用的高斯径向基函数
4.算法流程如下:
1.auv在起点由声纳感知环境状态s;
2.感知当前环境状态,根据策略(开始为随机选择)选择一个auv转角行为(a);
3.执行该转角动作(a),得到奖励(r),状态转移到s_;
4.将获得的(s,a,r,s_)样本存储到样本池中,并判断样本池中的样本个数是否达到规定数目100:达到,样本中随机抽取30个样本作为神经元中心ci,初始化神经网络,转到步骤5,以后将不再执行次步骤;未达到,转到步骤2;
5.在样本池中随机抽取60个样本,将s作为网络输入,得到以a为动作的q(st,at),得到所有动作的q(st+1,at+1)值;
6.根据公式计算出q值对应的target_q值:使用q和target_q训练网络,表达式如下:
7.判断s_是否终止点:是终止点,回到步骤1;非终止点,则当前状态更新为s_,返回到步骤2。
8.训练结束,获得训练好的决策神经网络。
通过在环境中的大量训练,auv已获得了自主避障且趋近目标点的智能决策行为,当auv在新的位置环境中执行任务时,通过此强化学习训练出的决策网络,仍可以顺利完成任务。
- 还没有人留言评论。精彩留言会获得点赞!