一种基于深度强化学习的车辆低速跟驰决策方法与流程
本发明涉及汽车自动驾驶领域,特别是涉及一种基于深度强化学习的车辆低速跟驰决策方法。
背景技术:
随着城市和交通的发展,很多城市早晚高峰主要路段经常出现交通拥堵现象,在车辆拥堵路段时人们的驾驶行为主要是走走停停的状态,长时间在拥堵路段驾驶会造成驾驶员心情烦躁和驾驶疲劳,从而出现疏忽或过激驾驶行为,导致擦碰、追尾等交通事故,进一步加重城市道路交通拥堵,给人们驾车出行带来很大不便。
现有的基于高级辅助驾驶技术的车辆跟驰技术主要是根据前后车距离和基于车辆动力学模型构建车辆跟驰决策模型,提醒驾驶员实施加速或减速驾驶行为。这种决策模型只能定性地提醒驾驶员是加速还是减速驾驶行为,对加速和减速的程度还是需要驾驶员自身判断,同时这种方式还不能够将驾驶员从高频度重复的驾驶操作中解放出来。自动驾驶技术能实现车辆的无人驾驶,解放驾驶员的劳动强度,但目前基于自动驾驶的车辆跟驰决策还不能拟人化地重现人类驾驶员的跟驰过程。因此,研究基于自动驾驶的拟人化的车辆低速跟驰决策方法能真正将驾驶员在拥堵路况下的操作解放出来,并提高驾驶舒适性和交通安全性。
车辆跟驰模型的发展已有60多年,并出现了很多知名的模型,如gm模型,安全距离模型,线性模型,wiedemann模型,模糊推理模型,元胞自动机模型等。
gm模型是典型的“刺激-反应”模型。该模型的刺激来源由随时间变化的
安全距离模型也称为防撞模型,根据前导车和后随车的实时速度来计算安全跟驰距离,后车驾驶员的行为是保持安全跟驰距离。该模型在交通仿真软件中有广泛的应用,如英国的sistm,美国的varsim。但实际驾驶中,驾驶员很难按照安全距离行驶。
线性模型是一种考虑驾驶员行为决策过程的模型,包括自适应加速度随前车行驶状态的变化,并考虑驾驶员反应时间对决策的影响,通过期望时距公式来实现。该模型随着速度和车辆的不同而变化,很难应用到实际中。
wiedemann模型是一种心理-生理模型。基于不同驾驶员可能对同一个刺激产生不同的反应,该模型定义了四种驾驶状态下的人的感知和反应:自由驾驶、接近驾驶、跟随模式和制动模式。这种模型受个体因素影响很大,很难校验。
模糊推理模型的输入量是前后车的相对车距和相对车速,输出为后车的加减速度,推理主要由模糊推理构成,该模型减小了前后车距达到安全车距时的振荡及相对速度的振荡。
元胞自动机模型是把交通道路描述为大小相同的元胞网格,使用一些规则来控制车辆在元胞之间的移动。元胞的运动在空间和时间上是离散的,这种方法主要用于交通仿真中,与实际环境中的驾驶有较大差距。
专利[cn107145936]一种基于强化学习的车辆跟驰模型建立方法,主要是通过创建q值网络,根据车辆执行动作计算长期回报,更新q值网络权重,不断迭代到最大回合数。通过不断对环境进行探索和对已经学到的经验进行利用,最终得到一个无须驾驶数据驱动的无人汽车跟驰模型。
技术实现要素:
为解决以上问题,本发明提供一种基于深度强化学习的车辆低速跟驰决策方法,该方法不仅提高了驾驶的舒适性,而且保证了交通的安全性,更提高了拥堵车道的畅通率,一种基于深度强化学习的车辆低速跟驰决策方法包括步骤如下,其特征在于:
(1)通过车联网实时接收前方车辆和后方车辆的位置、速度、加速度信息,作为环境状态,对无人车的当前状态和行为进行表达;
(2)构建基于actor-critic框架的深度强化学习结构,该结构以环境状态、无人车的当前状态作为输入,无人车的加速度作为输出;
(3)对深度强化学习结构中的actor网络和critic网络的参数进行训练,并对critic网络参数θv和actor网络参数θμ进行更新,多次训练完成后,无人车能够与前方车辆以及后方车辆保持一定的安全距离,在城市拥堵工况下实现车辆低速自动跟踪前车行驶。
进一步的,所述步骤一中通过车联网实时接收前方车辆和后方车辆的位置、速度、加速度信息,作为环境状态,对无人车的当前状态和行为进行表达,包括:
(1.1)通过车联网实时接收的前方三辆车的位置、速度、加速度信息表示为xf1、vf1、af1、xf2、vf2、af2、xf3、vf3、af3,其中,f1为无人车前方距离最近的一辆车,f2、f3依次类推;后方车辆的位置、速度、加速度信息表示为xr、vr、ar;
(1.2)将环境状态表达为e(xf1,vf1,af1,xf2,vf2,af2,xf3,vf3,af3,xr,vr,ar);
(1.3)将无人车的当前状态表达为c(x,v),其中,x为无人车当前状态下的位置,v为无人车当前状态下的速度;将无人车的行为表达为a(a),a为无人车行驶的加速度,为更加真实地模拟低速跟驰下的无人车行为,a需满足-3≤θa≤3,且加速度之间取值连续,单位为m/s2。
进一步的,所述步骤二中构建基于actor-critic框架的深度强化学习结构,该结构以环境状态、无人车的当前状态作为输入,无人车的加速度作为输出,包括:
(2.1)分别为actor和critic构建结构相同的包括m层的深度卷积神经网络,该网络由一维卷积层、全连接层和输出层组成;
(2.2)环境状态和无人车的当前状态首先通过一维卷积层获得一个中间特征向量,然后再通过若干次全连接层的变换,最后输出无人车的行为。
进一步的,所述步骤三中对深度强化学习结构中的actor网络和critic网络的参数进行训练,包括步骤:
(3.1)actor根据当前环境状态s选择合适动作a,在通过计算回报函数获得奖励r后,状态从s转移到s′,将s,a,r,s′组合为一个元组τ=(s,a,r,s′),并将其存放在经验回放池d中,其中,奖励r由无人车与前方三辆车的间距xf1-x、xf2-x、xf3-x、无人车与后方车辆的间距x-xr以及无人车的加速度a共同决定;
(3.2)无人车采用步骤(3.1)的方式低速跟驰,直至达到指定步数t;
(3.3)更新critic网络参数θv;
(3.4)更新actor网络参数θμ;
(3.5)重复步骤(3.1)至步骤(3.4),直到迭代达到最大步数或损失值小于给定阈值;
进一步的,所述步骤三中更新critic网络参数θv,包括步骤:
(4.1)从经验回放池d中随机采样n个元组τi=(si,ai,ri,s′i);
(4.2)对每个τi,计算yi=ri+γv(s′i|θv);
(4.3)更新θv,即
进一步的,所述步骤三中更新actor网络参数θμ,包括步骤:
(5.1)从经验回放池d中随机采样n个元组τj=(sj,aj,rj,s′j);
(5.2)对每个τj,计算δj=rj+γv(s′j|θv)-v(si|θv);
(5.3)更新θμ,即
本发明的优点主要体现在:
1、本发明的一种基于深度强化学习的车辆低速跟驰决策方法不仅不受应用场景和环境因素的限制,而且不需要预先设定参数和提供驾驶数据,因此,该方法具有较强的通用性和灵活性。
2、本发明的一种基于深度强化学习的车辆低速跟驰决策方法解决了传统的强化学习状态和动作空间必须离散的问题,不仅提高了跟驰行为的逼真性,而且提高了驾驶舒适性和交通安全性。
附图说明
图1为本发明的一种基于深度强化学习的车辆低速跟驰决策方法的框架图;
图2为本发明实施例中基于actor-critic框架的深度强化学习结构;
图3为本发明对深度强化学习结构中的actor网络和critic网络的参数进行训练的流程图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述:
本发明提供一种基于深度强化学习的车辆低速跟驰决策方法,基于深度强化学习的车辆低速跟驰决策方法不仅提高了驾驶的舒适性,而且保证了交通的安全性,更提高了拥堵车道的畅通率
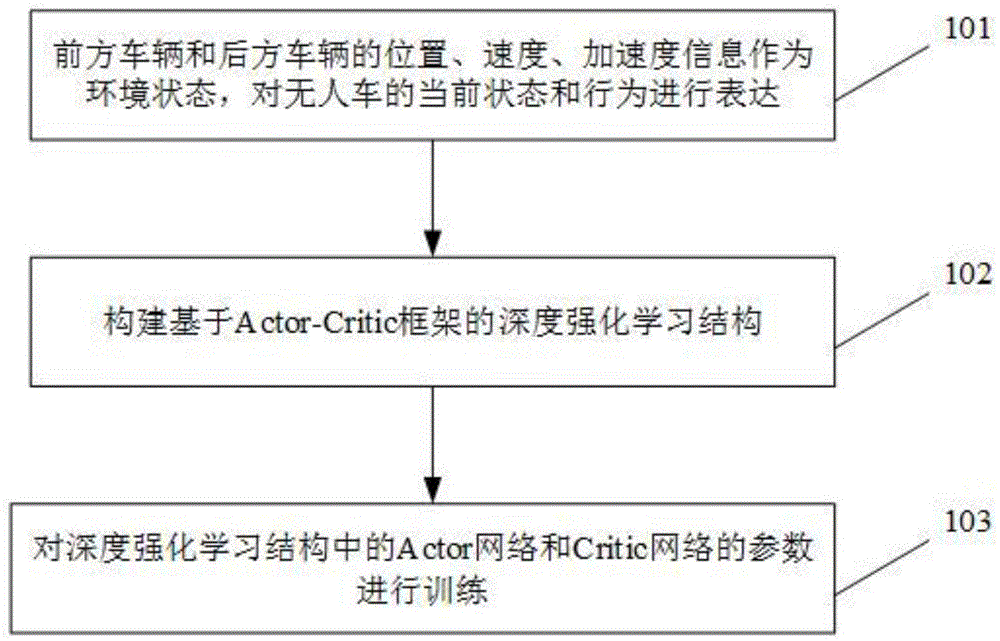
在本实施例中,如图1所示的框架图给出了本实施例的具体过程:
步骤101、通过车联网实时接收前方车辆和后方车辆的位置、速度、加速度信息,作为环境状态,对无人车的当前状态和行为进行表达,具体包括:
(1)通过车联网实时接收的前方三辆车的位置、速度、加速度信息表示为xf1、vf1、af1、xf2、vf2、af2、xf3、vf3、af3,其中,f1为无人车前方距离最近的一辆车,f2、f3依次类推;后方车辆的位置、速度、加速度信息表示为xr、vr、ar;
(2)将环境状态表达为e(xf1,vf1,af1,xf2,vf2,af2,xf3,vf3,af3,xr,vr,ar);
(3)将无人车的当前状态表达为c(x,v),其中,x为无人车当前状态下的位置,v为无人车当前状态下的速度;将无人车的行为表达为a(a),a为无人车行驶的加速度,为更加真实地模拟低速跟驰下的无人车行为,a需满足-3≤θa≤3,且加速度之间取值连续,单位为m/s2。
步骤102、如图2所示,构建基于actor-critic框架的深度强化学习结构,该结构以环境状态、无人车的当前状态作为输入,无人车的加速度作为输出,具体包括:
(1)分别为actor和critic构建结构相同的包括4层的深度卷积神经网络,该网络由1个卷积层、2个全连接层和输出层组成,前3层的激活函数均为relu函数,其表达式为f(x)=max(0,x);
(2)环境状态和无人车的当前状态首先通过卷积核为5×1的卷积层获得一个中间特征向量,然后再通过两个节点数分别16和8的全连接层的变换,输出无人车的行为。
步骤103、对深度强化学习结构中的actor网络和critic网络的参数进行训练,如图3所示,具体步骤包括:
(1)actor根据当前环境状态s选择合适动作a,在通过计算回报函数获得奖励r后,状态从s转移到s′,将s,a,r,s′组合为一个元组τ=(s,a,r,s′),并将其存放在经验回放池d中,其中,奖励r由无人车与前方车辆的间距xf1-x、xf2-x、xf3-x、无人车与后方车辆的间距x-xr以及无人车的加速度a共同决定,
其中,由于较近的车辆对无人车的行驶影响较大,所以需满足w1>w2>w3,同时满足
(2)无人车采用步骤(3.1)的方式低速跟驰,直至达到指定步数t;
(3)更新critic网络参数θv;
(4)更新actor网络参数θμ;
(5)重复步骤(3)至步骤(4),直到迭代达到最大步数或损失值小于给定阈值。
具体地,步骤(3)更新critic网络参数θv,包括步骤:
(1)从经验回放池d中随机采样n个元组τi=(si,ai,ri,s′i);
(2)对每个τi,计算yi=ri+γv(s′i|θv);
(3)更新θv,即
具体地,步骤(4)更新actor网络参数θμ,包括步骤:
(5.1)从经验回放池d中随机采样n个元组τj=(sj,aj,rj,s′j);
(5.2)对每个τj,计算δj=rj+γv(s′j|θv)-v(si|θv);
(5.3)更新θμ,即
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作任何其他形式的限制,
而依据本发明的技术实质所作的任何修改或等同变化,仍属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!