一种基于门控制机制的连续学习方法与流程
本发明涉及一种基于门控制机制的连续学习方法,属于人工智能领域。
背景技术:
近年来,深度学习技术在很多领域取得了瞩目的成就。然而,当前的深度学习模型主要面向封闭环境,针对特定任务来设计模型,尽管多任务模型能够执行多个任务,但是其假设任务具有很强的相关性,而且要求在收集有关任务的所有数据的条件下训练模型,加入新的数据需要将之前的数据进行保存并与新数据一起训练,会导致计算量的骤增和占用大量存储空间。面对真实开放环境,往往需要执行多个任务,需要智能体拥有像人一样能够逐步学习多个任务的能力,即连续学习。
连续学习主要涉及到两个问题:如何避免灾难性遗忘与如何将所学任务的知识迁移到新的学习任务中。灾难性遗忘主要是由于前面任务的参数空间在后续任务的学习中被破坏导致,分布式连续学习模型没有考虑到当前任务与前面任务的关系,简单地依靠转移矩阵将前面任务特征流引入到当前任务网络中。如果任务特征空间之间没有交叉,暴力地迁移无益于当前任务学习甚至对学习是有害的。因此,关键的问题是如何研究连续学习中任务的相关性,利用任务之间的关系对其他任务并入当前任务的特征进行过滤,从而控制不相关任务的负面影响。
技术实现要素:
本发明的目的是提供一种基于门控制机制的连续学习方法,以在不降低薄膜透光率的情况下,提高银纳米线透明导电膜的导电性。
为了实现上述目的,本发明提供一种基于门控制机制的连续学习方法,包括如下步骤:
(1)针对当前任务,对数据进行预处理,并根据任务搭建相应的深度神经网络模型,包括基础模型与全连接层;
(2)固定前面任务模型的参数,并与当前模型在层级粒度上进行连接;
(3)在模型连接上建立迁移门,以控制迁移的特征的流入,完成自适应地将前面学习到的特征迁移到当前任务模型中;
(4)将数据输入到前面任务的模型和当前任务模型中,进行端到端的训练。
进一步地,步骤(1)中所述的对当前任务数据进行预处理,并根据任务搭建相应的神经网络模型,包括以下步骤:
对数据进行预处理,包括去均值和归一化,并采用翻转、随机裁剪、白化和随机旋转0-25度角的方式对数据进行扩增;
然后,根据任务类型搭建深度神经网络,包括输入层、卷积层构成的基础模型模块和全连接层和输出层构成的全连接层模块。
进一步地,步骤(2)中所述的固定前面任务模型的参数,并与当前模型在层级粒度上进行连接,包括以下步骤:
对每个任务单独建模,设计基于神经网络的多任务连续学习框架来避免灾难性遗忘;给定两个任务,在数据da上训练taska后将模型参数固定,在学习新的任务时,构建新的主干模型modelb并初始化参数,同时与枝干模型modela侧连构建转移矩阵u,在新的数据集db上训练时,通过侧连将原模型在新的数据上提取的特征迁移到当前任务中,得到modelb;具体形式如下:
其中
进一步地,步骤(3)中所述的在模型连接上建立迁移门,以控制迁移的特征的流入,完成自适应地将前面学习到的特征迁移到当前任务模型中,包括以下步骤:
设计gate机制来判定任务间的关联关系,防止不相关任务间的特征流入来避免对学习新任务的干扰;
首先,当第k个任务对应的模型modelk'第l-1层主干网络特征通过连接
在网络隐层之间,每个memorycell有一个内部状态
定义一个记忆门来控制前面k-1个任务提取的特征流入第k个任务l层的memorycell
定义如下:
其中σ(·)是sigmoid激活函数,其取值范围在[0,1]之间;
定义一个memorycell用来存储所有任务的累积信息,随着深度变化,通过联合上一层的所有侧连的输入与cellstate完成更新;
其中⊙表示逐个元素相乘,
memorycelloutput类似lstm,完成cell更新后,需要据此计算该隐藏层的输出;
其中,
进一步地,步骤(4)中所述的将数据输入到前面任务的模型和当前任务模型中,进行端到端的训练,包括以下步骤:
将预处理的数据,分别放到以前的模型和当前任务的模型进行训练,包括定义目标函数、优化方法、评价指标以及模型测试。
通过上述技术方案,可以实现以下有益的技术效果:
1)本发明基于网络结构正则化,对已学任务相应参数进行固定,可以有效克服灾难性遗忘的发生;
2)本发明采用多任务在特征层面相互连接的机制,并引入门控制的机制,可以自适应的学习前面任务对当前任务学习有益的知识,能够有效提升当前任务的训练精度和收敛速度。
本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本发明实施例的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本发明实施例,但并不构成对本发明实施例的限制。在附图中:
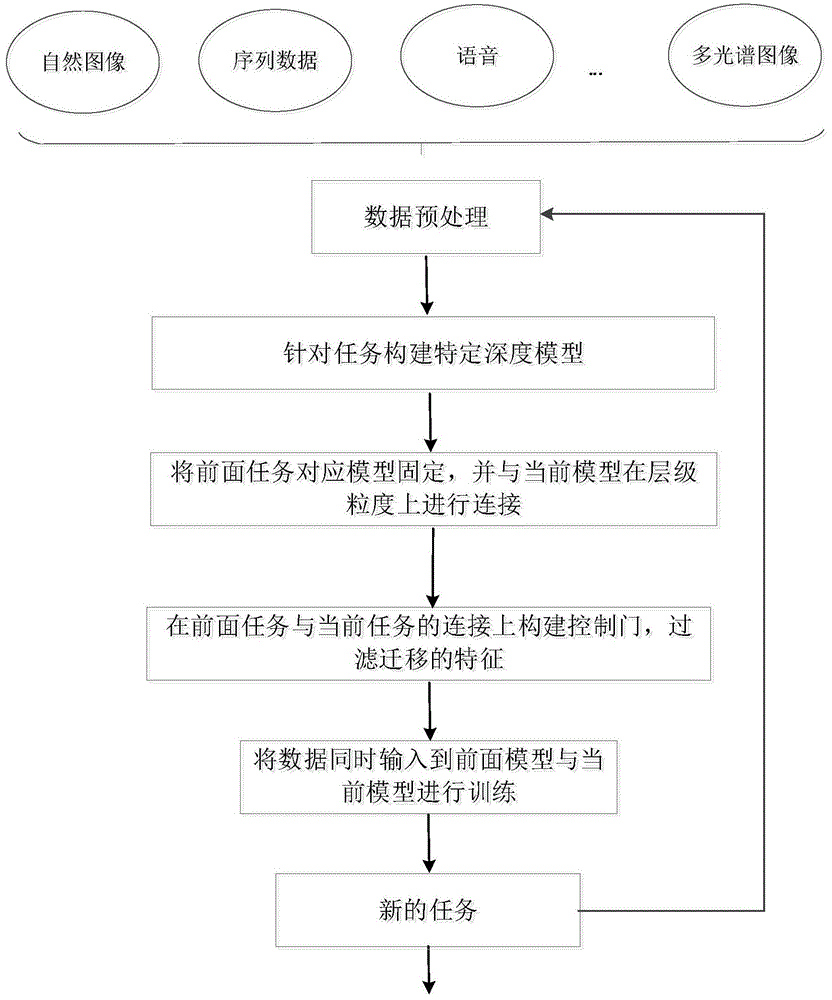
图1示出了本发明一个实施例的流程图;
图2示出基于门控制机制的连续学习方法结合深度神经网络的整体框架;
图3示出了基于门控制机制控制前后任务知识迁移的具体原理;
图4示出了在10个mnist手写数字识别任务上的结果;
图5示出了在不同任务关系的序列任务上连续学习的结果,其中(a)为分别在mnist、svhn、stl10、cifar10上训练3层的cnn模型;(b)为在训练好第一个任务后,继续学习cifar100任务;(c)为连续学习模型在cifar100任务上的训练精度曲线。
具体实施方式
以下结合附图对本发明实施例的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本发明实施例,并不用于限制本发明实施例。
如图1所示,在本发明的一个实施例中,基于门控制机制的连续学习方法包括如下步骤:
步骤1:针对当前任务,对数据进行预处理,并根据任务搭建相应的深度神经网络模型,包括基础模型与全连接层;
具体地,首先,对数据进行预处理,包括去均值和归一化,并采用翻转、随机裁剪、白化和随机旋转0-25度角的方式对数据进行扩增;
然后,根据任务类型搭建深度神经网络,包括输入层、卷积层构成的基础模型模块和全连接层和输出层构成的全连接层模块。
最后,定义每个层的具体参数,包括卷积核大小、池化层窗口大小和滑动步长以及输出通道数目。
步骤2:固定前面任务模型的参数,并与当前模型在层级粒度上进行连接;
具体地,定义好当前任务的基础网络后,对每个任务单独建模,设计基于神经网络的多任务连续学习框架来避免灾难性遗忘。举例,给定两个任务a和b:
首先,在数据da上训练taska后将模型参数固定,防止其再度更新,从而保护a任务发生灾难性遗忘;
然后,在学习新的任务时,构建新的主干模型modelb并初始化参数,这里初始化参数的方式采用高斯分布的随机参数初始化,
最后与枝干模型modela侧连构建转移矩阵u,在新的数据集db上训练时,通过侧连将原模型在新的数据上提取的特征迁移到当前任务中,得到modelb。具体形式如下:
其中
步骤3:在模型连接上建立迁移门,以控制迁移的特征的流入,完成自适应地将前面学习到的特征迁移到当前任务模型中;
具体地,首先,当第k个任务对应的模型modelk'第l-1层主干网络特征通过连接
然后,在网络隐层之间,每个memorycell有一个内部状态
最后,设置基于门的机制,其由三个部分组成:记忆门、记忆细胞状态和记忆细胞输出。
记忆门-定义一个记忆门来控制前面k-1个任务的提取的特征流入第k个任务l层的memorycell
其中σ(·)是sigmoid激活函数,其取值范围在[0,1]之间;
memorycellstates-定义一个memorycell用来存储所有任务的累积信息,随着深度变化,通过联合上一层的所有侧连的输入与cellstate完成更新。
其中⊙表示逐个元素相乘,
memorycelloutput-完成cell更新后,需要据此计算该隐藏层的输出,这里我们没有额外的再定制一个输出门用来控制输出,而是保留了所有信息。
其中,
步骤4:将数据输入到前面任务的模型和当前任务模型中,进行端到端的训练;
具体地,将预处理的数据,分别放到以前的模型和当前任务的模型进行训练,包括定义目标函数、优化方法和评价指标以及模型测试;
首先定义目标函数,如果是分类任务则定义为交叉熵函数,如果是预测任务则定义为均方误差函数;
其次选择合适的优化方法,包括随机梯度下降、adam和梯度下降等方法;
然后构建评价体系,包括平均精度、iou等;
最后对模型进行测试,这里需要注意的是,模型测试过程中dropout函数keepprob值设置为1。
为了测试本发明的连续学习能力,将mnist数据作为原始数据,将数据集打乱处理,得到了10个不同的mnist数据集作为测试集,然后依次放入mlp模型中训练。
如图2所示,搭建了一个连续学习的基本框架。
在数据da上训练taska后将模型参数固定,防止其再度更新,从而保护a任务发生灾难性遗忘;
然后,在学习新的任务时,构建新的主干模型modelb并初始化参数,这里初始化参数的方式采用高斯分布的随机参数初始化,
最后与枝干模型modela侧连构建转移矩阵u,在新的数据集db上训练时,通过侧连将原模型在新的数据上提取的特征迁移到当前任务中,得到modelb。具体形式如下:
其中
然后,在前面任务与当前任务对应模型的侧链间加入记忆迁移门,来控制前面任务特征的流入,对提升当前任务表现的特征会被允许流入,而无用的甚至对当前任务学习有影响的特征会被限制流入,如图3。
设计类似的gate机制来判定任务间的关联关系,防止不相关任务间的特征流入来避免对学习新任务的干扰。
首先,当第k个任务对应的模型modelk'第l-1层主干网络特征通过连接
在网络隐层之间,每个memorycell有一个内部状态
记忆门-定义一个记忆门来控制前面k-1个任务提取的特征流入第k个任务l层的memorycell
其中σ(·)是sigmoid激活函数,其取值范围在[0,1]之间;
memorycellstate-定义一个memorycell用来存储所有任务的累积信息,随着深度变化,通过联合上一层的所有侧连的输入与cellstate完成更新;
其中⊙表示逐个元素相乘,
memorycelloutput-类似lstm,完成cell更新后,需要据此计算该隐藏层的输出,这里我们没有额外的再定制一个输出门用来控制输出,而是保留了所有信息。
其中,
说明,对所有任务采用了相同的主干网络结构(784-32-10)。训练完一个任务后,模型参数会被固定防止其在学习新任务时更新。同时,为了保证结果具有可对比性,在训练所有任务过程中,模型超参数保持一致,包括学习率设置为0.01,采用高斯分布初始化神经网络参数,使用随机梯度下降(sgd)优化策略。
如图4所示,结果表明,基于门机制控制的方法能够有效学习10个任务,并通过前面学习的任务改善后续任务的学习表现。纵轴代表在lenet网络和基于门控制机制的连续学习模型上的测试精度,横轴表示不同的任务,红线代表每个任务在lenet上从头训练的测试结果,绿线代表本发明方法在每个任务上取得测试精度。在学习第一个任务时,两个模型的结构一致,因此两条线的初始值一致,随着学习任务数量增加,连续学习模型的精度总大于单独的模型从头训练结果,而且精度的最高提升达到1.6%左右。
任务间相关关系的变化会影响连续学习的过程,不同任务关系对学习新任务会存在影响,结果表明本发明技术能够有效利用任务间的关系,将前面任务学习到的知识引入到当前任务学习中。如图5所示,分别在mnist、svhn、stl10和cifar10任务上训练模型,然后继续在cifar100数据上学习100类对象识别任务。对比了不同任务对后续任务学习的影响,发现相比其他三个任务,学习cifar10的任务能够较大的改善后面学习cifar100任务。对比从头训练,四类任务都能加快收敛的速度,相比其他三个数据集上的任务,学习cifar10后再学习cifar100的模型随着迭代次数增加精度快速上升,而其他三类任务表现差异不大。
与现有方法相比,本发明的优点在于:1)本发明基于网络结构正则化,对已学任务相应参数进行固定,可以有效克服灾难性遗忘的发生;2)本发明采用多任务在特征层面相互连接的机制,并引入门控制的机制,可以自适应的学习前面任务对当前任务学习有益的知识,能够有效提升当前任务的训练精度和收敛速度。
以上结合附图详细描述了本发明实施例的可选实施方式,但是,本发明实施例并不限于上述实施方式中的具体细节,在本发明实施例的技术构思范围内,可以对本发明实施例的技术方案进行多种简单变型,这些简单变型均属于本发明实施例的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合。为了避免不必要的重复,本发明实施例对各种可能的组合方式不再另行说明。
此外,本发明实施例的各种不同的实施方式之间也可以进行任意组合,只要其不违背本发明实施例的思想,其同样应当视为本发明实施例所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!