基于重采样的集成特征选择算法的生产线故障判断方法与流程
本发明涉及半导体制造企业芯片制造过程故障判断技术领域,尤其是涉及一种基于重采样的集成特征选择算法的生产线故障判断方法。
背景技术:
随着智能电子设备在人们生活中的广泛应用,全球半导体市场在近几年得到高速发展。然而与集成电路设计业在产业结构中所占比例大幅提升的形势不同,晶圆制造业所占比重并没有太多变化,晶圆制造商们仍面临着严峻的市场挑战。
半导体生产线制造过程中可能会遭遇一些不按既定调度计划安排的事件,如生产线故障、紧急订单等。其中故障按照其发生的速度可分为突发性故障和渐发性故障,突发性故障的代表事件为设备宕机,渐发性故障的代表时间则是设备老化。反应到生产调度模型中,用以描述这类事件发生的参数就是非正常状态参数,包括故障是否发生参数、设备维护计划参数、设备修复时间参数等。对于半导体制造企业来说,只有对cps信息模型中的非正常状态参数有着精准的监控与预测技术,才可以掌控物理生产线的制造状态,防患于未然,或出现问题及时发现,才能保持生产线健康运行,在市场上保持竞争力。
通过对现有技术的检索发现,针对故障预测已有不少专家学者提出方法并申请专利,但其研究对象大多为设备级的单一对象,鲜有涉及到大规模制造系统复杂加工环境的故障分析方法。中国专利“一种基于机器学习的故障预测方法”(授权号:cn108304941a)中,乔立中等人提出一种基于机器学习的故障预测方法。该方法通过采集待预测对象的设定运行指标数据,得到每一设定运行指标的时间序列数据;并进行特征提取,将提取的特征输入到机器学习系统中进行训练,得到基础故障预测模型。其方法具有通用性但未明确其验证对象及效果。中国专利“一种基于深度学习的工业设备故障预测方法”(授权号:cn107238507a)中,黄坤山等人通过传感器采集工业设备传感数据,然后根据传感数据固定时间内的时序波获取频谱图,最后采用基于卷积神经网络框架的深度学习算法根据频谱图对工业设备进行故障预测,准确地预测工业设备故障与否。中国专利“一种基于多维时间序列的电气设备故障预测方法”(授权号:cn103996077a)中,姚浩等人针对电气设备的故障提出了一种基于多为时间序列的预测方法。该方法通过高密集采样的在线运行电气测量数据,分析有关联关系的其他设备的变化特征,即将故障的“前兆事件”挖掘出来,形成设备故障预测模型,结合在线监测数据,为复杂非线性电气设备的故障预测与判断提供有力支撑。中国专利“一种基于电力大数据可视化神经网络数据挖掘技术的电力故障预测方法”(授权号:cn107992959a)中,洪建光等人提出一种基于电力大数据可视化神经网络数据挖掘技术的电力故障预测方法,该方法包括一电力大数据库、一数据挖掘预处理及可视化处理模块、一可视化bp神经网络数据挖掘模块、一结果输出模块组成,这种以图形化神经网络数据挖掘技术实现故障预测,降低电力大数据使用难度,提高使用效率。中国专利“基于物联网与机器学习的冲床组故障预测方法及其系统”(授权号:cn108334033a)中,赵迎等人通过实时采集冲床组的运行状态参数,并发送至物联网云端,然后根据预先构建的基于随机森林的机床故障预测模型对实时采集的数据进行预测,得到预测结果。以上发明成果大多只涉及设备层的故障预测,并且少有对于复杂制造环境下高维工业大数据特性的研究,不适用于以半导体制造系统为代表的制造环境。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种以实际半导体制造系统的传感器监控数据为基础,以生产线故障发生参数作为调度模型非正常状态参数的代表的基于重采样的集成特征选择算法的生产线故障判断方法。
本发明的目的可以通过以下技术方案来实现:
一种基于重采样的集成特征选择算法的生产线故障判断方法,包括以下步骤:
步骤1:基于重采样方法将不均衡数据集ids构建新的样本子空间;
步骤2:使用随机森林算法对各样本子空间进行特征选择,获取各子空间的特征子集;
步骤3:将各子空间的特征子集合并成新的特征空间合集;
步骤4:使用降噪自编码器对新的特征空间合集进行降维,得到预测模型的输入;
步骤5:根据预测模型的输入采用随机森林算法建立故障预测模型并利用该故障预测模型对生产线进行实时故障监控判断。
进一步地,所述步骤1包括以下分步骤:
步骤11:根据半导体制造系统生产线的监控系统获得生产线各传感器实时监控参数数据;
步骤12:对样本数据进行数据预处理,填补空缺值及利群点检测,得到不均衡数据集ids;
步骤13:随机从不均衡数据集ids所分成的正负两类样本中有放回的抽取样本点并重新构造n个正负比a:b的样本子空间。
进一步地,所述正负比a:b为20:50。
进一步地,所述步骤2包括以下分步骤:
步骤21:利用随机森林算法对各样本子空间进行属性选择并对各样本子空间中所有特征的重要性数值f进行排队;
步骤22:选出各样本子空间中重要性数值f满足设定条件的特征,得到各样本子空间对应的特征子集。
进一步地,所述步骤4包括以下分步骤:
步骤41:对新的特征空间合集进行噪声化,将新的特征空间合集中设定百分比的数据置0,得到新的样本空间合集;
步骤42:针对新的特征空间合集和新的样本空间合集构建神经网络映射关系;
步骤43:对神经网络映射关系中的参数进行优化并得到满足误差的神经网络映射关系,利用降噪自编码器输入层到输出层之间的神经网络架构得到新的特征空间合集降维到x维后的特征空间合集。
进一步地,所述步骤43中的x为20,所述步骤41中的设定百分比为5%。
进一步地,所述步骤42中的神经网络映射关系,其描述公式为:
y=s(wx+b)
式中,y表示新的特征空间合集的特征,w和b表示神经网络映射关系参数,s表示sigmoid函数,x表示新的样本空间合集的特征。
进一步地,所述步骤5包括以下分步骤:
步骤51:抽取训练子集随机森林中的n1棵决策树的生成需对应n1个训练子集;所述训练子集通过bootstrap抽样技术从预测模型的输入中的原始训练集得到;
步骤52:每棵决策树分别经过选取随机特征变量和节点分裂过程开始生长;
步骤53:生成随机森林对每棵树不进行剪枝,使其最大限度地生长,最终所有决策树组成随机森林,并以该随机森林作为故障预测模型;
步骤54:将样本输入故障预测模型的分类器中,对于每个样本每棵决策树都输出对应的预测值并对其类别进行投票,最终投票数最多的一类为该样本最终确定的类别,该最终确定的类别对应的故障类型即为故障监控判断结果。
与现有技术相比,本发明具有以下优点:
(1)适用场景性强,本发明运用随机森林算法提取影响生产线故障的特征因素,较之以往仅凭人工经验确定更具有理论依据;
(2)鲁棒性好,本发明进一步采用降噪自编码器对故障特征影响因素进行降维,可有效实现模型的鲁棒性;
(3)精确度高,本发明对降维后的特征使用随机森林算法构建预测模型,提高了预测结果的精确性。
附图说明
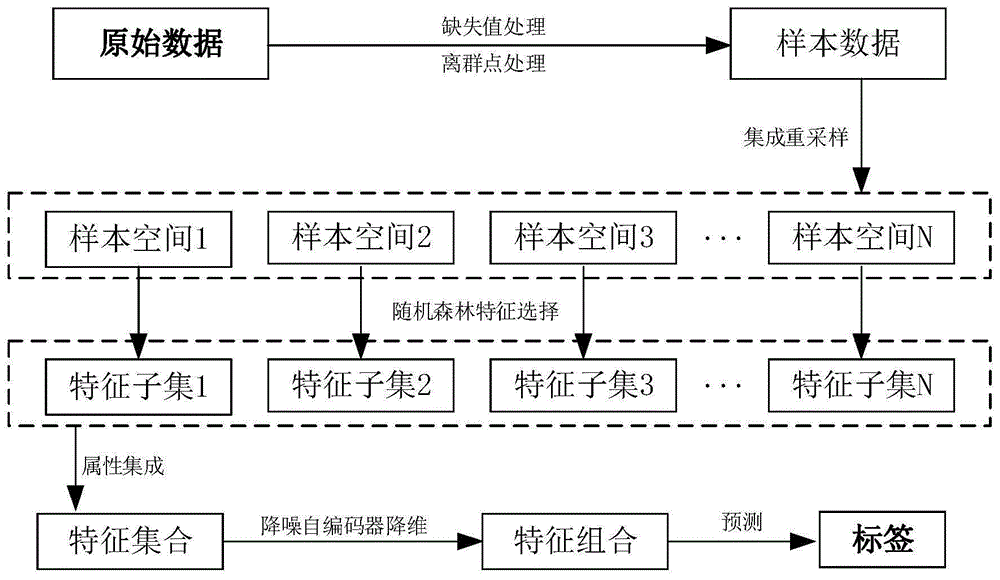
图1为本发明的原理流程图;
图2为本发明实施例中故障模型与其他算法性能指标比较示意图;
图3为本发明实施例中以20维特征为基准条件下的故障模型与其他算法性能指标比较示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明的一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
实施例
如图1所示为本发明一种基于重采样的集成特征选择算法的生产线故障判断方法的流程图,具体地,本实施例中该方法包括以下步骤:
步骤1)基于重采样算法对不均衡数据集(ids)进行样本空间重构。
在具体实施例中,由于半导体制造系统包括多个加工设备,因此,为了实时采集每个设备的运行状态,为每个设备配置多个运行状态采集装置来实时采集运行状态参数,同时对状态参数对应的生产线状态进行标记。由于生产记录中故障样本只占一小部分,故需要确定合适的模型对生产线状态进行预测。
step101:对样本数据进行数据预处理,对数据样本x1,x2,…,xn中的空缺值使用中位数填补。将数据样本x1,x2,…,xn中的数据按数值大小排序得到x1,x2,…,xn,当n为奇数时,m0.5=x(n+1)/2;当n为偶数时,m0.5=(xn/2+xn/2+1)/2,得到不均衡数据集ids(imbalancedataset)sm*n;
step102:将ids中的数据分为正类(故障)与负类(正常)2类样本,随机从2类样本中有放回的抽取样本点,重新构造n个正负比20:50的样本子空间si(i=1,2,…,n),si维度为70×n;
影响生产线故障的监测信号多种多样,这些因素重要程度的高低仅凭机理分析和人工经验难以确定,需要通过数据分析获得更加客观合理的结论。本发明采用一种随机森林的特征选择算法进行样本空间的属性选择。所述随机森林属性选择的过程为:
(1)通过训练子集z{(x1,y1),…,(xn,yn)}构建随机森林模型h={h1,h2,…,hn},设第i棵oob数据集为
(2)对于任意一个特征f,随机置换训练集中特征f的值,得到新的训练集zf,计算决策树hi的准确率
(3)由此,特征对于准确率的影响程度
其中,ef的方差为
其中,基于该平均值和方差计算特征f的重要性,为:
fimp=ef/s(4)
以此可以得到所有特征的重要性。
步骤2)根据重新构建的样本子空间基于随机森林进行属性选择,并重新构建总属性集合。
step201:对原始数据进行归一化处理:
其中,qp为各因素的第p个值,p=1,…,n,qmax、qmin分别为各因素中的最大值和最小值,a、d为参数,d=(1-a)/2;
本实施例中,将原始数据规范到[0,1]区间,a=1。
step202:对步骤1)中的n个正负比20:50的样本子空间si(i=1,2,…,n),分别使用上述随机森林属性选择的过程,对si中的所有特征的重要性进行大小排队;
step203:取fthres=0,选择出si中满足f>fthres的特征di(i=1,2,…,n);
step204:取n个si中得到的特征子集的并集,得到d1∪d2∪…∪di…∪dn的特征集合,特征总数量为d,总样本空间变为sm*d;
本发明采用一种降噪自编码器算法对样本空间进行鲁棒性降维,其过程为:
(1)一个自编码器以x∈[0,1]d作为输入,并且首先将输入通过一个确定性的映射,映射为隐层表示y∈[0,1]d′
y=s(wx+b)
其中,s是一个非线性映射,如sigmoid,隐式表示y,或者叫编码,紧接着被映射回来,形成重构z,它与x有同样的形状大小,这个映射也是通过类似编码映射的变化
z=s(w′y+b′)
(2)z应当被看作给定编码y时对x的预测,对模型的参数w,b,w′,b′进行优化,以使得平均重构误差最小。
重构误差可以从很多方面来衡量,这取决于在给定编码时,对输入的适当的分布假设,可以用传统的均方误差l(x,z)=‖x-z‖2。如果输入被解释为位向量或位概率向量,那么可以使用于输入与重构的交叉熵来衡量:
(3)降噪自编码器da是在自编码器的基础上,训练数据加入噪声,所以自动编码器必须学习去去除这种噪声而获得真正的没有被噪声污染过的输入,因此,这就迫使编码器去学习输入信号更加鲁棒的表达,这也是它的泛化能力比一般编码器强的原因。
步骤3)使用降噪自编码器对总属性集合进行进一步降维。
step301:对样本空间sm*d进行噪声化,将sm*d中5%的数据置0,得到新的样本空间ssm*d;
step302:对空间sm*d和ssm*d构建单隐含层的神经网络映射关系y=s(wx+b),其中,s是sigmoid函数,x为ssm*d的特征,y为sm*d的特征,w和b表示神经网络映射关系参数;
step303:对step302中的w,b进行优化,得到满足误差的神经网络映射关系,保留降噪自编码器输入层到输出层的神经网络架构,得到sm*d降维至20维的特征组合空间sm*20。
步骤4)对最终的属性构建基于随机森林的故障预测模型。
step401:抽取训练子集随机森林中的n2棵决策树的生成需对应n2个训练子集。训练子集主要通过bootstrap抽样技术从原始训练集中得到,未被抽取的数据组成n2个oob(out-of-bag)数据;
step402:每棵决策树的生长主要有2个重要过程:(a选取随机特征变量:随设有n个特征,则在每一棵树的每个节点处随机抽取mtry个特征(mtry≤n);(b节点分裂:通过计算每个特征蕴含的信息量,在mtry个特征中选择一个分类能力最优的特征进行节点分裂;
step403:生成随机森林对每棵树不进行剪枝,使其最大限度地生长,最终所有决策树组成随机森林。
step404:完成随机森林的构建后,将样本输入分类器中,对于每个样本每棵决策树都输出对应的预测值对其类别进行投票,最终投票数最多的一类为该样本最终确定的类别。
以实际半导体制造系统监测信号数据为例,算例集选自uci数据库secom数据集。该数据集有1567个样本,每个样本有590个质量属性及一个标签属性,属性中含有空缺值;样本分为正常和故障2类,故障样本数量为101;正常样本数量为1463个,不均衡比例达到1:14.5。显然,数据属于既具有高维度,又具有类别比例严重失衡性的不平衡数据集。
为验证和比较模型精度和性能,本实施例选取以下9个评价指标:
1)
tpr(tprate/recall)=tp/(tp+fn)
2)
tnr(tnrate)=tn/(tn+fp)
3)
precision=tp/(tp+fp)
4)
accuracy=(tp+tn)/(tp+tn+fp+fn)
5)
errorrate=1–accuracy
6)
f-measure=2*recall*precision/(recall+precision)
7)
8)
9)
ber=1-(tpr+tnr)/2
g-mean是tpr及tnr的几何平均数,取值于区间[0,1],g-mean的值越大表示多数类和少数类的分类错误都很低,即分类效果越好;f-measure是precision和recall的调和平均数,precision描述了所有预测为正类的样本中,预测正确的概率,recall代表正确预测的正类数量与样本总正类样本数量的比值,f-measure的值随fp的增大而减小。z-mean为作者参照g-mean设计的指标,取值于区间[0,1],z-mean的值越大可以保证多数类和少数类的分类错误都很低,且同时可以平衡总分类错误率很低,使得分类效果越好。ber则表示正负类样本分类的平均错误率,ber值越低表示分类效果越好。
为了全面验证所提出的故障分析方法的有效性,首先在维度最终约减到20维与60维的情况下,将本模型的预测结果与knn,one-classsvm两种模型进行比较,如表1及与其对应的图2所示。
表1各算法预测结果比较
需要说明的是,本发明中特征属性的维度最终选择为20维。此外,由于secom官方提供了几种算法的性能指标,因此,本发明以20维特征为基准与其他算法进行性能指标对比,如表2及其对应的图3所示。
表2与secom官方算法预测结果比较
因此,从准确性与计算效率考虑,本发明提出的基于重采样的集成特征选择故障分析方法在所有性能指标上均领先其他算法,较好地解决了复杂生产线监控系统采集数据的不平衡性和高维度带来的负面影响。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到各种等效的修改或替换,这些修改或替换都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!