基于注意力机制和自编码器的玻璃炉温智能预测控制方法与流程
本发明涉及玻璃窑炉熔化池温度自动控制技术领域,具体涉及一种基于注意力机制和自编码器的玻璃炉温智能预测控制方法。
背景技术:
玻璃窑炉熔化池温度控制效果直接关系到玻璃制品质量的好坏,进而影响玻璃制品成品率的高低。所以玻璃窑炉温度控制的稳定性至关重要。目前在玻璃生产中,窑炉温度控制己普遍采用计算机进行控制,但最常用的控制方法仍是普通pid控制(包括单回路、串级回路和分程控制等都是由pid作为基本的控制算法),一些改进的方法包括smith预估补偿加pid控制和模糊控制等。
对窑炉温度进行的动态特性分析表明,一般情况下玻璃窑炉是一个大惯性、大滞后并具有非线性特征的变参数系统。而且窑炉在运行过程中还可能受到多种扰动因素如煤气压力波动、进料质量波动、窑炉保温性能变化、工作环境温度变化等的影响。鉴于玻璃窑炉的上述特性,现行的控制方法难以满足对窑炉温度控制的高性能要求。如单纯的pid控制对滞后较大的窑炉控制效果不好,难以适应对象参数的变化,且存在快速性与超调量之间的矛盾。smith控制方法的设计又过分依赖于被控对象的精确模型,当参数变化时或模型误差较大时控制性能显著变坏。
技术实现要素:
本发明要解决的技术问题,在于提出一种基于注意力机制和自编码器的玻璃炉温智能预测控制方法。
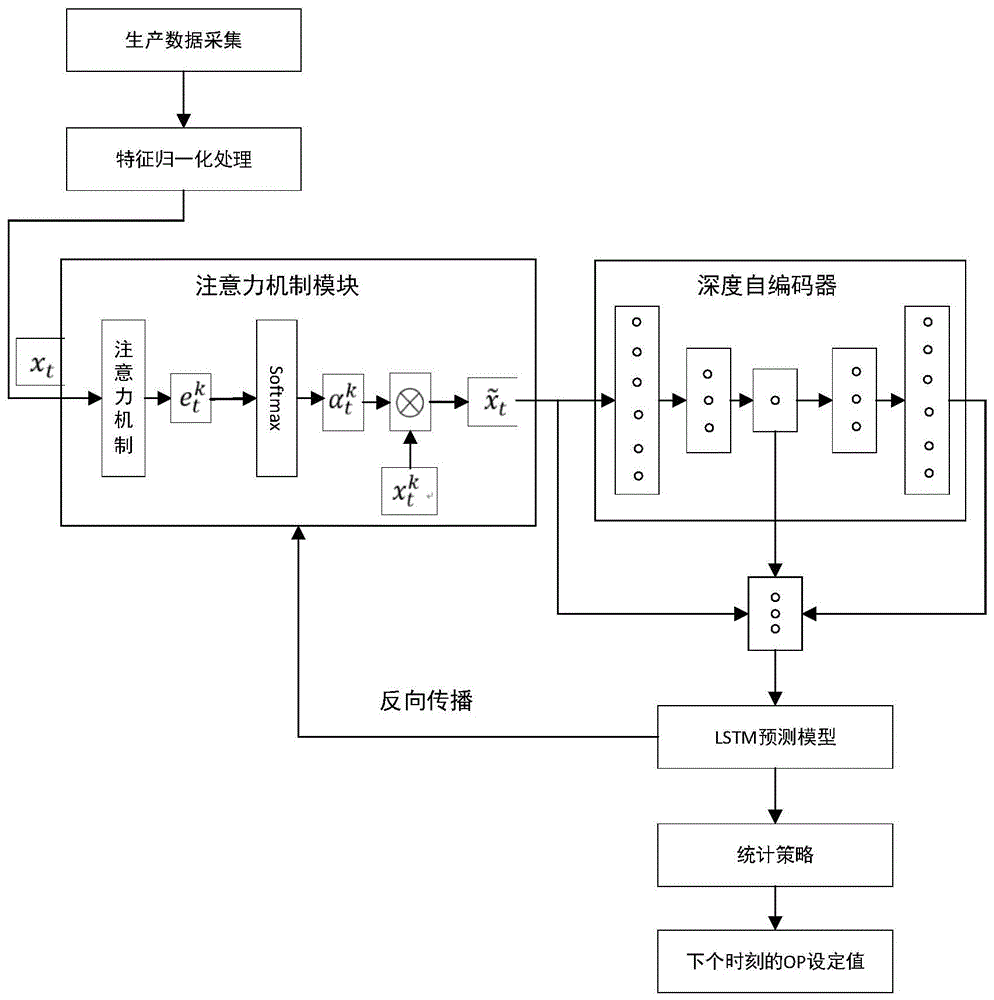
本发明解决其技术问题所采用的技术方案是一种基于注意力机制和自编码器的玻璃炉温智能预测控制方法,包括以下步骤,
步骤1,采集与预处理玻璃窑炉温度预测控制相关的生产历史数据;
步骤2,根据预处理得到的输入变量,采用注意力机制,得到每个时刻每个熔炉温度都带有注意力权重的输入变量;
步骤3,根据深度自编码器的重构误差,得到两个表示向量,包括相对欧式距离和余弦相似度,并结合深度自编码器中的编码器产生的潜在表示一起组成最终的低维表示;
步骤4,根据低维表示,采用lstm预测模型,得到后面若干时间步长熔炉温度的预测值;
步骤5,根据lstm预测模型和统计策略相结合的控制方式,对玻璃熔炉天然气流量和氧气流量进行在线智能调整。
而且,步骤1中,采集玻璃熔炉碹顶温度实时测量值、玻璃熔炉池底温度实时测量值、天然气流量实时测量值和氧气流量实时测量值;
对玻璃熔炉碹顶温度和玻璃熔炉池底温度进行min-max归一化处理;
对天然气流量实时测量值和氧气流量实时测量值进行log归一化处理;
将多个时刻的经过归一化处理后的熔炉碹顶温度实时测量值、熔炉池底温度实时测量值、天然气流量实时测量值、氧气流量实时测量值,组成输入变量x。
而且,步骤2实现方式为,
通过把输入变量x传入到注意力机制模块中,得到对每个特征进行了加权后的时刻t时的输入变量
其中会使用t时刻的带有加权的输入变量
而且,步骤3的实现如下,
根据输入向量
根据相对欧式距离得到表示向量z1,
根据余弦相似度得到表示向量z2,
根据深度自编码器中编码器输出的潜在表示zc和表示向量z1和z2,确定低维表示z,z=(zc,z1,z2)。
而且,步骤4实现方式为,
将低维表示z传入3层的lstm预测模型中,得到下一个时刻的预测值xt+1,重复该操作p次,得到p个时间步长的预测值(xt+1,xt+2,…,xt+p+1)。
而且,步骤4实现方式包括以下步骤,
1)根据工业玻璃生产要求的熔炉温度允许的波动范围,当通过预测模型预测得到当前时刻t+1的温度值不正常时刻时,确定天然气流量和氧气流量对应的最大最小设定值;
2)确定需要调整的天然气流量和氧气流量的设定值;
根据t+1时刻的天然气流量和氧气流量的最大最小设定值,对比t+1时刻的天然气流量和氧气流量的实时值,调整如下,
其中,opt+1表示的是t+1时刻的天然气流量和氧气流量的实时值,
本发明和现有技术的区别以及相应产生的技术效果是:现有技术没有考虑到玻璃窑炉温度控制中输入向量的高维度和时间序列这两个数据特性,本发明首先考虑到输入向量中包含连续时间序列的特性,通过注意力机制,输入向量就可以在每个时刻选择性的聚集于某些主要特征,而不是传统的考虑每一时刻的所有特征;其次,本发明考虑到输入向量的高维的问题,如果直接拿来做模型的训练,会导致“维度灾难”的问题,所以,通过深度自编码器来对输入向量进行降维处理,得到带有输入向量重要信息的低维表示,进而在低维空间中进行窑炉温度的预测;最后,本发明通过预测、反馈、统计相结合的方法,实现窑炉温度的智能控制。通过本发明所述技术,可以实现玻璃窑炉温度的智能预测以及动态控制,从而实现玻璃质量的提高。本发明特别适合应用于大规模玻璃制造,具有重要的市场价值。
附图说明
图1为本发明实施例的流程图。
具体实施方式
以下结合附图和实施例详细说明本发明技术方案。
本发明实施例提供一种基于注意力机制和自编码器的玻璃炉温智能预测控制方法,包括以下步骤:
步骤(1):数据预处理:采集与预处理玻璃窑炉温度预测控制相关的生产历史数据。
步骤(1.1):玻璃熔炉历史数据采集
本发明采集与玻璃窑炉温度控制相关的生产信息,因为玻璃熔炉上部署的用来检测和调节变量指标的传感器有1000多个,经过分析后,本发明需要的特征数据主要包括:玻璃熔炉碹顶温度实时测量值、玻璃熔炉池底温度实时测量值、天然气流量实时测量值和氧气流量实时测量值;
步骤(1.2):特征归一化处理
对采集到的玻璃熔炉碹顶温度实时测量值、玻璃熔炉池底温度实时测量值、天然气流量实时测量值、氧气流量实时测量值进行每分钟数据的填充对齐,得到四个同样时间间隔的熔炉特征;然后对熔炉特征进行统计分析,得出各自的最大值和最小值;因为数据中,不同特征之间的量纲是不同的,需要对数据进行归一化处理:
实施例中,
对采集到的玻璃熔炉碹顶温度实时测量值、玻璃熔炉池底温度实时测量值、天然气流量实时测量值、氧气流量实时测量值进行统计分析,得出各自的最大值和最小值;因为数据中,不同特征之间的量纲是不同的,需要对数据进行归一化处理:
对玻璃熔炉碹顶温度实时测量值和玻璃熔炉池底温度实时测量值进行最小值-最大值标准化min-maxnormalization,具体公式如下:
其中,x表示熔炉碹顶温度实时测量值或玻璃熔炉池底温度实时测量值,xmin表示该特征的最小值,xmax表示该特征的最大值,x*表示该特征进行min-max归一化之后的值;
对天然气流量实时测量值、氧气流量实时测量值进行对数归一化lognormalization,具体公式如下:
y*=log(y+1)
其中,y表示天然气流量实时测量值或氧气流量实时测量值,log表示以自然数e为底的对数,y*表示该特征进行对数归一化后的值;
步骤(1.3):得到输入序列
将多个时刻的数据组成输入序列x,每个时刻的数据包括该时刻相应经过归一化处理后的熔炉碹顶温度实时测量值、熔炉池底温度实时测量值、天然气流量实时测量值、氧气流量实时测量值:
其中,
用
步骤(2):基于注意力机制的每个时刻带有注意力权重的特征确定;
实施例中,把输入向量x传入到注意力机制模块中,就可以得到对时刻t的数据xt每个特征进行了加权后的新的输入变量
实施例中,具体步骤2实现过程如下:
步骤(2.1):设置注意力机制中相关变量的初始值,具体包括:
权重矩阵w,
权重矩阵u,
权重矩阵v,
令t=1,
lstm的t-1时刻隐层状态st-1,
其中n表示一个批次大小,即每次循环时使用n个输入序列进行训练,如x1=(x1,x2,…,xt),x2=(x2,x3,…,xt+1),…,xn=(xn,xn+1,…,xn+t),其中,x1表示第一个输入序列,…,xn表示第n个输入序列,根据数据集从小到大,建议n取值为16、32、64、128、256或512;
lstm的t-1时刻隐层状态ht-1,
其中lstm表示longshort-termmemory,即长短期记忆神经网络单元。
具体实施时,这些变量作为模型的超参数可以预先设定,例如根据数据集的特征分析来设定。
步骤(2.2):得到时刻t带有权重的特征的输入向量
步骤(2.2.1):设对于输入向量x的第k个特征,得到t时刻第k个特征的注意力初始权重
其中
按此,可以得到所有特征的注意力初始权重
步骤(2.2.2):对得到的t时刻的n个特征的注意力初始权重做归一化处理(softmax),对于输入向量x的第k个特征,归一化处理具体公式如下:
其中,exp表示以自然常数e为底的指数函数,
步骤(2.2.3):使用注意力权重
其中
步骤(2.2.4):更新t时刻lstm的隐层状态st和ht,具体公式如下:
其中,lstm()表示调用长短期记忆神经网络单元;
步骤(2.3):令t=t+1,返回执行步骤(2.2),直到t=t,通过对步骤(2.2)迭代执行t次,就可以得到每个时刻带有注意力权重的输入向量
基于注意力机制,新的输入向量就可以选择性地聚焦于某一特征,而不是对所有输入特征序列一视同仁;
步骤(3):基于深度自编码器的带有重要信息的潜在表示确定:根据深度自编码器的重构误差,得到两个表示向量,并结合深度自编码器中的编码器产生的潜在表示一起组成最终的低维表示;
把注意力机制模块的输出
注意力机制模块的输出向量
编码器的输出潜在表示zc经过深度自编码器的解码器后,会得到一个重构的输入向量
深度自编码器的目的是为了得到和输入向量
本发明中,解码器和编码器是对称结构,例如编码器是3层的,其中每层节点数为(120,60,1),那么解码器就是(1,60,120),其中的1是公共的,即编码器的输出就是解码器的输入。
步骤(4):低维表示z的确定;
步骤(4.1):根据步骤(3)中的输入向量
根据相对欧式距离得到表示向量z1,具体公式如下:
其中||·||2表示的是2-范数;
根据余弦相似度得到表示向量z2,具体公式如下:
步骤(4.2):根据步骤(2)中得到的潜在表示zc和步骤(4.1)得到表示向量z1和z2,拼接确定低维表示z,具体公式如下:
z=(zc,z1,z2)
注意:zc,z1,z2是按照最后一个维度进行拼接的;即假设
步骤(5):lstm预测模型:根据低维表示,采用lstm预测模型,得到后面p个时间步长的熔炉温度的预测值;
把步骤(4)得到低维表示z传入3层的lstm预测模型中,可以得到下一个时刻的预测值xt+1,重复该步骤p次(p表示循环变量,建议取值小于10),就可以得到p个时间步长的预测值(xt+1,xt+2,…,xt+p+1);
步骤(6):确定模型的目标函数:
其中n表示一个批次大小,j表示循环变量,
步骤(7):通过预测模型和统计策略相结合的熔炉温度智能控制:根据lstm预测模型和统计策略相结合的控制方法,对玻璃熔炉天然气流量和氧气流量进行在线智能调整。
实施例的具体实现如下:
步骤(7.1):根据工业玻璃生产要求的熔炉温度允许的波动范围(如波动不大于正负2摄氏度),指定出相应的熔炉碹顶温度和池底温度对应的最大最小的设定值;当步骤(5)输出的熔炉温度的预测值在设定的最大最小设定值的范围内,就说明当前熔炉温度控制良好;当步骤(5)输出的熔炉温度的预测值在设定的最大最小设定值的范围外时,说明当前时刻得到的熔炉温度值是不正常的,需要进行相关的天然气流量和氧气流量这些开关量的调节,从而使温度恢复到设定值范围内。
假设通过预测模型预测得到当前时刻t+1的温度值不正常,但是前一个时刻t的温度值是正常的,因此,去查找前一个时刻t对应的天然气流量和氧气流量的实时值,根据玻璃工艺天然气流量和氧气流量开度的允许波动范围(如正负0.5),最终确定t+1时刻的天然气流量和氧气流量对应的最大最小设定值。通过判断t+1时刻的真实的天然气流量和氧气流量开度和其对应的最大最小设定值来进行对应控制量的参数值调整,从而实现t+1时刻温度的正常;步骤(7.2):确定需要调整的天然气流量和氧气流量的设定值;
根据步骤(7.1)得到了t+1时刻的天然气流量和氧气流量的最大最小设定值,对比t+1时刻的天然气流量和氧气流量的实时值,进行如下的调整:
其中,opt+1表示的是t+1时刻的天然气流量和氧气流量的实时值,
具体实施时,可以采用计算机软件技术实现以上流程的自动运行,运行流程的装置也应当在本发明的保护范围内。
本发明具有如下优点:通过注意力机制模块,输入向量就可以选择性地聚焦于某一特征,而不是对所有输入特征序列一视同仁;通过深度自编码器可以得到输入向量的潜在表示,这个潜在表示是一种带有输入向量重要特征信息的低维表示,对于熔炉这种特征个数过多的数据,这低维表示可以节约大量的模型训练时间;最后通过端到端的联合训练可以有效增强注意力机制模块、深度自编码器、lstm预测模型彼此的性能,同时通过尽可能低的自编码器的重构误差可以学习到带有大量重要信息的潜在表示。
虽然以上描述了本发明的具体实时方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施列只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的。因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!