基于全局保持无监督核极限学习机的故障检测方法及系统与流程
本公开属于非线性多变量工业过程故障检测技术领域,尤其涉及一种基于全局保持无监督核极限学习机的故障检测方法及系统。
背景技术:
本部分的陈述仅仅是提供了与本公开相关的背景技术信息,不必然构成在先技术。
由于现代工业系统日益趋于高集成、大规模化,工业过程的故障诊断已经成为保证现代工业系统安全稳定运行的关键技术。随着现代计算机控制技术的发展,工业过程中采集并存储了丰富的过程运行数据。因此,基于数据驱动的故障检测与诊断技术逐渐成为工业过程监控领域的研究热点。研究人员提出了一系列基于数据驱动的故障检测与诊断方法,比如主元分析(pca)、偏最小二乘(pls)和极限学习机(elm)等。然而大多数的工业生产过程往往是非线性的,上述提到的线性监控方法在适用场合上具有很大的局限性。因此针对过程数据的非线性特征,如何从测量数据中提取出有用的特征信息以监控工业过程的运行状态是一种具有挑战性的研究课题。
为了挖掘工业过程数据中的非线性特征,基于核函数技术的极限学习机方法逐渐被引入非线性故障检测与诊断领域。huang等人提出了基于无监督核极限学习机的工业过程故障诊断方法(huangg.,songs.j.,guptaj.n.d.,wuc.:semi-supervisedandunsupervisedextremelearningmachines.ieeetransactionsoncybernetics,2014,44(12):2405-2417)。近几年来,无监督极限学习机作为一种有效的工业生产过程故障检测技术,引起了国内外研究人员的广泛关注。该方法首先将过程数据从原始空间非线性映射到高维特征空间,然后在高维空间中提取-表征过程运行状态的低维特征信息,有效解决了过程数据的非线性特征。虽然无监督极限学习机技术在非线性工业过程故障检测领域取得一定的应用成果,但是发明人发现,其缺点在于:(1)无监督极限学习机将过程数据非线性变换到高维特征空间时需要事先确定隐含层节点的数目,然而隐含层节点数目的选择一直是个棘手的问题。(2)无监督极限学习机在提取过程数据的低维特征信息时只保持了数据的局部结构信息而忽略了其全局结构信息,然而在提取特征时忽略过程数据中蕴含的全局结构信息,会影响故障检测的效果。
技术实现要素:
为了解决上述问题,本公开提供一种基于全局保持无监督核极限学习机的故障检测方法及系统,其首先将全局结构分析技术融入到无监督极限学习机中构造全局保持无监督极限学习机放法,在提取过程数据的低维特征时同时保持数据的局部和全局结构信息;然后将核函数技巧与全局保持无监督极限学习机相结合,解决了将过程数据非线性变换到高维特征空间时需要确定隐含层节点数目的问题;最后基于提取出的低维局部和全局结构特征信息,应用支持向量数据描述技术构建监控统计量,实时监控工业过程的运行状态。
为了实现上述目的,本公开采用如下技术方案:
本公开的第一个方面提供一种基于全局保持无监督核极限学习机的故障检测方法。
一种基于全局保持无监督核极限学习机的故障检测方法,包括:
离线建模步骤,其过程为:
利用归一化的训练数据集,构建全局保持无监督极限学习机的数学模型;所述训练数据集中的训练数据均为非线性工作过程正常操作工况数据;
将全局保持无监督极限学习机的最优化问题转化为广义特征值分解问题,得到广义特征值分解问题数学公式表述,利用核函数更新广义特征值分解问题数学公式表述,计算全局保持无监督核极限学习机输出加权矩阵的最终解;
根据输出加权矩阵的最终解从归一化的训练数据集中提取保持局部和全局结构的低维特征信息矩阵,再利用支持向量数据描述算法构建出监控统计量并确定其控制限;
在线监控步骤,其过程为:
对测试数据进行归一化处理;其中,测试数据为非线性工作过程工况数据;
根据核函数计算测试数据的核向量,并在特征空间中对核向量进行均值中心化处理,获得测试核向量;
根据全局保持无监督核极限学习机从测试核向量中提取测试数据的低维特征信息矩阵,计算测试数据的监控统计量;
依据测试数据的监控统计量是否超出其控制限,判断非线性工业过程是否发生故障。
作为一种实施方式,在所述离线建模步骤中,使用均值和标准差对训练数据集进行归一化。
需要说明的是,对训练数据集进行归一化的归一化方法也可采用其他现有的方法来实现,本领域技术人员可根据实际情况来具体选择。
作为一种实施方式,在所述离线建模步骤中,利用归一化的训练数据集,构建全局保持无监督极限学习机的数学模型的过程为:
在提取低维特征时为保持数据的局部结构信息,根据归一化的训练数据集构造加权对称矩阵w,基于加权对称矩阵w计算对角矩阵d和拉普拉斯矩阵l,其中l=d-w,构建出无监督极限学习机的数学模型;
在提取低维特征时为保持数据的全局结构信息构,造全局保持结构分析的目标函数,并将其融入到无监督极限学习机的数学模型中,推导出全局保持无监督极限学习机的数学模型。
作为一种实施方式,全局保持无监督核极限学习机输出加权矩阵的最终解等于随机特征映射矩阵的转置矩阵左乘负荷矩阵;其中,负荷矩阵的计算过程为:
求解利用核函数更新广义特征值分解问题数学公式表述的特征值,并按照从小到大排序;由预设数量最小特征值相对应的特征向量构成负荷矩阵。
作为一种实施方式,监控统计量的控制限为位于超球体边界上的任一支撑向量到超球体球心的欧式距离;监控统计量的计算过程为:
d(i)=||φ(ti)-b||
d(i)表示第i个监控统计量,b表示超球体的球心坐标向量,φ(ti)表示低维特征信息矩阵中第i个向量的核函数向量。
作为一种实施方式,在所述在线监控步骤中,若测试数据的监控统计量超出其控制限,则判断非线性工业过程已经发生故障;否则,判断非线性工业过程正常运行。
本公开的第二个方面提供一种基于全局保持无监督核极限学习机的故障检测系统。
一种基于全局保持无监督核极限学习机的故障检测系统,包括:
离线建模模块,其包括:
数学模型构建模块,其用于利用归一化的训练数据集,构建全局保持无监督极限学习机的数学模型;所述训练数据集中的训练数据均为非线性工作过程正常操作工况数据;
输出加权矩阵求解模块,其用于将全局保持无监督极限学习机的最优化问题转化为广义特征值分解问题,得到广义特征值分解问题数学公式表述,利用核函数更新广义特征值分解问题数学公式表述,计算全局保持无监督核极限学习机输出加权矩阵的最终解;
监控统计量及控制限确定模块,其用于根据输出加权矩阵的最终解从归一化的训练数据集中提取保持局部和全局结构的低维特征信息矩阵,再利用支持向量数据描述算法构建出监控统计量并确定其控制限;
在线监控模块,其包括:
测试数据归一化处理模块,其用于对测试数据进行归一化处理;其中,测试数据为非线性工作过程工况数据;
测试核向量计算模块,其用于根据核函数计算测试数据的核向量,并在特征空间中对核向量进行均值中心化处理,获得测试核向量;
测试数据的监控统计量计算模块,其用于根据全局保持无监督核极限学习机从测试核向量中提取测试数据的低维特征信息矩阵,计算测试数据的监控统计量;
故障判断模块,其用于依据测试数据的监控统计量是否超出其控制限,判断非线性工业过程是否发生故障。
作为一种实施方式,在所述故障判断模块中,若测试数据的监控统计量超出其控制限,则判断非线性工业过程已经发生故障;否则,判断非线性工业过程正常运行。
本公开的第三个方面提供一种计算机可读存储介质。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述所述的基于全局保持无监督核极限学习机的故障检测方法中的步骤。
本公开的第四个方面提供一种计算机设备。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现上述所述的基于全局保持无监督核极限学习机的故障检测方法中的步骤。
本公开的有益效果是:
(1)本公开将全局结构分析技术融入到无监督极限学习机中,在提取过程数据的低维特征时同时保持数据的局部和全局结构信息;由于能够捕获过程数据中蕴含的全局结构信息,改善了故障检测的效果;
(2)本公开在全局保持无监督极限学习机将过程数据非线性变换到高维特征空间时引入了核函数技术,通过构造核矩阵解决了传统极限学习机方法需要确定隐含层节点数目的问题。最后从过程数据中提取出低维特征信息后,应用支持向量数据描述算法构建监控统计量,实时检测过程故障。
附图说明
构成本公开的一部分的说明书附图用来提供对本公开的进一步理解,本公开的示意性实施例及其说明用于解释本公开,并不构成对本公开的不当限定。
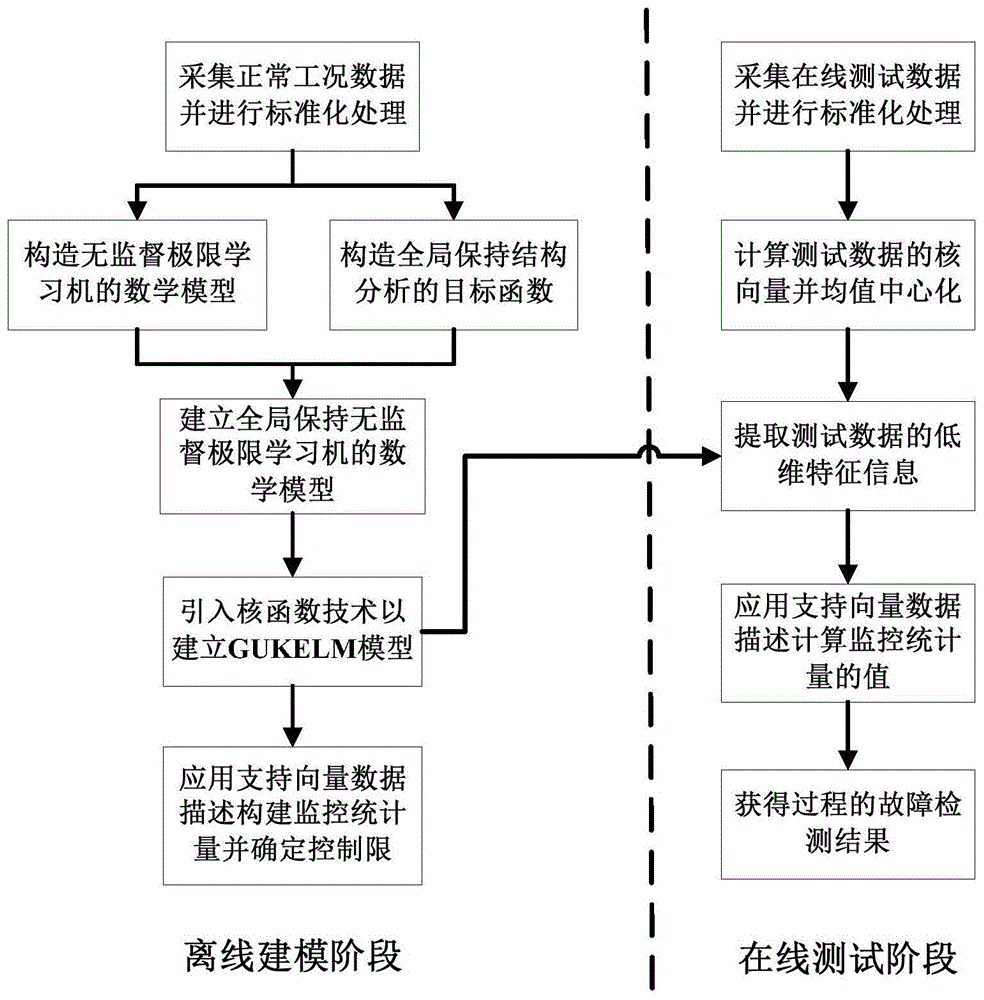
图1为本公开实施例的基于全局保持无监督核极限学习机的故障检测流程图。
图2为本公开实施例的全局保持无监督核极限学习机的方框图。
图3为本公开实施例中cstr系统的结构图。
图4(a)为本公开实施例对cstr系统故障f4的kpca监控t2统计量结果。
图4(b)为本公开实施例对cstr系统故障f4的kpca监控spe统计量结果。
图4(c)为本公开实施例对cstr系统故障f4的uelm监控d统计量结果。
图4(d)为本公开实施例对cstr系统故障f4的gukelm监控d统计量结果。
图5(a)为本公开实施例对cstr系统故障f6的kpca监控t2统计量结果。
图5(b)为本公开实施例对cstr系统故障f6的kpca监控spe统计量结果。
图5(c)为本公开实施例对cstr系统故障f6的uelm监控d统计量结果。
图5(d)为本公开实施例对cstr系统故障f6的gukelm监控d统计量结果。
图6(a)为本公开实施例对cstr系统故障f7的kpca监控t2统计量结果。
图6(b)为本公开实施例对cstr系统故障f7的kpca监控spe统计量结果。
图6(c)为本公开实施例对cstr系统故障f7的uelm监控d统计量结果。
图6(d)为本公开实施例对cstr系统故障f7的gukelm监控d统计量结果。
具体实施方式
下面结合附图与实施例对本公开作进一步说明。
应该指出,以下详细说明都是例示性的,旨在对本公开提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本公开所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本公开的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
本公开的一种基于全局保持无监督核极限学习机的故障检测方法及系统适用于非线性工业系统工作过程的故障检测,其中,非线性工业系统包括连续搅拌反应釜系统,污水处理过程、青霉素发酵过程、微极性流体润滑轴承-转子系统等。
下面以连续搅拌反应釜(cstr)系统为例,在cstr系统中,物料a进入反应器,发生一阶不可逆化学方应,生成物料b,放出热量,通过外面的夹套冷却剂对反应器降温,为保证过程正常运行,采用串级控制系统控制反应器的液位和温度,其结果图如图3所示。
根据过程机理,建立cstr系统的动态机理模型如下:
式中,a是反应器截面积,ca是反应器内物料a的浓度,caf是物料a在进料中的浓度,cp是反应物比热,cpc是冷却剂比热,e是活化能,h是反应器液位,k0是反应因子,qf进料流量,qc是冷却剂流量,r是气体常数,t是反应器内温度,tc是冷却剂出口温度,tcf是冷却剂入口温度,tf是反应器进料温度,u是换热系数,ac是总的换热面积,espe是反应热,ρ是反应物密度,是冷却剂密度。
根据动态机理模型,对cstr系统进行仿真。在仿真过程中,采集反应器进料流量、反应器进料温度、进料中物料a浓度、反应器内温度、反应器液位、反应器出料流量、反应器出料中物料a浓度、冷却剂入口温度、冷却剂出口温度和冷却剂流量10个测量变量。
在cstr的仿真过程中加入服从高斯分布的测量噪声,采集900个正常工况下的样本最为训练数据集。另外模拟了7类故障的发生,每一类故障数据分别采集900个样本点,在第201个采样时刻添加故障,这7类故障的类型见表1。
表1cstr系统故障类型
上述cstr系统的多变量工业过程故障检测方法,如图1所示,含有以下步骤:
离线建模阶段:
(一)收集cstr系统的正常操作数据xo作为训练数据集,计算训练数据集的均值mean(xo)和标准差std(xo),对训练数据集进行标准化处理获得归一化的数据x。
通过公式(1)对训练数据xo进行标准化处理,表达式如下:
x=(xo-mean(xo))/std(xo)(1)
(二)在提取低维特征时为了保持数据的局部结构信息,根据训练数据集x构造加权对称矩阵w,基于矩阵w计算对角矩阵d和拉普拉斯矩阵l=d-w,构建无监督极限学习机的数学模型。
基于训练数据集x构造够加权对称矩阵w,加权对称矩阵w中的元素构造如下:
其中,ok(xj)表示数据xj的k近邻区域,ok(xi)表示数据xi的k近邻区域,i,j=1,2,…,n。
基于加权对称矩阵w,构造对角矩阵d,其对角元素dii计算公式如下:
获得加权对称矩阵w和对角矩阵d后,继续构造拉普拉斯矩阵l:
l=d-w(4)
构建无监督极限学习机的数学模型如公式(5)所示:
其中,β表示输出加权矩阵,λ表示权衡系数,tr(·)表示求解矩阵的迹。f表示输出矩阵,fi是输出矩阵f的第i行,h(xi)表示随机特征映射矩阵的第i行。
(三)在提取低维特征时为了保持数据的全局结构信息构,造全局保持结构分析的目标函数,并将其融入到无监督极限学习机的数学模型中,推导出全局保持无监督极限学习机的数学模型,如图2所示。
对过程数据进行降维时为了保持数据的全局结构信息,构造全局保持结构分析的目标函数:
其中,fi表示第i个网络输出节点,均值
将fi=h(xi)β代入公式(6),并假定
其中矩阵h表示随机特征映射矩阵,构造如下:
其中,g(·)表示激活函数。
公式(5)中,无监督极限学习机的目标函数可进一步改写为:
jlocal(β)=min||β||2+λtr(βthtlhβ)=mintr(βt(il+λhtlh)β)(9)
其中,il表示l×l维的单位矩阵。
根据公式(7)和公式(9),建立全局保持无监督极限学习机的数学模型如公式(10)所示:
(四)将全局保持无监督极限学习机的最优化问题转化为广义特征值分解问题,应用核函数技术以避免确定隐含层节点数目的问题;基于求解的负荷矩阵
将公式(10)中全局保持无监督极限学习机的最优化问题转化为广义特征值分解问题:
其中,in表示n×n维的单位矩阵。
为了避免在对数据进行非线性映射时需要确定隐含层节点数目的问题,将核函数技术应用到全局保持无监督极限学习机中,定义n×n维的核矩阵:
其中,核函数选用高斯核ker(xi,xj)=exp(-||xi-xj||2/σ)。
为了保证在高维空间中
其中,ik表示n×n的矩阵,它的每一个元素都等于1/n。
基于核函数技术,公式(11)可重新表述为:
求解上式中的广义特征值分解问题,保留与前p最小特征值γ1≤γ2≤…≤γp相对应的特征向量α1,α2,…,αp组成负荷矩阵
基于负荷矩阵a,计算输出加权矩阵的最终解β*:
(五)根据矩阵β*从正常训练数据中提取保持局部和全局结构的低维特征信息,然后将支持向量数据描述算法应用与低维特征信息矩阵t上,构建监控统计量并确定其控制限dlimit。
基于矩阵β*从正常训练数据中提取低维特征信息矩阵t:
为了构建监控统计量,将支持向量数据描述算法应用于矩阵t=[t1,t2,…,tn]。
其中,b表示超球体的球心坐标向量,cs表示权衡系数,ξi表示松弛变量,r表示超球体的半径。
将公式(18)中的最优化问题转化为公式(19)中的对偶问题,并对其求解以获得球心坐标向量b。
其中核函数ker(ti,tj)=<φ(ti),φ(tj)>同样选用高斯核;βi和βj表示拉格朗日乘子。
对于矩阵t中的第i个向量ti,计算监控统计量d(i):
监控统计量的控制限dlimit定义为位于超球体边界上的任一支撑向量到超球体球心b的欧式距离。
在线监测阶段:
(一)在线采集cstr系统的测试数据xto,利用训练数据的均值mean(x)和标准差std(x)对其进行归一化。
对原始测试数据xto标准化的公式如下:
xt=(xto-mean(xo))/std(xo)(21)
(二)为了将测试数据非线性映射到高维特征空间,根据核函数计算测试数据的核向量kt,并在特征空间中对核向量kt进行均值中心化处理,获得测试核向量
计算测试数据的核向量kt,将测试数据xt非线性映射到高维特征空间:
kt=h(xt)ht(22)
其中,kt,i=k(xt,xi),i=1,2,…n。
进一步对测试核向量kt进行均值中心化处理:
其中,
(三)根据全局保持无监督核极限学习机从均值中心化的核向量
从均值中心化的测试核向量中提取低维特征信息:
根据支撑向量数据描述算法计算测试数据的监控统计量dt:
(四)依据测试数据的监控统计量dt是否超出其控制限dlimit,判断工业过程在运行中是否发生故障。
如果dt>dlimit,则表明工业过程在运行过程中已经发生故障;如果dt≤dlimit,则表明工业过程运行在正常状态。
在具体实施中,检测到过程中故障发生后,为了评价不同监控方法的故障检测效果,通过故障检测时刻(fdt)和故障检测率(fdr)两个性能指标进行不同方法的故障检测效果对比。
故障检测时刻(fdt)定义为第一个被认为是故障数据的样本所在的采样时刻,故障检测率(fdr)定义为被检测出是故障数据的样本数目与实际总的故障样本数目之比。
很显然,fdt的数值越小,fdr的数值越大,意味着过程监控方法的故障检测效果越好;fdt的数值越大,fdr的数值越小,表明过程监控方法的故障检测效果越差。
在本仿真实例中,将全局保持无监督核极限学习机(gukelm)、无监督极限学习机(uelm)和核主元分析(kpca)这三种方法对cstr系统的故障检测效果进行对比分析。本实施例的基于gukelm的方法选用高斯核作为核函数且设置核参数为δ=400,输出空间的维度设置为n0=10。为了公平起见,uelm的输出空间维度也设置为10,其隐含层的节点数取为l=1000,激活函数选用为sigmoid函数。对于gukelm和uelm这两种方法,均采用支持向量数据描述算法构造监控统计量。在kpca方法中,核函数同样选用高斯核且设置核参数为400,根据95%的累计贡献率确定所要保留的主元数目,根据95%的置信水平计算监控统计量的控制限。
综合对比上述三种方法,以故障f4、f6和f7为例说明cstr系统的故障检测效果。
故障f4为进料流量出现阶跃变化,kpca、uelm和gukelm的故障检测效果见图4(a)-图4(d),其中横坐标均为采用序列。其中,图4(a)和图4(b)是kpca的故障检测效果,核主元分析(kernelprincipalcomponentanalysiskpca)在降维、特征提取以及故障检测中的应用,主要功能有:(1)训练数据和测试数据的非线性主元提取(降维、特征提取);(2)spe和t2统计量及其控制限的计算;(3)故障检测。在图4(a)中纵坐标为t2统计量,在图4(b)中纵坐标为spe统计量。图4(c)和图4(d)的纵坐标均为监控统计量-d统计量。从图4(a)-图4(d)中可以看出这三种监控方法都在第201个时刻检测到过程故障发生,故障检测率均达到100%。但是在图4(c)中,uelm将第201个时刻之前的正常样本错误的检测为故障样本,故障误报率较高。因此gukelm对于故障f4具有最好的故障检测效果。其中,t2统计量反映了每个主成分在变化趋势和幅值上偏离模型的程度,是对模型内部化的一种度量,它可以用来对多个主元同时进行监测;spe统计量刻画了输入变量的测量值对主元模型的偏离程度,是对模型外部变化的一种度量。
故障f6为进料温度出现斜坡上升变化,kpca、uelm和gukelm的故障检测效果见图5(a)-图5(d),其中横坐标均为采用序列。其中,图5(a)和图5(b)是kpca的故障检测效果,在图5(a)中纵坐标为t2统计量,在图5(b)中纵坐标为spe统计量。图5(c)和图5(d)的纵坐标均为监控统计量-d统计量。从图5(a)和图5(b)可以看出,kpca的t2统计量在第349个采样点检测出故障,kpca的spe统计量在第266个采样点检测出故障。kpca的t2和spe统计量的故障检测率分别为75.31%和87.91%。在图5(c)中,uelm给出了更好的故障检测结果,其在第218个采样点就检测出故障,故障检测率为94.09%。但是在第201个时刻之前,uelm将一些正常样本误认为是故障样本,具有较高的故障误报率,仍需要进一步改进。在图5(d)中,ukelm取得了最好的故障检测效果,其在第204个采样点就给出故障报警且故障检测率达到97.55%。因此gukelm对于故障f6具有最好的故障检测效果。
故障f7为冷却水进入温度出现斜坡上升变化,kpca、uelm和gukelm的故障检测效果见图6(a)-图6(d)。其中横坐标均为采用序列。其中,图6(a)和图6(b)是kpca的故障检测效果,在图6(a)中纵坐标为t2统计量,在图6(b)中纵坐标为spe统计量。图6(c)和图6(d)的纵坐标均为监控统计量-d统计量。图6(a)和图6(b)显示kpca的t2统计量在第381个采样点检测出故障,故障检测率为72.37%;kpca的spe统计量在第340个采样点检测出故障,故障检测率为73.53%。图6(c)显示ukelm的d统计量在第289个采样点检测出故障,相应的故障检测率为83.14%。相比于kpca和uelm方法,gukelm对故障f7的反应更加敏感和迅速。在图6(d)中,gukelm的d统计量在第250个采样点给出了故障报警,故障检测率为90.66%。因此gukelm对于故障f7具有最好的故障检测效果。
表2和表3分别给出了kpca、uelm和gukelm这三种方法对于7种故障的故障检测时间和故障检测率。从表2和表3可以看出,对于阶跃故障f3和f4,这三种方法均能在第201个时刻检测到故障方法,故障检测率均为100%。但是对于斜坡故障f1、f2、f5、f6和f7,gukelm方法都具有最短的故障检测时间和最高的故障检测率。综合以上分析,本实施例的gukelm方法的故障检测效果明显优于kpca和uelm方法。
表2故障检测时刻(fdt)比较表
表3故障检测率(fdr)比较表
实施例二
本实施例提供一种基于全局保持无监督核极限学习机的故障检测系统,包括:
离线建模模块,其包括:
数学模型构建模块,其用于利用归一化的训练数据集,构建全局保持无监督极限学习机的数学模型;所述训练数据集中的训练数据均为非线性工作过程正常操作工况数据;
输出加权矩阵求解模块,其用于将全局保持无监督极限学习机的最优化问题转化为广义特征值分解问题,得到广义特征值分解问题数学公式表述,利用核函数更新广义特征值分解问题数学公式表述,计算全局保持无监督极限学习机输出加权矩阵的最终解;
监控统计量及控制限确定模块,其用于根据输出加权矩阵的最终解从归一化的训练数据集中提取保持局部和全局结构的低维特征信息矩阵,再利用支持向量数据描述算法构建出监控统计量并确定其控制限;
在线监控模块,其包括:
测试数据归一化处理模块,其用于对测试数据进行归一化处理;其中,测试数据为非线性工作过程工况数据;
测试核向量计算模块,其用于根据核函数计算测试数据的核向量,并在特征空间中对核向量进行均值中心化处理,获得测试核向量;
测试数据的监控统计量计算模块,其用于根据全局保持无监督核极限学习机从测试核向量中提取测试数据的低维特征信息矩阵,计算测试数据的监控统计量;
故障判断模块,其用于依据测试数据的监控统计量是否超出其控制限,判断非线性工业过程是否发生故障。
其中,在所述故障判断模块中,若测试数据的监控统计量超出其控制限,则判断非线性工业过程已经发生故障;否则,判断非线性工业过程正常运行。
实施例三
本实施例提供一种计算机可读存储介质。
本实施例的一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现图1所示的基于全局保持无监督核极限学习机的故障检测方法中的步骤。
实施例四
本实施例提供一种计算机设备。
本实施例的一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现图1所示的基于全局保持无监督核极限学习机的故障检测方法中的步骤。
本领域内的技术人员应明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本公开是参照根据本公开实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read-onlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。
以上所述仅为本公开的优选实施例而已,并不用于限制本公开,对于本领域的技术人员来说,本公开可以有各种更改和变化。凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!