一种场景快变条件下的多飞行器自主决策方法与流程
本发明属于飞行器技术领域,涉及一种冲突解脱方法,具体是指一种场景快变条件下的多飞行器自主决策方法。
背景技术:
随着航空科学技术的快速发展,在复杂恶劣、高风险的作业环境中,低空小型飞行器在空中监视、森林救援、侦察勘探和军事应用等方面获得了广泛的应用。由此,多飞行器自主决策中的路径规划和冲突解脱问题引起了国内外学者的广泛关注。
实际低空运行环境存在一个最主要的特性是场景复杂高动态,可能存在运动特性未知的动态威胁,并且许多实际任务中,智能体的目标一般不是静态的,而是动态变化的,而现有飞行器的调控主要依赖于预先规划或既定的动作集,难以适应未来的复杂性和动态性场景。
多飞行器自主决策是一个典型的多智能体协同问题,我们希望智能体具有向环境学习的能力,即自动获取知识、积累经验、不断更新和扩充知识,改善知识性能。所谓的学习能力,就是智能体通过试验、观察和推测来更新知识的能力。智能体只有通过不断的学习,才能完善自身的适应能力,依靠与环境不断的交互来获得知识。
技术实现要素:
针对上述问题,本发明提供一种场景快变条件下的多飞行器自主决策方法,充分考虑了场景的动态性,提高了多飞行器的学习能力。
所述的场景快变条件下的多飞行器自主决策方法,包括如下步骤:
步骤一、针对nu架飞行器和nt个目标构成的场景,每个飞行器分别搭载一个激光雷达传感器,在探测范围内定期发送雷达回波信号;
每架飞行器分别对应一个目标,目标初始值随机设定。nu和nt的取值相同。
探测范围为:每个飞行器视为质点,
步骤二、每个飞行器根据雷达回波信号返回的三维点云数据,识别探测范围内的静态障碍物或其他飞行器;
当探测到其他飞行器时,返回的三维点云数据为其他飞行器的三维坐标及速度方向,当探测到静态障碍时,返回的三维点云数据是静态障碍物的边界坐标,若无障碍物返回的三维点云数据为0。
步骤三、针对时隙t,第i架飞行器与其他飞行器的三维点云数据构建自主冲突解脱模型;
自主冲突解脱模型的目标为每个飞行器到达各自目标点的距离最短,目标函数如下:
s.t.r1,r2,r3
di表示第i架飞行器与该飞行器对应的目标点之间的距离。
三个约束条件分别如下:
(1)r1表示每个飞行器都要到达各自的目标位置的回报函数;计算公式为:
(2)r2表示每个飞行器与静态障碍物之间都不能发生碰撞的回报函数,计算公式为:
(3)r3表示任意飞行器之间不能发生碰撞的回报函数,计算公式为:
步骤四、基于多智能体强化学习框架对多飞行器自主冲突解脱模型进行求解,得到根据输入状态选择动作的奖励函数;
奖励函数包括以下:
(1)每个飞行器与各自目标的初始位置之间的最短路径设定的奖励函数ra;
首先,设定初始ra=0;
然后,第i架飞行器xi在时刻t的状态为
最后,累积计算nu架飞行器在时刻t,选择各自动作后的当前位置与各自的目标位置之间的距离之和,并更新奖励函数ra;
更新公式为:
因此,若累积的各飞行器距离之和越大,则表明联合策略越差;反之,则表明联合策略好。
(2)对飞行器和障碍物进行碰撞检测设定的奖励函数rb;
首先,设定初始rb=0;
然后,计算第i架飞行器xi,根据时刻t的动作
进而,判定距离
针对第i架飞行器xi,在时刻t将该飞行器xi与探测范围内所有静态障碍物的距离分别与最小安全距离no判断,得到惩罚值之和
累积计算nu架飞行器在时刻t各自对应的惩罚值之和,并更新奖励函数rb:
因此,若飞行器距离障碍物越近,则整个多飞行器自主决策获得的联合收益越小。
(3)对飞行器和飞行器间进行碰撞检测设定的奖励函数rc;
首先,设定初始rc=0;
然后,计算第i架飞行器xi,根据时刻t的动作
此处设定对其他飞行器的观测存在噪声且有一个时间步的延迟。
进而,判定距离
针对第i架飞行器xi,在时刻t将该飞行器xi与所有其他飞行器的距离分别与碰撞距离nc和接近风险距离nm判断,得到惩罚值之和
累积计算nu架飞行器在时刻t各自对应的惩罚值之和,并更新惩罚函数rc:
因此,若飞行器距离其他飞行器越近,则整个多飞行器自主决策获得的联合收益越小。
步骤五、神经网络学习模块基于奖励函数进行中心化训练和非中心化执行,通过收敛的神经网络计算出基于某状态的所有可采取的动作值,并根据组合优化求解多智能体行为动作。
本发明的优点在于:
(1)本发明一种场景快变条件下的多飞行器自主决策方法,针对低空空域复杂高动态,多元要素的运行特性未知,空域环境与交通对象的耦合关系更加复杂,加之任务复杂快变的场景作为研究背景,有很重要的现实意义。
(2)本发明一种场景快变条件下的多飞行器自主决策方法,除了充分考虑场景的动态性,还考虑了非完全信息和非理想通信,提出了指导飞行器自主决策方法,相比于启发式方法和传统优化方法,当场景信息改变时可利用迁移学习技术进行继承训练,不需要重新设计和训练算法,迁移性较好。
附图说明
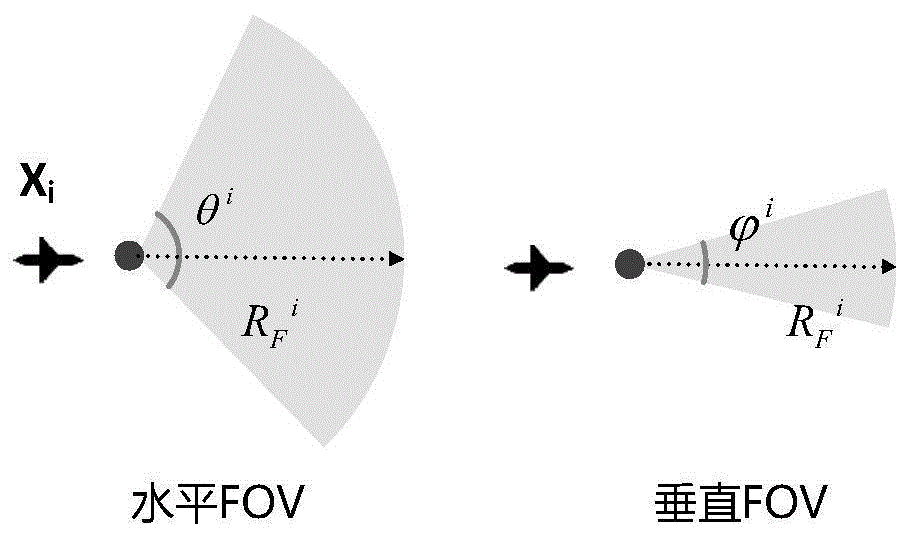
图1为本发明飞行器进行冲突探测时激光雷达的探测范围示意图。
图2为本发明多智能体强化学习模型示意图。
图3为本发明的飞行器安全距离示意图。
图4为本发明一种场景快变条件下的多飞行器自主决策方法流程图。
具体实施方式
为了便于本领域普通技术人员理解和实施本发明,下面结合附图对本发明作进一步的详细和深入描述。
本发明提供一种场景快变条件下的多飞行器自主决策方法,针对的复杂高动态场景具有以下特征:(1)场景中静态、动态障碍并存,目标在飞行过程中可能发生动态变化;(2)单个无人机感知范围有限无法获得全局信息;(3)无人机之间可以进行通信来共享局部空域信息;(4)无人机之间的通信存在干扰和随机丢失;将多飞行器自主决策分解为两个子问题:(1)路径规划;(2)冲突解脱。对于路径规划和冲突解脱,作为优化问题已经被证明是一个np-hard问题,需要使用启发式算法进行求解。所以,一种求解多飞行器自主决策的方法可以通过分治完成:通过先求解路径规划和冲突解脱两个子问题,再组合两个子问题的解作为最终解。
如图4所示,所述飞行器自主决策方法包括如下步骤:
步骤一、针对nu架飞行器和nt个目标构成的场景,每个飞行器分别搭载一个激光雷达传感器,在探测范围内定期进行冲突探测,并发送雷达回波信号;
飞行冲突探测采用基于雷达系统的非合作威胁冲突探测,激光雷达在自主导航技术中发挥中重要作用。激光雷达的主要性能参数有激光的波长、探测距离、视场角(fov),视场角分为水平视场角和垂直视场角。最常用的两种激光雷达波长为905nm和1550nm。1550nm波长雷达传感器可以以更高的功率运行,探测距离比905nm波长的远,但是重量更大。
本发明假设有nu架飞行器和nt个目标,每架飞行器分别对应一个目标,目标初始值随机设定;nu和nt的取值相同。针对第i架飞行器xi,在时刻t的状态为
如图1所示,雷达的探测范围为:每个飞行器视为质点,
步骤二、每个飞行器根据雷达回波信号返回的三维点云数据,识别探测范围内的静态障碍物或其他飞行器;
将飞行器视为质点,飞行器在探测范围内定期发送雷达回波信号,当探测到其他飞行器时,返回的三维点云数据为其他飞行器的三维坐标及速度方向,当探测到静态障碍时,返回的三维点云数据是静态障碍物的边界坐标,若无障碍物返回的三维点云数据为0。
步骤三、针对时隙t,第i架飞行器与其他飞行器的三维点云数据构建自主决策建模模型;
本发明从观察值、动作以及回报函数三方面描述自主决策问题的设计过程。
1)观察值st:在每个时刻t,t=1,2,...,t,t表示飞行器到达目标的最大时刻;因为强化学习中的代理会根据收集到的当前状态与飞行器奖励值制定一个控制决策,所以要先构建观察值st,第i架飞行器xi在时刻t的状态观察值表示为
其中,
2)动作at:从drl机制的角度来讲,若是将飞行器的移动表征为动作,那么该动作能够引起环境的变化,飞行器的移动距离能够决定飞行器的能耗大小。因此根据飞行器移动模型的飞行方向加速度表示强化学习的动作
ρj(t)∈[0,ρmax]表示第j架飞行器在时刻t作为起始时刻收到的俯仰方向速度,ρmax表示俯仰方向最大速度。
集合at中元素的个数为2×|nu|,从代理收到了动作at之后,第j架飞行器将决定在当前位置悬停或者移动到一个新的位置,实现了飞行器连续移动的控制。
3)回报函数rt:自主决策问题的目标是每架飞行器到达各自对应目标点的距离最短,因此会存在三个不同的约束(飞行器要完成目标,飞行器与障碍或飞行器之间不能发生碰撞),为了设计回报函数,本发明采用分开讨论自主避险问题的目标与约束。
首先,多飞行器自主决策的优化目标是到达目标后各飞行器的路径最短,则目标函数表示为:
除此,又分别设计了三个约束条件,需要满足以下约束:
(1)所有的目标都要完成到:
r1表示每个飞行器都要到达各自的目标位置的回报函数;计算公式为:
(2)飞行器与障碍之间不能发生碰撞:
r2表示每个飞行器与静态障碍物之间都不能发生碰撞的回报函数,计算公式为:
(3)飞行器之间不能发生碰撞:
r3表示任意飞行器之间不能发生碰撞的回报函数,计算公式为:
所以,多飞行器自主决策问题现在转化为一个组合优化问题,即自主冲突解脱模型的目标为每个飞行器到达各自目标点的距离最短,目标函数如下:
s.t.r1,r2,r3
步骤四、基于多智能体强化学习(maddpg)框架对多飞行器自主决策模型进行求解,得到根据输入状态选择动作的奖励函数;
具体过程如下:
1)建立多智能体神经网络
每个智能体(agent)的状态空间和动作空间被抽象成与飞行器完全一致。每个智能体的策略由参数θ决定,
ai为第i架飞行器的动作;οi表示第i架飞行器的观测,包含了智能体与障碍、目标和其他智能体之间的距离信息;θi表示第i架飞行器的神经网络参数。
由maddpg相关理论,确定性策略
l(θi)表示评论家网络损失函数;r表示奖励,
ri表示第i架飞行器的奖励函数;γ∈(0,1)表示衰减因子;
其中,j表示动作网络目标函数;s代表了随机抽取的一小批样本。
整个设计的模型如图2所示。
2)奖励函数设计
为了满足约束条件,需要对maddpg进行奖励函数的设计;如图3所示,奖励函数包括以下:
(1)累积每个飞行器与各自目标的初始位置之间的最短路径设定的奖励函数ra;
首先,设定初始ra=0;
然后,第i架飞行器xi在时刻t的状态为
最后,累积计算nu架飞行器在时刻t,选择各自动作后的当前位置与各自的目标位置之间的距离之和,并更新奖励函数ra;
更新公式为:
因此,若累积的各飞行器距离之和越大,则表明联合策略越差;反之,则表明联合策略好。
(2)对飞行器和障碍物进行碰撞检测设定的奖励函数rb;
为了保证飞行器和障碍物不发生碰撞,需要进行碰撞检测,首先,设定初始rb=0;
然后,计算第i架飞行器xi,根据时刻t的动作
进而,判定距离
针对第i架飞行器xi,在时刻t将该飞行器xi与探测范围内所有静态障碍物的距离分别与最小安全距离no判断,得到惩罚值之和
累积计算nu架飞行器在时刻t各自对应的惩罚值之和,并更新奖励函数rb:
因此,若飞行器距离障碍物越近,则整个多飞行器自主决策获得的联合收益越小。
(3)对飞行器和飞行器间进行碰撞检测设定的奖励函数rc;
为了保证飞行器和飞行器之间不发生碰撞,需要进行碰撞检测,首先,设定初始rc=0;
然后,计算第i架飞行器xi,根据时刻t的动作
此处设定对其他飞行器的观测存在噪声且有一个时间步的延迟。
进而,判定距离
针对第i架飞行器xi,在时刻t将该飞行器xi与所有其他飞行器的距离分别与碰撞距离nc和接近风险距离nm判断,得到惩罚值之和
累积计算nu架飞行器在时刻t各自对应的惩罚值之和,并更新惩罚函数rc:
因此,若飞行器距离其他飞行器越近,则整个多飞行器自主决策获得的联合收益越小。
步骤五、神经网络学习模块基于奖励函数进行中心化训练和非中心化执行,通过收敛的神经网络计算出基于某状态的所有可采取的动作值,并根据组合优化求解多智能体行为动作。
每一个智能体都包含动作网络(actornetwork)和评论家网络(criticnetwork)。每个agent的critic部分能够获取其余所有agent的动作信息,进行中心化训练和非中心化执行,即在训练的时候,引入可以观察全局的critic来指导actor训练,而测试的时候只使用有局部观测的actor采取行动。
- 还没有人留言评论。精彩留言会获得点赞!