混合自动车队的直接和间接控制的制作方法
1.本发明总体上涉及交通控制,并且更具体地涉及控制包括受控车辆和不受控车辆的车队。
背景技术:
2.交通拥堵是全球许多地区的一个重大问题,其代价包括时间损失、环境威胁和浪费的燃料消耗。在美国,交通拥堵的成本可以以每年人均数百美元来衡量。为此,需要减少交通拥堵和/或改善任何其它交通目标。
3.解决这些问题的一个可能贡献是允许车辆在所谓的“车队”中更紧密地行驶。术语“车队”通常表示它们之间的距离很短的许多车辆,其作为一个单位被驱动。短距离导致更多的车辆可以使用道路,并且由于减少了阻力,单个车辆的能量消耗也减少了。车队中的车辆通过车辆速度的自动控制和其方向的自动控制中的至少之一被驱动。
4.如今,许多车辆还配备了巡航控制系统,以使驾驶员更容易驾驶车辆。在这种情况下,驾驶员可以通过例如仪表板中的调节器来设置期望速度,并且车辆中的巡航控制系统随后影响控制系统,从而使其在适当时加速和制动车辆,以保持期望速度。如果车辆配备了自动换档系统,则车辆正在行驶的档位被改变,使得车辆可以保持期望的速度。
5.例如,网联式自适应巡航控制(connected adaptive cruise control,cacc)是一种自主车道保持形式,其中车辆将彼此的位置传送给中央系统,以计算确保稳定性、鲁棒性和最优性的速度控件。配备有cacc的车辆可以与配备有cacc的其它车辆形成车队。但是,交通可能包括具有和不具有cacc的车辆。即使所有车辆都配备有cacc,一些车辆操作者也可能会选择不使用cacc并手动驾驶。在控制车队时的一个重要问题是当手动操作车辆加入车队并扰乱车队时导致的效率低下。由于难以控制手动操作车辆和/或对手动操作车辆进行建模,因此车队几乎无法将车辆从车队中移除。
6.例如,一种方法将一个车队分成几个车队以确保车队控制的同质性,参见例如us.6356820。但是,这种分解重复了控制方法并增加了不同车队的车辆之间的距离,这反过来会增加交通拥堵。另一种方法控制车队的车辆以确保每个车队的同质性,例如参见us.2012/0123658。然而,这些方法难以应用于手动操作车辆。
技术实现要素:
7.一些实施方式的目的是提供一种用于控制混合车队的系统和方法。如本文所使用的,这种混合车队包括受控车辆和不受控车辆。受控车辆的示例包括愿意形成车队的自动驾驶车辆和半自动驾驶车辆。例如,受控车辆可以使用网联式自适应巡航控制(cacc),该网联式自适应巡航控制(cacc)被配置为确定对受控车辆的致动器的运动命令以形成和/或维持车队。不受控车辆的示例包括不愿意形成车队的自动驾驶车辆和半自动驾驶车辆以及手动操作车辆(即,由人类驾驶员操作的车辆)。
8.一些实施方式的另一个目的是提供对形成车队的不受控车辆的间接控制。一些实
施方式基于这样的认识,即,形成车队的受控车辆的运动可以间接影响车队中的不受控车辆的运动。例如,受控车辆的减速会迫使尾随的不受控车辆也减速。类似地,增加受控车辆的速度可以鼓励尾随的不受控车辆的驾驶员在开放空间中加速。以这种方式,受控车辆的直接控制可用于鼓励对不受控车辆的自我施加控制,从而允许由包括受控车辆和不受控车辆的混合车辆形成车队。这种对不受控车辆的自我施加控制的鼓励在本文中被称为间接控制。
9.一方面,这种间接控制是不可靠的。实际上,受控车辆的加速可能不会迫使不受控车辆的加速。恰恰相反,这样的加速可能会不期望地迫使其它驾驶员感觉到危险并使他们的车辆减速。然而,一些实施方式基于由实验证据支持的认识,即,如果满足以下提供的至少两个条件,则受控车辆的直接控制可以高效地用于混合车队中的间接控制。
10.这两个条件中的第一个条件涉及执行直接控制的手段。一些实施方式基于这样的认识,即,为了高效地控制混合车队,混合车队中的受控车辆的直接控制手段应该与不受控车辆的自我施加间接控制的手段相当。一些实施方式基于以下认识,即,自我施加间接控制的手段是车辆之间的距离。事实上,为了保持安全,驾驶员会根据当前交通速度保持他们认为安全的距离。
11.为此,为了统一直接控制和间接控制,一些实施方式通过对控制车辆的运动施加约束来提供对受控车辆的直接控制,直接控制包括车队中的两个车辆之间的最大车头时距(headway)和车队中的每个车辆的最大速度之一或其组合。例如,这种直接控制可以与对车辆的致动器的直接命令进行对比,这在原理上与自我施加间接控制不同。此外,对车辆的车头时距和/或速度的约束允许受控车辆使用它们的传统系统进行运动控制。例如,在一些实施方式中,受控车辆是自动驾驶车辆,其被配置为确定对受约束的自动驾驶车辆的致动器的运动命令。
12.两个条件中的第二个条件涉及执行直接控制的手段的计算。一些实施方式基于这样的认识,即,为了高效的间接控制,需要使用对混合车队中的所有车辆可能是公共的或至少相关的性能指标的优化来确定对车队中的车辆的车头时距和/或速度的约束。此外,应该在所有混合车辆都愿意并且能够以受控方式参与形成车队的假设下确定这样的性能指标。
13.然而,这种用于形成车队的混合自动车辆的直接和间接控制器的设计具有挑战性。设计此类控制器有两种方法,即,基于学习的控制器或学习器、以及基于求解的控制器或求解器。学习器和求解器都将输入映射到输出。然而,学习器从数据或经验中获取映射,而求解器从模型中获取针对每个给定输入的映射。然而,在这种情况下,两种方法都不是最优的,因为他律的混合自动车辆的行为模型是未知的,而学习器可能由于不受控车辆的零星行为而无法收敛到稳定控制。
14.一些实施方式基于以下认识:强化学习(诸如,深度强化学习(drl))可以根据一些实施方式的原理进行修改,以直接和间接控制混合自动车辆的车队。具体而言,一些实施方式不是产生改变环境的动作,而是训练参数化函数(诸如drl控制器),以产生强制车队形成的目标车头时距作为奖励。通过这种方式,学习器可以适应混合自动车辆的未知动力学。
15.例如,一些实施方式使用基于车头时距的模型,该基于车头时距的模型被配置为将目标车头时距映射到混合自动驾驶车辆的目标速度,例如最终映射到车辆的动作。基于车头时距的模型允许使用车头时距作为控制参数,并且将控制参数与可用于形成车队的车
辆的动作相关联。换句话说,基于车头时距的模型允许学习非自动并且更一般地不受控车辆的未知行为。示例性的基于车头时距的车辆行为模型是最优速度模型(ovm)。ovm将车辆的车头时距与安全行驶速度相关联。存在其它类似的模型并且可以由不同的实施方式类似地使用。
16.因此,一个实施方式公开了一种用于直接和间接控制混合自动驾驶车辆的系统,该系统包括:接收器,其被配置为接收沿同一方向行驶的一组混合自动驾驶车辆的交通状态,其中,该组混合自动驾驶车辆包括愿意参加车队形成的受控车辆和至少一个不受控车辆,并且其中,交通状态指示该组中的每个车辆的状态;存储器,其被配置为存储参数化函数,该参数化函数被训练为将交通状态转换为混合自动驾驶车辆的目标车头时距;以及存储基于车头时距的模型,该基于车头时距的模型被配置为将目标车头时距映射到混合自动驾驶车辆的目标速度;处理器,其被配置为将交通状态提交到参数化函数以产生目标车头时距;将目标车头时距提交给基于车头时距的模型以产生目标速度;以及基于目标车头时距和目标速度之一或组合确定对受控车辆的控制命令;以及发送器,其被配置为向该组混合自动驾驶车辆中的受控车辆发送控制命令。
17.另一个实施方式公开了一种用于直接和间接控制混合自动驾驶车辆的方法,其中,该方法使用与实现该方法的存储指令联接的处理器,其中,指令在由处理器执行时执行该方法的步骤,所述步骤包括:接收沿同一方向行驶的一组混合自动驾驶车辆的交通状态,其中,该组混合自动驾驶车辆包括愿意参加车队形成的受控车辆和至少一个不受控车辆,并且其中,交通状态指示该组中的每个车辆的状态;将交通状态提交给参数化函数以产生目标车头时距,该参数化函数被训练为将交通状态转换为混合自动驾驶车辆的目标车头时距;将目标车头时距提交给基于车头时距的模型以产生目标速度,该基于车头时距的模型被配置为将目标车头时距映射到混合自动驾驶车辆的目标速度;基于目标车头时距和目标速度之一或组合确定对受控车辆的控制命令;以及向该组混合自动驾驶车辆中的受控车辆发送控制命令。
18.又一实施方式公开了一种非暂时性计算机可读存储介质,其上具体实现可由处理器执行以用于执行方法的程序。该方法包括:接收沿同一方向行驶的一组混合自动驾驶车辆的交通状态,其中,该组混合自动驾驶车辆包括愿意参与车队形成的受控车辆和至少一个不受控车辆,并且其中,交通状态指示该组中的每个车辆的状态;将交通状态提交给参数化函数以产生目标车头时距,该参数化函数被训练为将交通状态转换为混合自动驾驶车辆的目标车头时距;将目标车头时距提交给基于车头时距的模型以产生目标速度,该基于车头时距的模型被配置为将目标车头时距映射到混合自动驾驶车辆的目标速度;基于目标车头时距和目标速度之一或组合确定对受控车辆的控制命令;以及向该组混合自动驾驶车辆中的受控车辆发送控制命令。
附图说明
19.[图1a]
[0020]
图1a示出了根据一些实施方式的形成车队的混合自动驾驶车辆的控制的示意图。
[0021]
[图1b]
[0022]
图1b示出了根据一些实施方式的用基于车头时距的模型增强的基于学习的控制
器的一般工作流程。
[0023]
[图2]
[0024]
图2示出了提供根据一些实施方式的直接和间接控制车队形成的总体概览的示意图。
[0025]
[图3a]
[0026]
图3a示出了根据一些实施方式的训练增强的强化学习控制器的示意图。
[0027]
[图3b]
[0028]
图3b示出了根据一个实施方式的图3a的学习的输入和输出。
[0029]
[图4]
[0030]
图4示出了根据一些实施方式的比较无模型和增强的强化学习的收敛性的图。
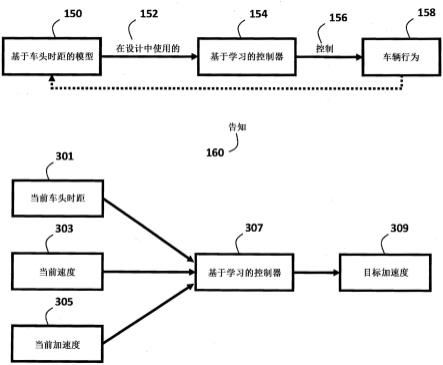
[0031]
[图5]
[0032]
图5示出了根据一些实施方式的用于直接和间接控制混合自动驾驶车辆的系统的框图。
[0033]
[图6a]
[0034]
图6a示出了根据一些实施方式的被直接或间接控制的车辆的示意图。
[0035]
[图6b]
[0036]
图6b示出了接收根据一些实施方式确定的受控命令的控制器与车辆的其它控制器之间的交互的示意图。
具体实施方式
[0037]
系统概览
[0038]
本公开涉及一组混合自动驾驶车辆,其旨在形成车队,该车队是在单车道上一起行驶的一组车辆。该组车辆的自动驾驶特征是混合的,因为一些车辆自主运行并愿意形成车队,而一些车辆不愿意形成车队和/或由人类操作者操作。例如,一个实施方式涉及由共享控制器控制的自动驾驶车辆的子组,以实现车队作为一个整体的更好操作。
[0039]
图1a示出了根据一些实施方式的形成车队的混合自动驾驶车辆的控制的示意图。根据一些实施方式,一组混合自动驾驶车辆包括愿意参加车队形成的受控车辆和至少一个不受控车辆。控制器102通过向控制车辆发送控制命令直接控制受控自动驾驶车辆,例如车辆103和104。控制器102还间接控制不受控车辆,诸如不愿参加车队的自动驾驶车辆105和人类操作车辆106。具体地,控制器102基于混合自动驾驶车辆的交通状态控制受控车辆,使得受控车辆的直接控制还提供对不受控车辆的间接控制。
[0040]
为了控制不同类型的自动驾驶车辆,一些实施方式使用在所有车辆之间共享的控制参数并基于该参数直接控制受控车辆,同时跟踪该参数用于其它车辆。为此,一些实施方式的实现是,车辆(无论是自动驾驶的还是人类操作的)最终根据期望速度和车头时距(即,到车辆前面的距离)来控制它们在单个车道中在长道路段上的行为。更具体地说,车队在所有车辆之间共享期望速度,而车头时距可以基于车辆类型、车载控制器和自主驾驶特性而变化。
[0041]
例如,一些实施方式基于由实验证据支持的实现,即,如果满足以下提供的至少两个条件,则对受控车辆的直接控制可以高效地用于混合车队中的间接控制。这两个条件中
的第一个条件与执行直接控制的手段有关。一些实施方式基于这样的认识,即,为了高效地控制混合车队,混合车队中的受控车辆的直接控制手段应该与不受控车辆的自我施加间接控制的手段相当。一些实施方式基于对自我施加间接控制手段是车辆之间的距离的认识。事实上,为了保持安全,驾驶员会根据当前的交通速度保持他们认为安全的距离。
[0042]
两个条件中的第二个条件与执行直接控制的手段的计算有关。一些实施方式基于这样的认识,即,为了高效的间接控制,需要使用对混合车队中的所有车辆可能是公共的或至少相关的性能指标的优化来确定车队中的车辆的目标车头时距。此外,应该在所有混合车辆都愿意并且能够以受控方式参与形成车队的假设下确定这样的性能指标。
[0043]
然而,用于形成车队的混合自动车辆的这种直接和间接控制器的设计具有挑战性。设计此类控制器有两种方法,即,基于学习的控制器或学习器、和基于求解的控制器或求解器。学习器和求解器都将输入映射到输出。然而,学习器从数据或经验中获取映射,而求解器从模型中获取每个给定输入的映射。然而,在这种情况下,两种方法都不是最优的,因为他律混合自动车辆的行为模型是未知的,而学习器可能由于不受控车辆的零星行为而无法收敛到稳定控制。
[0044]
例如,基于学习的控制可以来自两类学习器:深度学习器和深度强化学习器。在深度学习(dl)和深度强化学习(drl)中,训练会导致具有固定结构(由深度神经网络给出)的参数化函数和许多可调整参数。dl和drl之间的区别在于在训练期间学习函数的方式。深度学习是一种监督方法,通过使依赖于训练集中的输入和目标输出的误差函数最小化来学习参数。另一方面,深度强化学习是一种从经验中学习的非监督方法,其中,误差函数取决于状态及其继任者的值。在dl和drl中,可以通过经由随机梯度下降来最小化误差函数而执行训练,其中,通过在梯度方向上采取多个步骤来逐步递增地修改参数向量。类似的优化算法用于基于策略的drl,其中,参数化的函数表示策略。
[0045]
一些实施方式基于这样的认识,即,强化学习(诸如,drl)可以根据一些实施方式的原理进行修改,以直接和间接控制混合自动车辆的车队。具体而言,代替产生改变环境的动作,一些实施方式训练参数化函数(诸如,drl控制器)以产生执行车队形成的目标车头时距作为奖励。通过这种方式,学习器可以适用于混合自动车辆的未知动力学。
[0046]
例如,一些实施方式使用基于车头时距的模型,该基于车头时距的模型被配置为将目标车头时距映射到混合自动驾驶车辆的目标速度,并且例如最终映射到车辆的动作。基于车头时距的模型允许使用车头时距作为控制参数,并将控制参数与可用于形成车队的车辆的动作相关联。换句话说,基于车头时距的模型允许学习非自动并且更一般地不受控车辆的未知行为。示例性的基于车头时距的车辆行为模型是最优速度模型(ovm)。ovm将车辆的车头时距与安全行驶速度相关联。存在其它类似的模型并且可以由不同的实施方式类似地使用。例如,一些实施方式使用具有不同最佳速度函数(ovf)、全速差模型(fvdm)、智能驱动器模型(idm)、其变体等的ovm的变体。
[0047]
例如,在一个实施方式中,所使用的特定的基于学习的控制方案是增强深度强化学习(drl)。drl解决了在线优化问题,以同时学习系统的行为并学习控制同一系统。通常,drl可以是无模型的,也可以通过使用模型来增强。在没有模型的情况下,drl控制器的行为可能会变得不稳定,因为由于需要对更大的参数集进行优化,因此存在更多局部最优状态,从而优化可能会遇到收敛困难。事实上,我们自己的比较无模型drl和增强drl的实验表明,
虽然无模型drl通常无法收敛到稳定控制,但是基于模型的版本在这方面几乎没有困难。
[0048]
图1b示出了根据一些实施方式的用基于车头时距的模型增强的基于学习的控制器的一般工作流程。基于车头时距的模型150被用于将车辆的行为表示为在基于学习的控制器154的设计中的一个必要部分,该基于学习的控制器被训练成控制156车队中的车辆158的行为。模型150被告知160作为实际车辆行为158的设计选择,使得网联的车辆被直接控制并且未网联的车辆被间接控制。
[0049]
一般来说,车队中的车辆i的车头时距根据微分方程演化:
[0050][0051]
其中,hi是车辆的车头时距,vi是它的速度,v
i-1
是前车的速度。速度根据以下变化:
[0052][0053]
其中,ui是车辆加速度。加速度与施加在车辆上的力成正比,该力通过车轮与地面的接触而传递到车身。力本身被确定为某些高级控制器的输出,在非自动驾驶车辆的情况下可能是人类操作者,或者在自主驾驶车辆的情况下可能是速度控制器。为了建模的目的,一些实施方式表示加速度是两个参数的加权和,其权重因车辆而异,
[0054][0055]
第一个参数是实际速度和期望速度之间的差值。第二个参数(v
i-1-vi)是车头时距的变化率。期望速度使用ovf建模,其输入是车头时距:
[0056][0057]
参数v
max
、hs和hg在各个车辆之间不同。这些符号指的是最大优选速度v
max
(即,车辆在没有障碍物的情况下行驶的速度)、停车车头时距hs(即,车辆将变为完全停止、以及继续前进或全速的车头时距)、车头时距hg(即,车辆将以最大速度v
max
行驶的车头时距)。
[0058]
控制系统包括监测不受控车辆的车头时距h、速度v和加速度u的通信系统。在一些实施方式中,控制器可以包括通信系统,其中,不受控车辆将这些参数传送到中央系统;在其它实施方式中,受控车辆测量这些参数并将它们传送到中央系统。一般来说,存在一个范围,在这个范围内,所有车辆都应该报告它们的参数或测量它们的参数。出于这个原因,在一些实施方式中,混合自动车辆包括在车队中的受控车辆的侧翼预定范围内的所有不受控车辆。例如,在一个实施方式中,所有车辆参数的范围d至少约为以最大允许速度行驶的平均受控车辆的全速车头时距hg的两倍,即,d≥2hg。
[0059]
图2示出了提供根据一些实施方式的车队形成的直接和间接控制的总体概览的示意图。受控车辆连接到控制器并将它们的状态203传送给中央控制器201。控制器201收集的交通状态可以包括混合自动车辆的当前车头时距、当前速度和当前加速度。在一些实现中,混合自动车辆包括距车队中的受控车辆的侧翼预定范围207内的所有不受控车辆。除了受控车辆之外,一些不受控车辆也连接205到控制器201以提交它们的状态。
[0060]
对车队中车辆的控制通常称为协同自适应巡航控制(cacc)。cacc可以被设计用于一组车辆,所有这些车辆都是受控的。由于普通控制方法不考虑车队中某些车辆可能不合
作的情况,因此一些实施方式开发了新方法,但仍然旨在实现自动驾驶车辆的普通车队形成的性能。cacc有两个目标:设备稳定性(plant stability)和串稳定性(string stability)。如果所有车辆接近相同、恒定的速度,则车队是设备稳定的;如果整个车队的速度扰动减弱,则车队是串稳定的。
[0061]
一些实施方式将针对受控车辆设计的cacc的原理扩展到混合自动车辆。cacc的这两个目标告知一些实施方式的基于增强学习的控制器。具体来说,基于学习的方法使用基于这两个目标设计的成本函数。在一些实施方式中,成本函数包括两个分量的总和:
[0062]ci
=c
i,s
+a
pci,p
[0063]
其中ci是车辆观察到的每个个体产生的成本,c
i,s
是与串稳定性相关的成本函数的分量,c
i,p
是与设备稳定性相关的成本函数的分量;a
p
是设计参数,其将串加权到设备稳定性。分量本身由下式给出:
[0064]ci,s
=(h
i-h
*
)2+av(v
i-v
*
)2[0065]
和
[0066][0067]
其中,h
*
和v
*
是车队的期望车头时距和速度,av是将车头时距加权到速度跟踪的设计参数。
[0068]
在一些实施方式中,成本函数被进一步修改,因为稳定性不是控制车队的唯一考虑因素。特别是,一个重要的考虑因素是车辆不相互碰撞。出于这个原因,在一些实施方式中,我们修改成本函数以包括对成本的惩罚项:
[0069][0070]
惩罚项对接近停车车头时距的车头时距进行处罚,因为低于该车头时距,碰撞风险变高;ac是设计参数,其用于对车队控制的约束满足度进行加权。
[0071]
通常,强化学习算法试图最大化一些价值函数。这里,价值函数v是所有观察到的车辆的成本函数和时间t的规划范围之和的负值:
[0072][0073]
其中,a是观察到的车辆的集合。
[0074]
通常,控制算法的输出是控制本身,在这种情况下是加速度ui。然而,如实验所示,在包括非自动驾驶车辆的复杂系统中,很难直接学习合适的加速度。为此,一些实施方式改为根据以下来设置控制输出:
[0075][0076]
参数和是将跟踪最佳速度加权到跟踪前车速度的设计参数。
[0077]
在一些实施方式中,由控制器确定的目标车头时距是前进车头时距如上所述,最佳速度将车头时距hi、停车车头时距和前进车头时距与速度相关联。在优选实施方式中,停车车头时距跨所有受控车辆都是固定的。这样做是出于安全原因,因为否则有可能将停车车头时距设置为小的不安全的值或对交通产生不可预见的影响的大值;后者主
要是为了保护在训练中对车队的控制。
[0078]
图3a示出了根据一些实施方式训练增强的强化学习控制器的示意图。在诸如增强的drl之类的增强的强化学习(rl)中,增强的rl控制器350以离散时间步长与其环境310交互。在每个时间t,rl控制器接收对环境310中的交通状态330的观察320和奖励340。最终,增强的rl控制器350被用于从可用动作集中选择动作360,该动作随后作为控制命令被发送到环境,以改变环境中的交通状态。选择动作以收集尽可能多的奖励,并确定奖励以鼓励车队形成。
[0079]
然而,与无模型rl相比,增强的rl控制器不被训练成输出动作,而是被训练成根据对形成车队的混合自动车辆直接和间接控制原理输出目标车头时距。因此,由增强的rl产生的目标车头时距被进一步提交给基于车头时距的模型370,以产生指定用于控制机器的动作的控制命令。为了进一步鼓励混合自动车队形成,为所有混合自动车辆确定状态330以及奖励340。以这种方式,增强的rl控制器被训练成将混合自动驾驶车辆组的交通状态转换为改善组中的混合自动驾驶车辆的动作的目标车头时距,而动作由目标车头时距根据基于车头时距的模型来定义。实际上,增强的rl控制器允许在车队形成时控制混合自动驾驶车辆。
[0080]
不同的实施方式使用不同的方法来训练形成rl控制器的参数化函数。例如,在一些实施方式中,参数化函数使用深度确定性策略梯度方法、优势-演员评论家(advantage-actor critic method)方法、近端策略优化方法、深度q网络方法或蒙特卡洛策略梯度方法之一进行训练。
[0081]
图3b示出了根据一个实施方式的对于图3a的学习的输入和输出。通过奖励函数对学习算法307的输入包括所有观察到的车辆(即,这些参数被传送到控制器的所有车辆)的当前车头时距h
i 301、当前速度v
i 303和当前加速度u
i 305。输出是网联的自动驾驶车辆的目标加速度309。
[0082]
在一些实施方式中,输入被直接测量和报告。通常,测量应该经过估计算法,以滤除信号中的噪声。在其它实施方式中,使用诸如最佳速度模型之类的模型的基于模型的方法可用于在了解车头时距和速度的情况下确定加速度。
[0083]
在一个实施方式中,所使用的控制算法基于深度强化学习。与普通的深度学习不同,深度强化学习使用深度神经网络来确定最小化值函数v的控件
[0084]
图4示出了根据一些实施方式的比较无模型和增强的强化学习的收敛性的图。图4示出实验结果表明,没有扩展调谐的简单深度神经网络具有令人满意的性能,这强烈表明增强强化学习非常适合该应用。增强最优控制的学习很快收敛401,而使用相同学习方法的无模型方法不收敛402。
[0085]
在将控制器应用于系统时,控制器是使用嵌入式计算机以数字方式实现的。出于这个原因,控制器的实现通常使用离散时间实现来完成。将连续时间设计转换为离时间散设计的过程是标准的,并且存在可以做到这一点的各种过程。特别是,我们在实验中使用零阶保持方法做到了这一点。
[0086]
更重要的是,动作空间(即,动作所在的集合)是连续的,因为是粒度的,即,的可能选择在理论上是不可数的。出于这个原因,我们发现有必要实现适用于利用连续
动作空间使用的深度强化学习算法。这种方法就是深度确定性策略梯度法。这是在实施方式之一中使用的方法,但上述方法和系统决不限于使用一种类型的强化学习算法。利用在实验中取得了与其它实施方式类似的成功,我们已经实现的其它方法使用优势-演员评论家方法。
[0087]
示例性实施方式
[0088]
图5示出了根据一些实施方式的用于直接和间接控制混合自动驾驶车辆的系统500的框图。系统500可以具有将系统500与其它机器和设备连接的多个接口。网络接口控制器(nic)550包括接收器,该接收器适于通过总线506将系统500连接到网络590,该网络590将系统500与混合自动车辆连接以接收一组混合自动驾驶车辆沿同一方向行驶的交通状态,其中,该组混合自动驾驶车辆包括愿意参加车队形成的受控车辆和至少一个不受控车辆,并且其中,交通状态指示该组中的每个车辆和受控车辆的状态。例如,在一个实施方式中,交通状态包括混合自动车辆的当前车头时距、当前速度和当前加速度。在一些实施方式中,混合自动车辆包括在车队中的受控车辆的侧翼预定范围内的所有不受控车辆。
[0089]
nic 550还包括适于经由网络590向受控车辆发送控制命令的发送器。为此,系统500包括输出接口,例如控制接口570,其被配置为通过网络590将控制命令575提交给该组混合自动驾驶车辆中的受控车辆。以这种方式,系统500可以布置在与混合自动车辆直接或间接无线通信的远程服务器上。
[0090]
系统500还可以包括其它类型的输入接口和输出接口。例如,系统500可以包括人机界面510。人机界面510可以将控制器500连接到键盘511和定点设备512,其中,定点设备512可以包括鼠标、轨迹球、触摸板、操纵杆、指点杆、触控笔或触摸屏等。
[0091]
系统500包括被配置为执行所存储的指令的处理器520、以及存储可由处理器执行的指令的存储器540。处理器520可以是单核处理器、多核处理器、计算集群或任何数量的其它配置。存储器540可以包括随机存取存储器(ram)、只读存储器(rom)、闪存或任何其它合适的存储机器。处理器520可以通过总线506连接到一个或更多个输入设备和输出设备。
[0092]
处理器520可操作地连接到存储指令以及处理由指令使用的数据的存储装置530。存储装置530可以形成存储器540的一部分或者可操作地连接到存储器540。例如,存储器可以被配置为存储参数化函数531,该函数被训练为将交通状态转换为混合自动驾驶车辆的目标车头时距;并且存储基于车头时距的模型533,该模型被配置为将目标车头时距映射到混合自动驾驶车辆的目标速度。
[0093]
处理器520被配置为确定用于受控车辆的控制命令,其也间接地控制不受控车辆。为此,处理器被配置为执行控制生成器532以将交通状态提交给参数化函数以产生目标车头时距,将目标车头时距提交给基于车头时距的模型以产生目标速度,并且基于目标车头时距和目标速度之一或组合确定对于受控车辆的控制命令。
[0094]
在一些实施方式中,参数化函数531是深度强化学习(drl)控制器,该控制器被训练以将该组混合自动驾驶车辆的交通状态转换为目标车头时距,而不是改进组中的混合自动驾驶车辆的动作,其中,根据基于车头时距的模型,由目标车头时距定义动作。例如,如上所述,目标车头时距被确定为使得动作改善车队形成的移动成本的价值函数。价值函数的示例包括混合自动车辆在计划时间范围内的移动成本总和的负值。
[0095]
在一些实施方式中,成本是鼓励车队形成的多个项的成本函数。例如,在一些实施
方式中,移动的成本包括与车队的串稳定性相关的分量、与车队的设备稳定性相关的分量以及惩罚目标车头时距接近停车车头时距的惩罚项。
[0096]
在各种实施方式中,drl控制器是用解决在线优化的基于车头时距的模型而增强的基于模型的drl,以同时学习具有交通状态的交通系统的行为并学习控制交通系统以形成车队,使得交通系统的行为由drl控制器产生的目标车头时距定义,并且交通系统的控制由根据基于车头时距的模型从目标车头时距确定的混合自动车辆的加速度来定义。
[0097]
在一些实施方式中,基于车头时距的模型是将目标车头时距映射到车辆速度的最优速度模型(ovm),使得drl控制器是ovm增强的drl。ovm将目标车头时距映射到车辆的速度。在一些实施方式中,系统500被配置为根据ovm从目标车头时距确定受控车辆的目标速度,并形成对受控车辆的控制命令以包括受控车辆的相应目标速度。
[0098]
例如,基于车头时距的模型(诸如,ovm)将混合自动车辆的当前车头时距、停车车头时距和前进车头时距与混合自动车辆的目标速度相关联。由参数化函数确定的目标车头时距是前进车头时距,并且系统500利用所确定的前进车头时距和预定的固定停车车头时距根据基于车头时距的模型来确定混合自动车辆的受控命令的目标速度。
[0099]
图6a示出了根据一些实施方式直接或间接控制的车辆601的示意图。如本文所用的,车辆601可以是任何类型的轮式车辆,诸如客车、公共汽车或越野车。此外,车辆601可以是自动或半自动驾驶车辆。例如,一些实施方式控制车辆601的运动。运动的示例包括由车辆601的转向系统603控制的车辆横向运动。在一个实施方式中,转向系统603由控制器602与系统500通信来控制。另外地或另选地,转向系统603可以由车辆601的驾驶员控制。
[0100]
车辆还可以包括引擎606,引擎可以由控制器602或车辆601的其它组件控制。车辆还可以包括一个或更多个传感器604以感测周围环境。传感器604的示例包括测距仪、雷达、激光雷达和相机。车辆601还可以包括一个或更多个传感器605以感测其当前运动量和内部状态。传感器605的示例包括全球定位系统(gps)、加速度计、惯性测量单元、陀螺仪、轴旋转传感器、扭矩传感器、偏转传感器、压力传感器和流量传感器。传感器向控制器602提供信息。车辆可以配备有收发器606,使控制器602能够通过有线或无线通信信道进行通信。
[0101]
图6b示出了根据一些实施方式的从系统500接收受控命令的控制器602与车辆601的控制器600之间的交互的示意图。例如,在一些实施方式中,车辆601的控制器600是控制车辆600的旋转和加速度的转向610和制动/油门控制器620。在这种情况下,控制器602向控制器610和620输出控制输入来控制车辆的状态。控制器600还可以包括高级控制器,例如进一步处理预测控制器602的控制输入的车道保持辅助控制器630。在这两种情况下,控制器600映射使用预测控制器602的输出来控制车辆的至少一个致动器(诸如车辆的方向盘和/或制动器)以控制车辆的运动。车辆机器的状态x
t
可以包括位置、取向和纵向/横向速度;控制输入u
t
可以包括横向/纵向加速度、转向角和引擎/制动扭矩。对该系统的状态约束可以包括车道保持约束和避障约束。控制输入约束可以包括转向角约束和加速度约束。所收集的数据可以包括位置、取向和速度曲线、加速度、扭矩和/或转向角。
[0102]
本发明的上述实施方式可以以多种方式中的任一种来实现。例如,可以使用硬件、软件或其组合来实现实施方式。当以软件实现时,软件代码可以在任何合适的处理器或处理器集合上执行,无论是在单个计算机中提供还是分布在多个计算机中。这样的处理器可以实现为集成电路,在集成电路组件中具有一个或更多个处理器。但是,可以使用任何合适
格式的电路来实现处理器。
[0103]
此外,本文概述的各种方法或处理可以被编码为可在一个或更多个处理器上执行的软件,该处理器采用多种操作系统或平台中的任何一种。此外,这样的软件可以使用多种合适的编程语言和/或程序或脚本工具中的任何一种来编写,并且还可以编译为在框架或虚拟机上执行的可执行机器语言代码或中间代码。通常,程序模块的功能可以在各种实施方式中根据需要被组合或分布。
[0104]
此外,本发明的实施方式可以具体实现为一种方法,已经提供了其示例。作为该方法的一部分执行的动作可以以任何合适的方式排序。因此,可以构建以不同于所示顺序执行动作的实施方式,这可以包括同时执行一些动作,即使在说明性实施方式中被示为顺序动作。
[0105]
尽管已经通过优选实施方式的示例描述了本发明,但是应当理解,在本发明的精神和范围内可以进行各种其它的修改和改变。因此,所附权利要求的目的是覆盖落入本发明的真正精神和范围内的所有这些变化和修改。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1