基于深度强化学习的四足机器人适应性步态自主生成方法
本发明涉及机器人运动控制领域,具体是指一种四足机器人环境适应性运动控制步态的自主生成方法。
背景技术:
随着机器人技术的不断发展,步行机器人的应用领域越来越广。双足机器人控制难度较高,六足及多足机器人制作难度较大,因此四足机器人由于其优势成为了足式步行机器人的研究重点。
四足机器人利用孤立的地面支撑而不是轮式机器人所需的连续地面支撑;在非平整的复杂吸顶中可以以稳定的不行方式而非接触式的行进方式避障;可以以跨步的方式跨过粗糙路面等。四足机器人由于其结构特性使其能够快速穿梭于崎岖不平的地面,这使得四足机器人尤其适用于搜救、侦察、野外运输等任务。自然界中大多数在自然地形中能够高速移动并灵活转向的哺乳动物都具有四足移动机构的配置,根据仿生学原理就可以构建四足机器人的运动控制策略。然而,不同任务中四足机器人执行移动任务的环境复杂多变,单纯的人为根据仿生学原理构建的四足机器人运动控制方法难以应用于四足机器人运动控制中。
复杂四足机器人的运动控制系统使非线性的多输入多输出不稳定系统,具有时变性和间歇动态性。目前四足机器人的步态运动大多数是基于步态的几何位置轨迹规划、关节位置控制的规划的控制策略。而对机器人进行单纯的集合位置或关节控制,会因为惯性、机器人状态不稳定等原因导致机器人失稳,同时,人工根据仿生学原理定义的四足机器人步态只能适应规定地形,不具备环境鲁棒性的同时,也不是环境中的最优控制步态。相较于传统的运动控制,使用强化学习的运动控制策略生成方法具有无模型、环境使用性强、控制策略自主生成的优点。
基于此,本发明提供了一种基于强化学习的四足机器人适应性步态自生成方法。
技术实现要素:
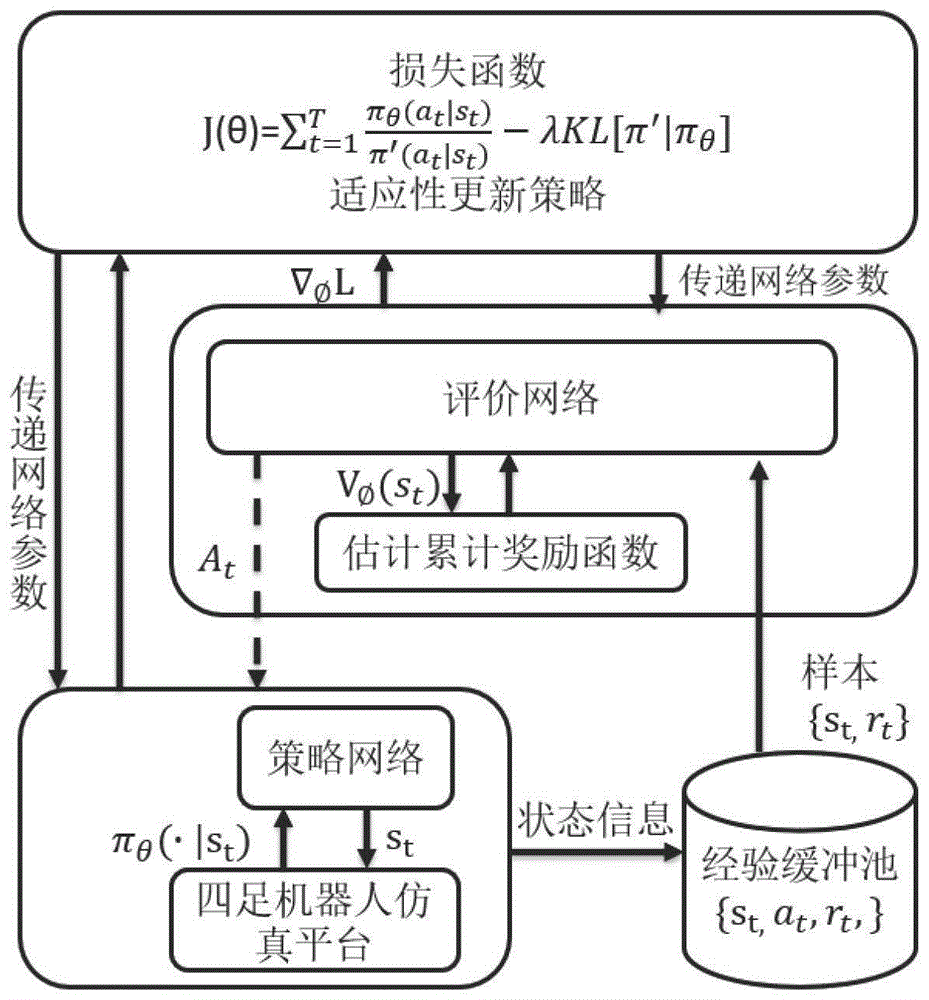
本发明目的在于提供一种四足机器人适应性步态生成方法,通过机器人在仿真环境中运行的过程中不断从环境中收集信息,自主生成适应当前环境的最优运动控制策略,解决上述四足机器人运动控制步态环境鲁棒性差、控制性能不好等问题。本发明利用深度神经网络、强化学习ppo算法、分布式计算等原理设计一种基于深度强化学习的四足机器人适应性步态生成方法,使四足机器人能够自主根据不同地形环境生成相应的最优适应性步态,使四足机器人能够高效、准确的工作。
本发明提出一种四足机器人适应性步态生成方法,包括以下步骤:
步骤1:利用pybullet物理引擎构建四足机器人快速仿真环境,包括四足机器人物理模型和物理属性;根据四足机器人需要执行行走任务的不同环境对环境的物理模型和物理属性进行建模,并通过可视化的方式进行显示;
步骤2:在仿真环境中,制定奖励函数,使用ppo算法在不同地形环境中优化四足机器人运动控制器,在仿真环境中,实现控制策略的自主生成;
步骤3:通过在不同环境、根据速度最优、能耗最优、末端控制力最优三种不同评价指标设定不同奖赏函数权重,在仿真中得到四足机器人适应性步态,根据不同的评价指标评价得到的四足机器人步态;
步骤1中,包括以下步骤:
步骤1.1:构建可视化的四足机器人模型。根据四足机器人结构特性,各关节重量、转动惯量、摩擦力系数等物理属性,使用solidworks构建四足机器人模型,并导入pybullet物理引擎中;
步骤1.2:构建环境模型。根据环境的摩擦力系数、阻尼比和地面刚度,
由平面、20°上坡、20°下坡这三个典型地形及他们的拼接地形构建相应的urdf格式地面模型并导入pybullet物理引擎中;
得到四足机器人和环境的模型之后,根据四足机器人适应性步态生成目标,构建基于强化学习的四足机器人步态自主生成框架。
步骤2中,包括以下步骤:
步骤2.1:设计深度强化学习ppo算法所使用的奖励函数r:
r=λo*(x1-xo)+λ1*(y1-y0)+λ2*(z1-zo)+λ3*e
其中,λi(i=0,1,2,3)表示奖励函数各部分所占的权重,通过调节λi的相对大小来控制各个指标的相对重要程度,λi的相对大小不同即可以使四足机器人生成评价指标不同的适应性步态。x1,y1,z1表示当前四足机器人的三维坐标值,x0,y0,z0表示前一时刻的坐标值,取当前的变化量作为奖励函数的指标;e表示四足机器人当前时刻消耗的能量,作为奖励函数的一部分,使用八个电机的当前转速和输出转矩乘积的和来表示。
步骤2.2:使用强化学习优化四足机器人腿部的关节角度:
设计强化学习框架需要的动作空间和状态空间。不对四足机器人的腿部结构进行建模,使用强化学习方法建立一个由当前时刻电机转动角度到下一时刻转动角度的映射。当前时刻电机转动角度代表了当前四足机器人的状态,下一时刻的转动角度代表了当前采取的控制策略。
步骤2.3:建立强化学习框架之后,在不同地面刚度、地面摩擦力系数、不同地形及他们的拼接中使用强化学习ppo算法优化四足机器人步态,生成适应不同环境的四足机器人步态。
在步骤2构建基于强化学习的四足机器人步态自主生成框架之后,根据不同的评价指标、不同的地形要求,重复执行强化学习算法,组织生成地形适应性的四足机器人步态。
在步骤3中,包括以下步骤:
步骤3.1:根据不同评价指标,设定不同奖励函数权重,根据不同奖励函数在相同地形上训练,得到不同的四足机器人适应性步态;
步骤3.2:重复步骤3.1,直到得到在一种地形上的不同评价指标下都有良好表现的四足机器人步态。使用不同地形再次使用ppo算法优化步态,使用单一典型地形、及不同典型地形的拼接作为训练环境;
步骤3.3:重复步骤3.1-3.2,直到得到在不同地形、不同评价指标下都有良好表现的四足机器人步态;
基于深度强化学习理论,构建具有较高样本利用率的四足机器人步态策略搜索控制框架。区别于现有技术,本发明将动态的环境和机器人参数空间的噪声进行建模,并将它们添加到强化学习算法的优化目标中去,实现四足机器人环境适应性步态控制策略的自主快速生成。
附图说明
构成本发明的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本发明的不当限定。
图1是本发明的整体系统的框架图;
图2是本发明中使用的不同地形示意图;
图3是本发明的以速度最优时提出方法与默认方法速度对比图;
图4是本发明的以能量最优时提出方法与默认方法消耗能量对比图;
图5是本发明的以末端碰撞力最优时提出方法与默认方法末端碰撞力对比图
图6是本发明的行走步态示意图;
具体实施方式
以下结合附图和具体实施例对本发明作详细描述。注意,以下结合附图和具体实施例描述的诸方面仅是示例性的,而不应被理解为对本发明的保护范围进行任何限制。
四足机器人模型根据实际四足机器人物理属性通过solidworks搭建后导入pybullet物理引擎;
使用pybullet引擎依照典型地形搭建相应的仿真环境,搭建的典型地形和地形组合如图2所示;
在pybullet中设置虚拟传感器,感知四足机器人位姿信息和自身关节转速、转矩;
根据不同评价指标,设置对应的奖励函数。在奖励函数的设置中,为了奖励四足机器人向前运动,通常λ1为正,λ2、λ3、λ4为负,根据评价指标的不同,设置λ1、λ4的相对大小不同来控制评价指标的重要程度;
建立多个独立并行的四足机器人训练环境,搭建分布式深度强化学习算法ppo框架,通过队列并行同步网络参数到各个四足机器人训练环境;
各个仿真环境中的四字机器人通过共享队列独立收集环境信息和四足机器人自身位姿和关节信息,并实时上传到经验缓冲池中;
经验缓冲池对接收到的环境信息和四足机器人位姿关节状态数据进行实时处理,当收集到足够数据后建立神经网络训练集,通过ppo方法生成四足机器人自适应步态;
以速度指标最优为在基础平面地形上生成自适应最优步态,奖励函数权重为(1.0,-0.3,-0.3,0.005),状态空间为八个电机当前时刻的输出转速,动作空间为八个电机下一时刻的输出转速,使用三层全连接层神经网络,每个隐藏层神经元个数为128个,使用relu作为非线性激活函数,获得速度指标最优的四足机器人步态,图3为使用深度强化学习生成的步态与仿生学步态的速度对比;
以能量消耗指标最优为在基础平面地形上生成自适应最优步态,奖励函数权重为(1.0,-0.3,-0.3,0.1),状态空间为八个电机当前时刻的输出转速,动作空间为八个电机下一时刻的输出转速,使用三层全连接层神经网络,每个隐藏层神经元个数为128个,使用relu作为非线性激活函数,获得能量消耗指标最优的四足机器人步态,图4为使用深度强化学习生成的步态与仿生学步态消耗能量的对比;;
以末端碰撞力指标最优为在基础平面地形上生成自适应最优步态,奖励函数权重为(1.0,0.3,0.3,0.5),状态空间为八个电机当前时刻的输出转速,动作空间为八个电机下一时刻的输出转速,使用三层全连接层神经网络,每个隐藏层神经元个数为128个,使用relu作为非线性激活函数,获得末端碰撞力指标最优的四足机器人步态,图5为使用深度强化学习生成的步态与仿生学步态的末端碰撞力对比;
针对不同典型地形和典型地形的拼接,在不同环境地形下使用上述三种指标进行训练,不同地形如图2所示;
调整不同地形的具体物理模型参数,接触刚度为105n/m(法向),106n/m(法向),107n/m(法向),108n/m(法向),阻尼比为0.2,摩擦系数0.1,以直线行走、满足不同性能指标为强化学习目标,生成适应不同地形的四足机器人步态,生成步态如图6所示;
执行多次训练,以不同性能指标最优为基准、在不同典型地形、不同典型地形组合、不同地形物理参数的环境上训练,得到可以适应不同环境、满足性能指标的四足机器人步态;
由仿真结果图3-6可知,四足机器人在虚拟的搜救环境中能够不断学习、优化步态,快速且稳定地提升步态控制性能,面对不同优化指标和不同复杂经中能够通过在环境中高效探索,能够快速、稳定的提升控制步态的性能,自主生成适应性步态,并均较现常用的仿生学提高20%以上;
尽管方法已对本发明说明性的具体实施方式逐步进行了描述,以便于本技术领域的技术人员能够进行领会,但是本发明不仅限于具体实施方式的范围,本领域技术人员可以在权利要求的范围内做出各种变形或修改,只要各种变化只要在所附的权利要求限定和确定的本发明精神和范围内。
- 还没有人留言评论。精彩留言会获得点赞!