基于谱半径-区间主成分分析的工业过程状态监测方法
weather station[j].isa transactions,2018,83:126-141.
[0007]
[3]j.yuan,s.wang,f.l.wang,s.m.zhang.abnormal condition identification via ovr-irbf-nn for the process industry with imprecise data and semantic information[j].industrial&engineering chemistry research,2020,59(11):5072-5086.
[0008]
[4]l.f.cai,x.m.tian.a new fault detection method for non-gaussian process based on robust independent component analysis[j].process safety and environmental protection,2014,92(6):645-658.
[0009]
[5]x.m.tian,l.f.cai,s.chen.noise-resistant joint diagonalization independent component analysis based process fault detection[j].neurocomputing,2015,149:652-666.
[0010]
[6]t.ait-izem,m.f.harkat,w.bougheloum,m.djeghaba.fault detection and isolation using interval principal component analysis methods[j].ifac-papersonline,2015,48(21):1402-1407.
[0011]
[7]p.cazes,a.chouakria,e.diday,y.schektman.extension de l’analyse en composantes principales
à
des donn
é
es de type intervalley[j].revue de statistique appliqu
é
e,1997,45(3):5-24.
[0012]
[8]郭均鹏,高成菊,赵昊昊.一种基于符号数据的群体推荐算法[j].系统工程学报,2015,30(1):127-134.
[0013]
[9]胡艳,王惠文.一种海量数据的分析技术——符号数据分析及应用[j].北京航空航天大学(社会科学报),2004,17(2):40-44.
[0014]
[10]冷慧男.估计区间特征值问题特征值界的一种新方法[j].应用力学学报,2007,24(4):615-618.
技术实现要素:
[0015]
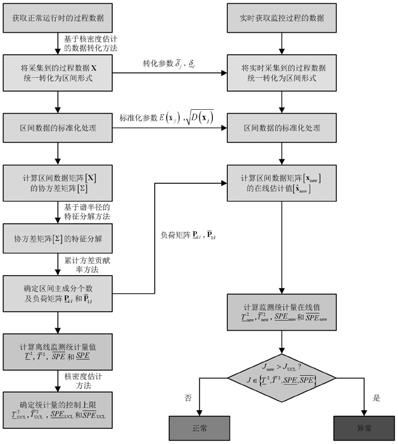
本发明提出了一种基于谱半径-区间主成分分析算法的过程状态监测方法。首先,在保留原始数据重要信息、把握数据属性内在关系的前提下,建立基于核密度估计的数据转化模型;其次,针对所获得的区间数据,设计基于谱半径-区间主成分分析算法,并引入四个监测统计量,以实现离线监测模型的建立;最后,针对实时采集到的过程数据,计算其在线监测统计量值,通过分析在线值与其控制限之间的关系进一步判断过程状态。技术方案如下:
[0016]
一种基于谱半径-区间主成分分析的工业过程状态监测方法,包括下列步骤:
[0017]
(1)针对工业过程所采集到的含有测量噪声、测量误差以及不确定性的数据,基于核密度估计的数据转化方法,将工业过程所采集到的过程数据转化为区间数据,方法如下:
[0018]
(1.1)采集正常工况下的过程数据,将所采集到的过程数据记为(n代表样本个数,m代表过程变量个数),xj=[x
1j
,x
2j
,...,x
nj
]
t
为第j个过程变量,其可以转化为区间数据需考虑以下两种情况,
[0019]
(1.2)第一种情况:若第j个过程变量xj的真实值无法获得,则该过程变量测量误
差上限δj通过专家估计或者相应传感器铭牌信息获得,第j个过程变量的第i,i=1,2,...,n,个样本数据由如下所示的区间数据表示:
[0020]
x
ij
=x
ij-δj[0021][0022]
式中,x
ij
和分别为第j个过程变量的第i个样本数据的区间下界和区间上界;
[0023]
(1.3)第二种情况:若第j个过程变量xj的真实值能通过离线实验检测或者其他方法获得,将该过程变量的真实值记为计算工业现场传感器测量值与变量真实值之间的相对误差γj,并基于核密度估计方法在显著性水平为α下估计相对误差γj的上限和下限γj,进而得到第j个过程变量的第i,i=1,2,...,n,个样本数据的区间表示:
[0024][0025][0026]
式中,x
ij
和分别为第j个过程变量的第i个样本数据的区间下界和区间上界;
[0027]
(1.4)基于上述步骤(1.1-1.3)的核密度估计的数据转化方法,将工业过程所采集到的过程数据转化为由如下矩阵表征的区间数据:
[0028][0029]
(2)基于步骤(1)所得到的区间数据,建立谱半径-区间主成分分析模型,对含有不准确过程数据的复杂工业过程进行特征提取,将高维区间数据投影到低维空间,方法如下:
[0030]
(2.1)对所获得的区间数据进行标准化处理,标准化后的数据仍记为[x];
[0031]
(2.2)区间数据的主成分通过对其协方差矩阵进行特征分解来提取,区间数据[x]的协方差矩阵计算式如下:
[0032][0033]
式中,i,j=1,2,...,m,m为过程变量个数,n为区间样本数,∑={σ
ij
}和分别为协方差矩阵[σ]={[σ
ij
]}的下界和上界,且有:
[0034][0035]
式中,e(xi)和分别表示第i个过程变量区间下界的均值和区间上界的均值,e
(xj)和分别表示第j个过程变量区间下界的均值和区间上界的均值,x
ki
和分别表示第i个过程变量的第k个样本数据的区间下界和区间上界,x
kj
和分别表示第j个过程变量的第k个样本数据的区间下界和区间上界;
[0036]
(2.3)对协方差矩阵[σ]进行特征分解,协方差矩阵[σ]的特征分解描述为:
[0037]
[σ]=pλp
t
[0038]
式中,λ为对角矩阵,其对角元素为协方差矩阵[σ]的特征值;p为特征向量矩阵,包含与协方差矩阵[σ]特征值相对应的特征向量;
[0039]
利用基于谱半径的区间矩阵特征分解方法,求得协方差矩阵[σ]的特征值及其对应的特征向量其中,i=1,2,...,m,且特征值按照降序排列,即λ1≥λ2≥...≥λm,两个特征向量矩阵p=[p1,...,pm]和分别由与特征值λi和对应的特征向量组成;其中,pi和分别表示由区间特征向量[pi]的下界和上界所组成的特征向量;
[0040]
(2.4)分别考虑特征向量矩阵p和的前l列和其余列,则矩阵p和被划分为p=[p
1:l p
l+1:m
]和其中,l是保留的区间主成分的个数,负荷矩阵和是通过分别选择协方差矩阵∑和的前l个特征值对应的特征向量生成的;保留的区间主成分个数l是根据累积百分比方差标准确定的,其中,前k个区间主成分下界和上界对应的累积方差贡献率计算式为:
[0041][0042][0043]
式中,cpv(k)和分别为前k个区间主成分下界和上界对应的累积方差贡献率;
[0044]
当且仅当以下不等式成立时,区间主成分的个数l=k:
[0045][0046]
式中,ω表示累积方差贡献率的下限;
[0047]
(2.5)基于上述步骤(2.1-2.4)求取的负荷矩阵p和可提取标准化处理后高维区间数据的特征信息,将其投影至线性低维空间:
[0048]
[0049]
式中,和分别表示区间数据矩阵[x]下界的估计和上界的估计;
[0050]
上述过程完成谱半径-区间主成分分析模型的建立;
[0051]
(3)引入离线监测统计量,并基于核密度估计方法确定统计量的控制限,具体实现过程如下:
[0052]
(3.1)对于经过标准化处理的训练集[x],计算第i个样本观测值的t2统计量和spe统计量:
[0053][0054]
式中,i=1,2,...n,和分别为第i个样本观测值区间下界和区间上界的t2统计量,spei和分别为第i个样本观测值区间下界和区间上界的spe统计量,为单位矩阵;
[0055]
(3.2)给定显著性水平β,基于核密度估计的方法确定四个监测统计量的控制限基于核密度估计的方法确定四个监测统计量的控制限spe
ucl
及
[0056]
(4)基于所求得的四个监测统计量的控制限,分析在线监测统计量与控制限之间的关系,实现过程状态的在线监测。
[0057]
进一步地,步骤(4)按以下子步骤实现:
[0058]
(1)从工业过程中实时采集过程数据基于核密度估计的数据转化方法,将采集到的工业数据统一转化为区间形式[x
new
];
[0059]
(2)针对所获得的区间数据进行标准化处理,标准化后的数据仍记为[x
new
];
[0060]
(3)将标准化后的区间数据[x
new
]代入已经建立好的谱半径-区间主成分分析模型中,将其投影至低维空间:
[0061][0062][0063]
式中,和分别表示区间数据[x
new
]下界x
new
的估计值和上界的估计值,p
1:l
和为负荷矩阵;
[0064]
(4)计算区间数据[x
new
]的四个监测统计量的在线值:
[0065][0066]
式中,和分别为实时采集到的工业数据区间下界和区间上界的t2统计量,spe
new
和分别为实时采集到的工业数据区间下界和区间上界的spe统计量;
[0067]
(5)分析监测统计量在线计算值与其相应控制限之间的关系,判断工况中是否出现故障,若存在任一监测统计量超出其控制限,则认为当前时刻过程中出现故障。
[0068]
本发明提出的基于核密度估计的数据转化方法使用核密度估计相对误差的概率分布函数,从而采用科学的方法将不准确的单值数据转化为区间形式,实现了对含有测量噪声、测量误差的过程数据的有效表示。同时,相比于现有的区间主成分分析算法,本发明设计的基于谱半径-区间主成分分析算法能够更加可靠地解决区间矩阵的特征分解问题,并能够更加高效地提取了区间数据的特征信息,大大降低了运算的复杂性以及运算量。此外,定义的四个过程状态监测统计量可以更全面地描述工业过程的运行状态,使得所提出的基于谱半径-区间主成分分析算法的复杂过程状态监测方法故障检测的鲁棒性大大提高。
附图说明
[0069]
图1基于谱半径-区间主成分分析算法的复杂工业过程状态监测流程图
[0070]
图2引入不同故障时的过程数据图
[0071]
图3引入故障1时数值仿真过程的状态监测图
[0072]
图4引入故障2时数值仿真过程的状态监测图
[0073]
图5不同状态监测算法在数值仿真过程的性能表现(%)
[0074]
图6引入阶跃故障4时te过程的状态监测图
[0075]
图7引入随机变量故障8时te过程的状态监测图
[0076]
图8引入慢偏移故障13时te过程的状态监测图
[0077]
图9引入粘住故障14时te过程的状态监测图
[0078]
图10不同状态监测算法在te过程的性能表现(%)
具体实施方式
[0079]
本发明涉及一种面向含有不准确过程数据的复杂工业过程的状态监测技术。具体来说,首先提出了基于核密度估计的数据转化方法,将工业过程所采集到的数据统一转化为了区间形式;其次提出了基于谱半径-区间主成分分析算法的过程状态监测方法,实现了对区间过程数据进行特征提取,并依据提取出的特征建立过程状态监测模型,实现工业过程的实时在线监测。所提出的基于谱半径-区间主成分分析算法的复杂工业过程状态监测方法总体流程图如图1所示,整个监测系统主要包括以下三部分:建立基于核密度估计的数据转化模型、建立基于谱半径-区间主成分分析算法的离线监测模型和过程状态的实时在线监测,以下为具体实施步骤:
[0080]
步骤1:建立基于核密度估计的数据转化模型
[0081]
在实际工业过程中,因为噪声干扰或者传感器测量问题的影响,所采集到的过程数据通常是不准确的。同时,受到复杂工况、恶劣的操作环境等因素的影响,一些关键的过程变量更是难以测量,这些变量通常由专家或有经验的工程师采用语义信息描述,并以区间数的形式表示。因此,本发明将由传感器采集到的不准确过程数据以及由专家或有经验的工程师所提供的数据信息统一转化为区间形式。
[0082]
假设在正常工况下所采集到的过程数据为(n代表样本个数,m代表过程变
量个数),xj=[x
1j
,x
2j
,...,x
nj
]
t
为第j个过程变量,其可以转化为如下所示的区间数据:
[0083][0084]
为了将过程变量xj转化为区间形式,需考虑两种情况。(1)如果第j个过程变量xj的真实值无法获得,则该变量测量误差上限δj可通过专家估计或者相应传感器铭牌信息获得,因此第j个过程变量的第i个样本数据可由如下所示的区间数据表示:
[0085][0086]
其中,i=1,2,...,n。
[0087]
(2)如果第j个过程变量xj的真实值可通过离线实验检测或者其他方法获得,将该变量的真实值记为传感器测量值与变量真实值之间的相对误差γj可定义为:
[0088][0089]
在本发明中,基于核密度估计方法估计相对误差γj的上限和下限,所选择的核函数为如下所示的径向基函数:
[0090][0091]
相对误差γj的概率密度分布函数的核估计为:
[0092][0093]
其中,h为带宽,充当光滑系数。
[0094]
那么,相对误差γj的概率分布函数可由下式计算:
[0095][0096]
随后,基于核密度估计确定在显著性水平为α下,计算相对误差γj的上限和下限。
[0097][0098]
一旦得到相对误差γj的上下限,第j个过程变量的第i个样本数据可由如下所示的区间数据表示:
[0099][0100]
其中,i=1,2,...,n。
[0101]
通过基于核密度估计的数据转化方法,可以将工业过程所采集到的过程数据转化为如下的区间值数据矩阵。
[0102][0103]
步骤2:建立基于谱半径-区间主成分分析算法的离线监测模型
[0104]
将过程数据统一转化为区间形式后,本发明基于谱半径-区间主成分分析算法对含有不准确过程数据的复杂工业过程进行特征提取,将高维区间数据投影到低维空间,在最小维度下保留了原始空间的最大方差。同时,引入离线监测统计量,并基于核密度估计方法确定了统计量的控制限,完成离线监测模型的建立。具体建模过程如下:
[0105]
(1)区间数据标准化处理。为了消除不同量纲对数据的影响,需对所获得的区间数据进行标准化处理。为了方便起见,标准化后的数据仍记为[x]。与单值数据进行标准化处理方法相似,区间数据的标准化处理为:
[0106][0107]
其中,e(xj),分别表示训练集第j个区间过程变量的均值和标准差。
[0108]
对于区间变量[xj],其均值的计算式为:
[0109][0110]
其中,为经验密度函数,μ
ij
为区间变量[x
ij
]的均值。在实际计算中,如果μ
ij
不易获得,则可以通过样本均值进行估计。
[0111]
若区间过程变量[xj]服从正态分布,其方差的计算公式为:
[0112][0113]
其中,为区间数据[x
ij
]的方差。在实际计算中,如果不易获得,则可以通过样本方差进行估计。
[0114]
(2)基于谱半径-区间主成分分析算法的设计。对于经过标准化处理的区间数据矩阵基于谱半径-区间主成分分析算法通过线性空间变换的方法可将高维区间数据投影到低维空间。与传统的主成分分析算法类似,高维区间数据的主成分可以通过对其协方差矩阵进行特征分解来提取。其中,区间数据[x]的协方差矩阵定义如下:
[0115][0116]
其中,i,j=1,2,...,m,m代表过程变量个数,n代表区间样本数,∑={σ
ij
},分别表示协方差矩阵[σ]的上界和下界,且有:
[0117][0118]
协方差矩阵[σ]的特征分解可以描述为:
[0119]
[σ]=pλp
t
ꢀꢀꢀꢀꢀꢀ
(15)
[0120]
其中,λ为对角矩阵,其对角元素为协方差矩阵[σ]的特征值;p为特征向量矩阵,包含与协方差矩阵[σ]特征值相对应的特征向量。
[0121]
目前,区间矩阵的特征分解比较常用的方法主要有deif法、摄动法以及谱半径法等,然而deif法存在计算量大的问题,摄动法虽然解决了deif法计算量大的缺点,但其结果往往不可靠。因此,为了降低运算量,较为可靠地实现式(15)中区间矩阵的特征分解,本发明参考文献[10],并基于对称矩阵的性质以及谱半径的单调性,采用了一种基于谱半径的区间矩阵特征分解方法,其分解过程如下所示:
[0122]
假设存在矩阵该矩阵的谱半径定义如下:
[0123]
ρ(a)=max{|λ|:λ∈λ(a)}
ꢀꢀꢀꢀꢀ
(16)
[0124]
其中,λ(a)表示矩阵a的所有特征值。
[0125]
给定对称的区间矩阵[ai]=[a
c-δa,ac+δa],存在矩阵a∈[ai]。这里,ac和δa分别表示区间矩阵[ai]的中点矩阵和半径矩阵。如果λ1≥λ2≥...≥λm是矩阵a按照降序排列的特征值,η1≥η2≥...≥ηm是矩阵ac按照降序排列的特征值,ρ是矩阵δa的谱半径,则有以下不等式成立:
[0126]
|λ
i-ηi|≤ρ
ꢀꢀꢀꢀꢀꢀ
(17)
[0127]
其中,i=1,2,...,m。
[0128]
因此,基于上述谱半径-区间矩阵特征分解方法,可求得协方差矩阵[σ]的特征值[λi]及其对应的特征向量[pi],即有:
[0129][0130][0131]
其中,i=1,2,...,m,且特征值按照降序排列,即λ1≥λ2≥...≥λm,
[0132]
两个特征向量矩阵p=[p1,
…
,pm]和分别由与特征值λi和对应的特征向量组成。其中,pi和分别表示由式(19)中区间特征向量[pi]的下界和上界所组成的特征向量。
[0133]
分别考虑特征向量矩阵p和的前l列和其余列,则矩阵p和可被划分为以下形式:
[0134][0135]
然后,基于下式,计算得分矩阵t和
[0136][0137]
其中,l是保留的区间主成分的个数。特别需要注意的是,负荷矩阵和是通过分别选择协方差矩阵∑和的前l个特征值对应的特征向量生成的。接下来,可对标准化处理后的区间数据矩阵[x]进行估计:
[0138][0139]
其中,和分别表示区间数据矩阵[x]下界的估计和上界的估计。
[0140]
随后,可计算由区间数据矩阵[x]及其估计值生成的残差[e]:
[0141][0142]
其中,矩阵e和分别表示区间残差矩阵[e]的下界和上界。
[0143]
综合以上内容可知,本发明所设计的基于谱半径-区间主成分分析算法可将原始高维数据空间划分为两个子空间,即主元子空间和残差子空间。
[0144]
在这里,保留的区间主成分个数l是根据累积百分比方差标准确定的。其中,前k个区间主成分下界和上界对应的累积方差贡献率计算式为:
[0145]
[0146]
当且仅当以下不等式成立时,区间主成分的个数l=k:
[0147][0148]
其中,ω表示累积方差贡献率的下限。
[0149]
(3)确定监测统计量及其控制限。综合上述内容可知,用于离线建模的训练集数据[x]被投影到了两个子空间,即主元子空间和残差子空间。因此在本发明中,通过分析主元子空间中的t2统计量和残差子空间中的spe统计量的在线计算值与统计量控制限的关系,进而判断该过程运行状态是否出现异常。对于经过标准化处理的训练集[x],第i个样本观测值的t2统计量采用如下数学表达式计算:
[0150][0151]
spe统计量,亦称为预测误差平方和指标,表示实际测量值与模型估计值之间的欧式距离,其计算公式如下所示:
[0152][0153]
其中,表示单位矩阵。
[0154]
在本发明中,上述四个监测统计量的控制上限基于核密度估计的方法来确定,当显著性水平取β时,有:
[0155][0156]
因此,基于上述步骤,便建立了基于谱半径-区间主成分分析算法的离线监测模型,下面将介绍监测系统的最后一部分——过程状态的实时在线监测。
[0157]
步骤3:过程状态的实时在线监测
[0158]
步骤2所求得的监测统计量的控制限是正常工况和异常工程的阈值,实时的、合理的分析在线监测统计量与控制限之间的关系,可实现过程状态的在线监测。针对从工业过程中实时采集到的过程数据其在线监测过程如下所示:
[0159]
(1)将采集到的数据统一转化为区间形式。基于核密度估计的数据转化方法,从工业过程中采集到的数据可统一转化为如下所示的区间形式:
[0160][0161]
其中,j=1,2,
…
,m,x
j,new
和可通过式(2)或式(8)求得。
[0162]
(2)区间数据标准化处理。随后,针对式(29)所获得的区间数据进行标准化处理:
[0163][0164]
其中,e(xj)和d(xj)分别表示第j个区间过程变量的均值和方差,由式(11)和式(12)计算得。
[0165]
(3)将区间数据投影至低维空间。接下来,将标准化后的区间数据[x
new
]代入已经建立好的基于谱半径-区间主成分分析模型中,将其投影至低维空间:
[0166][0167]
其中,和分别表示区间数据[x
new
]下界x
new
的估计值和上界的估计值,负荷矩阵p
1:l
和由式(20)获得。
[0168]
(4)计算监测统计量的在线值。下面,计算区间数据[x
new
]的四个监测统计量的在线值,如下所示:
[0169][0170]
(5)判断工况中是否出现故障。接下来,分析监测统计量在线计算值与其相应控制限之间的关系,若存在任一监测统计量超出其控制限,则认为当前时刻过程中出现了故障;反之,系统正常。
[0171]
为了验证本发明提出的基于谱半径-区间主成分分析算法(sr-ipca)的复杂工业过程状态监测方法的可行性及有效性,利用matlab软件分别在数值仿真过程和田纳西-伊斯曼标准测试过程中进行了仿真实验。同时,与传统的主成分分析算法(pca)、中点主成分分析算法(c-pca)以及顶点主成分分析算法(v-pca)进行了对比。主要仿真过程如下:
[0172]
(1)参数设置
[0173]
1)数值仿真过程参数设置:首先,设计了一个简单的六变量合成数据集来模拟正常工况下准确的过程数据,如下所示:
[0174][0175]
其中,ei(i=1,2,...,6)是标准偏差为0.01的独立高斯白噪声;信号源si(i=1,2,3,4)服从以下高斯分布:
[0176][0177]
将工业过程传感器所采集到的测量数据记为x=[x1,x2,x3,x4,x5,x6],其中测量误差wj(j=1,2,...,6)的构造如下所示:
[0178][0179]
其中,i=1,2,...,n,fi(i=1,2,...,6)服从均值为0,标准差为0.3的高斯分布,函数random(-|υ|,|υ|)表示从区间[-|υ|,|υ|]任意的取值。
[0180]
随后,对上述所构建的六变量系统进行仿真,进而获得正常工况下传感器所采集到的过程数据接下来,设显著性水平α为90%,建立基于核密度估计的数据转化模型,将不准确的过程数据x转化为区间数据[x],并利用所获得的区间数据建立基于谱半径-区间主成分分析算法的离线监测模型,此时参数ω设置为95%。
[0181]
为了验证本发明所提出的过程状态监测算法的可行性及有效性,在这里模拟了两种不同类型的故障,分别是阶跃故障和指数形式的缓变信号故障,具体设置如下:
[0182]
·
故障1:在变量1的第51个样本引入幅值为2.8的阶跃故障,如图2(a)所示。
[0183]
·
故障2:在变量3的第51个样本引入指数形式的缓变信号exp[0.1(k-50)]故障,如图2(b)所示,其中k=51,52,...,100。
[0184]
2)田纳西-伊斯曼过程参数设置:田纳西-伊斯曼过程(tennessee eastman,te)是一个由美国eastman化学公司的过程控制小组j.j downs和e.f vogel提出的化工生产过程。该过程的提出为评价过程控制和监测技术提供了一个真实的生产过程,目前已为学术界广泛使用。在此发明中,所使用的田纳西-伊斯曼过程的数据集为russel等人公开的数据集。其中,每个数据集包含960个观测样本,均是准确、可靠的。记在正常工况下te过程的准确观测数据为传感器所测得的含有测量噪声、测量误差的过程数据为x。在仿真实验中,将测量误差加入到准确的过程数据上,进而得到不准确的测量数据x,具体如下所示:
[0185][0186]
其中,j=1,2,...52,xj和分别表示第j个过程变量的测量值以及真实值,wj为第j个过程变量的测量误差,其在第i个观测样本的具体取值为:
[0187][0188]
其中,i=1,2,...960,αj(j=1,2,...,52)服从均值为0、标准差为0.0012的高斯分布。随后,对上述所构建的系统进行仿真,进而获得正常工况下传感器所采集到的过程数据x。设置显著性水平α为90%,建立基于核密度估计的数据转化模型,将不准确的过程数据x转化为区间形式[x],并利用所获得的区间数据建立基于谱半径-区间主成分分析算法的离线监测模型,此时参数ω设置为95%。
[0189]
te过程预设了21个故障,主要包括阶跃故障、随机变量故障、慢偏移故障、粘住故
障等类型的故障。接下来,为了验证本发明所提出的过程状态监测算法的可行性及有效性,试验在分别引入阶跃故障4、随机变量故障8、慢偏移故障13以及粘住故障14时,基于谱半径-区间主成分分析算法的过程状态监测方法的故障检测能力。
[0190]
(2)结果分析
[0191]
为说明本发明的可行性及有效性,在以下两个过程中进行仿真实验:
[0192]
过程1:数值仿真过程;过程2:田纳西-伊斯曼标准测试过程。
[0193]
数值仿真过程的仿真实验结果如图2-图5所示。其中,图2为向数值仿真过程分别引入不同故障时相应变量的变化情况,由图2(a)可知,阶跃故障1是一个变化幅度较小的故障,而图2(b)所示的指数形式的缓时变信号故障2是一个初期变化幅度小,随着时间的推移,变化幅度越来越大的故障。图3为不同故障检测算法在监测含有故障1的数值仿真过程时的在线监测图,如图3(a)所示,pca监测方法的统计量值t2和spe都在控制限内,因此,其故障漏报率高达100%;如图3(b)所示,在过程发生故障后,c-pca监测方法未能检测出异常采样点,漏报率同样高达100%;由图3(c)可知,v-pca监测方法在过程发生故障之前,就触发了10次误报;图3(d)为本发明所提方法的在线监测图,由该图可知在阶跃故障发生前,sr-ipca监测方法的统计量t2和spe大部分都在控制限以内,且当故障发生后,spe统计量迅速超出控制限,说明过程出现异常。图4为不同故障检测算法在监测含有故障2的数值仿真过程时的在线监测图,观察图4(a)和图4(b)可知,pca监测方法和c-pca监测方法均是在故障发生后的第18个采样点方才检测到过程出现异常;而v-pca监测方法在故障发生后,立即做出响应,其漏报率低至0%,但是在故障发生前,触发了11次误报;相比之下,sr-ipca监测方法仅触发了2次误报,且当故障发生后,立即检测到了异常状况。图5引入误报率(far)、漏报率(mdr)以及准确率(acc)三个状态监测模型评价指标,总结了不同状态监测算法在数值仿真过程的性能表现。由图5易知,pca监测方法和c-pca监测方法的故障检测性能很差,只能检测出幅度值较高的故障,导致其漏报率很大。上述实验结果进一步证明了,传统的pca监测方法的故障检测性能高度依赖于过程数据的质量,当传感器所采集到的数据夹杂高噪声、大测量误差时,其故障检测性能较差。同时,c-pca算法的实验结果表明,只选取区间内的中点来代表整个区间,会造成严重的信息丢失,使得过程监测性能变差。而与其他三种监测方法相比,v-pca监测方法对过程中出现的异常数据极其敏感,使得将一些含有高噪声、大测量误差的采样点误认为故障点,导致误报率升高。相比之下,本发明所提出的sr-ipca算法在高噪声、大测量误差情况下仍能保证状态监测的鲁棒性,当过程出现异常时,能快速地做出响应,同时误报率较低。综合上述分析可知,sr-ipca算法的故障检测性能明显优于pca算法、c-pca算法以及v-pca算法。
[0194]
田纳西-伊斯曼标准测试过程的仿真实验如图6-图10所示。由于te过程较为复杂,其采集到的数据包含52个过程变量以及960个观测值,若基于上述数据建立v-pca监测算法模型,则会产生一个960
·252
×
52维的超矩阵,针对该超矩阵进行建模工作量极大、计算机所需运行的时间极长。因此在te过程中,仅将本发明所提监测算法与pca算法以及c-pca算法进行对比分析。图6为不同故障检测算法在监测含有阶跃故障4时的在线监测图,由图6(a)和图6(b)可知,在故障发生前,pca算法和c-pca算法触发了很多次误报,其误报率超过了50%,而图6(c)所示结果显示,在故障发生前,本发明所提出的sr-ipca算法监测统计量大部分位于控制限以下,因此其误报率非常低。图7为不同故障检测算法在监测含有随机变
量故障8时的在线监测图,由图7易知,三种监测算法故障检测的能力均较好,即当故障发生后,均能及时地检测出故障,同时保证了在故障发生之前,触发的误报较少。图8为不同故障检测算法在监测含有慢偏移故障13时的在线监测图,观察图8(a)和图8(b)易知,在此情况下,pca算法与c-pca算法已经完全区分不出正常工况和异常工况,其误报率高达100%;相比之下,sr-ipca算法表现较佳,其能较为准确地识别出故障,且误报率较低,即本发明所提算法在高噪声、大测量误差存在的情况下,也能分区出正常工况和异常工况。图9为不同故障检测算法在监测含有粘住故障14时的在线监测图,对于图9(a)、图9(b)以及图9(c)可知,三种方法检测故障的能力均达到了最佳,即当故障发生后能立即检测出,其漏报率低至0%,然而在故障发生前pca算法和c-pca算法触发了较多的误报,特别是c-pca算法,其误报率超过了10%。图10引入误报率(far)、漏报率(mdr)以及准确率(acc)三个状态监测模型评价指标,总结了不同状态监测算法在te过程的性能表现。由图10可知,pca算法和c-pca算法在监测含有阶跃故障4、慢偏移故障13时的误报率非常高,很难区分出正常工况和异常工况。相比之下,sr-ipca算法误报率较低,过程中的高噪声、大测量误差对其过程状态监测能力影响较小。针对其他两种类型的故障,三种方法状态监测能力均较好,然而仔细观察,仍能发现sr-ipca算法过程监测的可靠性较高,其误报率、漏报率低,状态监测能力强。综合仿真实验结果可知,本发明所提出的sr-ipca算法可以在含有高噪声、大测量误差的数据中可靠地提取过程特征,提高了过程状态监测的鲁棒性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1