一种基于目标驱动的机器人环境感知方法
1.本发明涉及机器人导航技术领域,尤其涉及一种基于目标驱动的机器人环境感知方法。
背景技术:
2.几十年来,环境探索和测绘一直是机器人领域的热门研究。随着各种低成本传感器和计算设备的出现,使用多种不同的方法对机器人代理进行实时同时定位与地图构建(simultaneous localizationand mapping,slam)已经成为可能。传感器设备如摄像头,二维和三维激光雷达,以及它们的组合不仅用于检测和记录环境,还用于实现机器人的自主定位。然而,为了通过导航获得周围环境的可靠地图信息,大部分已开发的slam系统依赖人类的操作或预先描述的计划。
3.由于深度学习方法的普及和能力的提高,使用神经网络的机器人导航已经被开发出来,机器人能够直接从神经网络输出中执行有意的动作。机器人能够执行直接从神经网络输出获取的决策动作。目前大多数机器人环境探索方法在复杂环境下需要依赖地图或先验信息。然而,由于环境信息是在时间和空间上局部给出的,在全局上使用诸如深度q学习(deep qlearning)或者深度确定性策略(deep deterministic policy gradient)等深度强化学习的方法来进行导航可能会存在局部最优问题。并且由于涉及到安全性、泛化能力、局部最优等问题,它们很难在实践中部署。因此,基于神经网络的方法可以处理模块化任务,但不适合在全局端到端解决方案中实现。
技术实现要素:
4.为了解决上述技术问题,本发明提出一种基于目标驱动的机器人环境感知方法,在实际中部署更容易,且在复杂的静态和动态环境下,不需要依赖地图或先验信息。
5.为了达到上述目的,本发明的技术方案如下:
6.一种基于目标驱动的机器人环境感知方法,包括如下步骤:
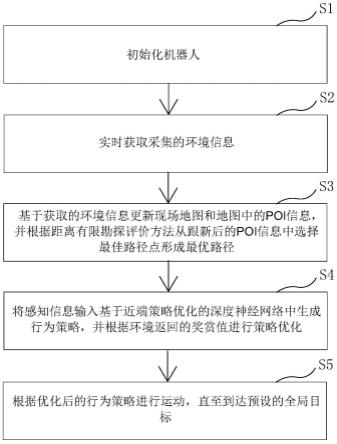
7.实时获取采集的环境信息;
8.基于获取的环境信息更新现场地图和地图中的poi信息,并根据距离有限勘探评价方法在跟新后的poi信息中选择最佳路径点形成最优路径;
9.将感知信息输入基于近端策略优化的深度神经网络中生成行为策略,并根据环境返回的奖赏值进行策略优化,所述感知信息包括环境信息、最优路径和机器人当前状态和动作;
10.根据优化后的行为策略进行运动,直至到达预设的全局目标。
11.优选地,所述更新地图中的poi信息中确定poi的方法,具体包括如下步骤:
12.获取以机器人为中心的未访问区域的激光点信息;
13.若两个连续激光点读数的差值大于预设阈值,则在两个探测点间添加poi点,所述预设阈值不小于机器人的尺寸大小;
14.若连续n个激光读数返回的均为非数值即探测区域超出激光探测设备的探测范围,其中n>5,则在探测区域内添加poi点。
15.优选地,所述更新地图中的poi信息后,对内存中存储的poi信息进行对应调整。
16.优选地,根据信息的距离有限勘探评价方法从跟新后的poi信息中选择最佳路径点形成最优路径,具体包括如下步骤:
17.计算跟新后的每个poi的适应度,公式如下:
[0018][0019]
式中,d(p
t
,ci)是机器人在当前时间步长上的位置p与候选点之间的欧几里德距d,d(ci,g)是候选点与全局目标之间g的欧几里德距离,为在t时间点地图信息的得分;
[0020]
根据每个poi的适应度的得分进行排序,将得分最少的poi点作为最佳路径点。
[0021]
优选地,将感知信息输入基于近端策略优化的深度神经网络中生成行为策略,并根据环境返回的奖赏值进行策略优化,具体包括如下步骤:
[0022]
所述行为策略的表达式为:
[0023][0024]
clip
∈
(x)=clip(x,1-∈,1+∈)
ꢀꢀ
(7)
[0025]
其中r
t
(θ)为概率比例,具体表示为:
[0026][0027]
clip函数表示当括号内的第一项小于第二项时,一直输出第二项的值,当第一项大于第三项时,一直输出第三项的值,
[0028]
策略的奖励函数如下式所示:
[0029][0030]
其中,状态动作对(s
t
,a
t
)在时间步的报酬r取决于三个条件:如果当前时间步长t与目标的距离小于阈值ηd,则获得正向奖励rg;如果检测到碰撞,则获得负向奖励rc;如果这两个条件都不存在,则根据当前线性速度v和角速度ω立即给予奖励,为了引导行为策略朝向目标,采用延迟属性奖励法进行以下计算:
[0031][0032]
其中n是更新奖励的先前步骤数。
[0033]
基于上述技术方案,本发明的有益效果是:本发明通过全局导航与局部导航相结合的方法来完成环境探索的目标。全局导航,通过设置感兴趣点和地图选择最佳路径点;基于深度强化学习的局部导航。从环境中提取兴趣点,并根据评估标准选择最佳路径点。在每一步中,以极坐标的形式向神经网络提供一个与机器人位置和航向相关的路径点。根据传感器数据计算动作,并朝着路径点执行。机器人通过使用基于深度强化学习的运动策略一步一步确定路径点直至引导到全局目标,从而缓解局部最优问题。与传统的深度学习导航方法相比,本方法结合了反应式局部和全局导航策略,基于深度强化学习的目标驱动导航
方法具有更容易在实际中部署,且在复杂的静态和动态环境下,不需要依赖地图或先验信息等优势,且使用基于近端策略优化的强化学习方法具有收敛更快,易于调参等优点。
附图说明
[0034]
图1是一个实施例中一种基于目标驱动的机器人环境感知方法流程图;
[0035]
图2是一个实施例中一种基于目标驱动的机器人环境感知方法的结构框图;
[0036]
图3是一个实施例中一种基于目标驱动的机器人环境感知方法中确定poi点的示意图;
[0037]
图4是一个实施例中一种基于目标驱动的机器人环境感知方法的仿真实验环境图;
[0038]
图5是一个实施例中一种基于目标驱动的机器人环境感知方法在仿真实验中所生成的poi图;
[0039]
图6是一个实施例中一种基于目标驱动的机器人环境感知方法在仿真实验中生成的轨迹对比图;
[0040]
图7是一个实施例中机器人通过收集激光雷达数据前往路径点生成的路径图。
具体实施方式
[0041]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
[0042]
如图1至7所示,本实施例提供一种基于目标驱动的机器人环境感知方法,更容易在实际中部署,且在复杂的静态和动态环境下,不需要依赖地图或先验信息,具体包括如下步骤:
[0043]
步骤s1,初始化机器人。初始化机器人的各项参数,各项参数如下表所示。
[0044]
参数设置详情表
[0045]
参数数值学习率0.01正向奖励rg1负向奖励r
c-1经验回放池的大小25600样本采样批次的大小1024一个循环内智能体的最大步数500迭代次数10000最大线速度v
max
0.5m/s最大角速度ω
max
1rad/s内核大小k1.5m/sl1,l25m,10m策略更新范围∈0.2τ0.01γ0.95
[0046]
步骤s2,实时获取采集的环境信息。
[0047]
本实施例中,机器人配备了两个不同高度的激光雷达传感器,最大测量距离为10米。校准了两种激光的位置和角度,并在机器人前180
°
范围记录激光读数。每个传感器的数据分为21组,选取每组的最小值作为代表性传感器数值。抽取每一组的最小值,创建21维激光读数输入。最终激光数据与极坐标结合到航路点。环境测绘是基于机器人顶部激光雷达传感器的全激光读数和内部移动机器人的里程测量来实现。使用ros软件包slam toolbox获取和更新全局环境地图。
[0048]
步骤s3,基于获取的环境信息更新现场地图和地图中的poi信息,并根据距离有限勘探评价方法在跟新后的poi信息中选择最佳路径点形成最优路径。
[0049]
本实施例中,全局导航:为了让机器人导航到全局目标,需要从可用的poi中选择用于局部导航的中间路径点。由于没有关于环境的初始信息,因此不可能计算出最优路径。因此,机器人不仅需要被引导到目的地,还需要探索沿途的环境,以便在遇到死胡同时识别出可能的替代路线。由于没有给出先验信息,可能的poi需要从机器人的直接环境中获取并存储在内存中。确定poi的方法有以下两种:
[0050]
(1)如果两个连续激光读数之间的值差大于阈值,则添加一个poi,允许机器人通过假定的间隙。通常阈值大小设置为机器人的物理尺寸大小。如图3中
②
情况所示。
[0051]
(2)由于激光传感器具有最大范围,该范围之外的读数将作为非数字类型返回,并表示环境中的未被探测到的区域。如果连续激光读数返回非数值,则将poi放置在环境中。如图3中
①
情况所示。
[0052]
如果在后续步骤中发现任何poi位于障碍物附近,它们将从内存中删除。poi将不会从机器人已经访问过的地方的激光读数中获得。此外,如果选择了一个poi作为路径点,但经过许多步骤无法到达,则删除该poi并选择一个新的路径点。我们使用基于信息的距离有限勘探评价方法(information-based distance limited exploration,idle)来评价每个poi并选择最优的poi点。idle评价每个poi的适应度为:
[0053][0054]
式中,d(p
t
,ci)是机器人在当前时间步长上的位置p与候选点之间的欧几里德距d。d(p
t
,ci)可表示为双曲正切函数。
[0055][0056]
其中,e是欧拉数,l1和l2是两步距离限制,在这两步距离限制中,可以对分数进行折扣。两步距离限制是根据深度强化学习训练环境的区域大小设置的。
[0057]
第二个参数d(ci,g)是候选点与全局目标之间g的欧几里德距离,
[0058][0059]
其中,c
x
,g
x
分别表示候选点c和目标点g的x坐标,cy,gy分别表示候选点c和目标点g的y坐标,
[0060]
在t时间点地图信息的得分表示为:i
i,t
是关于在当前时间步长上的候选点的
地图信息。我们使用一个大小为[k x k]的核来计算当前时间步长中候选点的信息得分i,其计算方法为:其中i
i,t
表示为:
[0061][0062]
其中,k为核的大小,x,y均为周围信息点的坐标,w和h分别代表核的宽度与高度
[0063]
在idle方法评价下得分最少的poi点将被作为本地导航的最佳路径点即航路点。步骤s4,将感知信息输入基于近端策略优化的深度神经网络中生成行为策略,并根据环境返回的奖赏值进行策略优化,所述感知信息包括环境信息、最优路径和机器人当前状态和动作。
[0064]
本实施例中,采用基于深度强化学习的局部导航。在原始的基于规划的导航堆栈中,局部运动按照局部规划器执行。在我们的方法中,我们使用神经网络运动策略替换这一层。我们利用drl在模拟环境中分别训练本地导航策略。本方法使用深度强化学习(deep reinforcement learning)在模拟环境中分别训练局部导航策略。采用基于近端策略优化(proximal policy optimization)的神经网络体系结构对运动策略进行训练。ppo允许在连续的动作空间中执行动作。机器人通过前180
°
范围内的激光读数来描述局部环境。该信息与航路点相对于机器人位置的极坐标相结合。组合数据用作ppo的actor网络中的输入状态。通过两个表示机器人线性速度a1和角速度a2的动作参数a连接到输出层。对输出层应用激活函数以将其限制在范围内(-1,1)。在输出动作之前,按最大线性速度vmax和最大角速度ωmax进行缩放,如下所示:
[0065][0066]
由于激光读取只记录机器人前方的数据,不考虑反向运动,将线速度调整为仅为正。
[0067]
采用了一种策略梯度方法,因为它直接建模了生成动作的策略,给定了来自代理的观察结果,并且更适合于像我们这样的连续动作空间。与其他策略梯度方法相比,ppo通过将参数(θ)更新绑定到信任区域,在训练期间提供了更好的稳定性,即确保更新后的策略不会与以前的策略偏离。在每个训练阶段,模拟中的机器人收集一批观察结果,直到时间tmax,然后根据损失函数更新策略,其策略表达式如下:
[0068][0069]
式中,j(θ)为θ的似然函数,为时刻t对于优势函数的估计,它表示此时在状态s
t
下采取动作a
t
所能获得的优势,
[0070]
clip
∈
(x)=clip(x,1-∈,1+∈)
ꢀꢀ
(7)
[0071]
其中,clip函数表示当括号内的第一项小于第二项时,一直输出第二项的值,当第一项大于第三项时,一直输出第三项的值,r
t
(θ)为概率比例,具体表示为:
[0072][0073]
其中π
θ
′
为行为策略概率,π
θ
为目标策略概率,s
t
表示t时刻的状态,a
t
表示t时刻采取的动作。
[0074]
策略的奖励函数如下式所示:
[0075][0076]
其中,d
t
表示t时刻与目标的距离,状态动作对(s
t
,a
t
)在时间步的报酬r取决于三个条件:如果当前时间步长t与目标的距离小于阈值ηd,则获得正向奖励rg。如果检测到碰撞,则获得负向奖励rc。如果这两个条件都不存在,则根据当前线性速度v和角速度ω立即给予奖励。为了引导导航策略朝向给定目标,采用延迟属性奖励法进行以下计算:
[0077][0078]
其中n是更新奖励的先前步骤数。这意味着,正向的目标奖励不仅归因于达到目标的状态动作对,在达到目标之前的每一个步骤n中也会获得。该网络学习了本地导航策略,该策略能够到达本地目标,同时直接从激光输入避开障碍物。
[0079]
步骤s5,根据优化后的行为策略进行运动,直至到达预设的全局目标。
[0080]
本实施例中,跟随航路点,机器人被引导向全局目标。一旦机器人接近全局目标,它就会导航到目标。沿途对环境进行了探索。
[0081]
使用激光雷达和机器人里程传感器作为源,获得环境的栅格地图。
[0082]
该探索方法的伪代码如下所示:
[0083]
[0084][0085]
实验结果分析:
[0086]
将提出的基于目标驱动的机器人环境感知算法(goal-driven robot environment perception,gd-rep)与最近基于规划的边界(nearest frontier,nf)勘探策略方法和不采用全局规划的强化学习探索方法(reinforcement learning,rl)进行比较,参照比较使用了在已知映射中使用dijkstra算法获得的路径(path planner,pp)。每种方法在如图4所示的环境中进行5次实验。使用gd-rep方法生成的poi点如图5所示,其中数字
标号为可用的poi点,为不可用的poi点。可以看出确定的数字标号点均为可探索路径上的点,均被障碍物遮挡。
[0087]
实验结果生成的轨迹图如图6所示,图中记录有gd-rep方法生成的轨迹图、rl方法生成的轨迹图以及nf方法生成的轨迹图。由图中轨迹可以看出,三种方法最终都能到达目标点,但是本发明提出的gd-rep的方法在前往目标点时所花费的时间和步数最少,且避免了可能出现的局部最优情况。对比图5、图6可知gd-rep生成的路径与poi点的选择完全对应。图7为二维仿真环境下机器人通过收集激光雷达数据前往路径点生成的路径图。
[0088]
以上所述仅为本发明所公开的一种基于目标驱动的机器人环境感知方法的优选实施方式,并非用于限定本说明书实施例的保护范围。凡在本说明书实施例的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本说明书实施例的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1