基于学生t分布方法的工业过程运行状态监测方法
1.本发明涉及了工业过程监测领域的一种状态监测方法,尤其涉及基于学生t分布方法的工业过程运行状态监测方法。
背景技术:
2.在工业过程监控中,运行状态的监测能够对已发生的故障进行精确识别,进而帮助操作人员针对性地铲除运作系统中的错误,这就使得运行状态的监测在故障诊断体系中占据着重要地位。另外,随着分布式控制系统的广泛应用,大量带有过程信息的数据被有效地采集与分析,这也推动了基于数据驱动建模方法的发展。
3.不幸的是,由于提供给专家的信息不足以及专家之间打标存在分歧等因素,导致在工业流程中充斥着大量污染标签的标签噪声问题。此前的研究中,为了应对标签噪声带来的检测性能下降等问题,往往从两种方面解决标签噪声问题。其中数据清理方法能够有效过滤掉明显的噪声样本,但是对用于过滤的分类器本身的鲁棒性要求较高且往往会伴随着大量正确样本的损失。而潜在变量标签噪声有着良好的理论基础,能够对标签噪声进行显式建模,但该方法此前未能很好地考虑偏离中心的随机噪声带来的影响。
技术实现要素:
4.为了解决上述问题,本文提出了一种基于学生t分布方法的工业过程运行状态监测方法。该方法结合了学生t混合判别分析与潜在变量标签噪声模型,建立了具有两种形式的条件概率结构模型,从而应对工业过程中的随机噪声问题。一方面,真实标签y到观测标签的映射以子标签转移概率表示,从而模拟随机噪声下的标签转移;另一方面,真实标签下的数据分布被考虑成学生t混合模型,既保证了工业数据的非高斯性,又对偏离中心的随机噪声具有很好的鲁棒性。整体上来看,所提出的方法能够提升随机噪声下对运行状态的监测性能。
5.本发明采用的技术方案是:
6.本方法包括以下步骤:
7.步骤1:采集真实工业过程中的变量及变量的运行状态作为训练样本,从而组成用于建模的训练样本集;
8.步骤2:对训练样本集的训练样本进行归一化的预处理;
9.步骤3:根据预处理后的训练样本集构建噪声容忍学生t混合判别分析模型;
10.步骤4:在线收集工业过程中的待检测变量,并对待检测变量进行归一化的预处理;
11.步骤5:利用步骤3中构建的分析模型对待检测变量进行分析获得待检测变量的运行状态完成运行状态的监测。
12.所述步骤2及步骤4对变量进行归一化处理后,各个变量的均值为0,方差为1。
13.所述工业过程中的变量包括汽提塔流量、反应器进料流速、排放流速、总进料量、
排放阀的排放速度和搅拌速度;所述变量的运行状态包括正常状态、阶跃故障、随机变量故障和未知故障。
14.所述变量的运行状态在分析模型的构造中作为标签使用。
15.所述步骤3具体如下:
16.3.1对分析模型参数集进行初始化,获得初始化后的分析模型参数集;
17.3.2通过训练样本集利用分析算法迭代获得分析模型的更新参数集,过程具体为:
18.第一步,输入训练样本集通过初始化后的分析模型参数集获取分析模型隐变量估计的更新值;
19.第二步,通过第一步的更新值获得分析模型的更新参数集,即完成构建噪声容忍学生t混合判别分析模型。
20.所述的分析模型参数集具体如下:
[0021][0022]
其中,表示待估计的参数集;xi表示训练集中第i个训练样本的变量,i∈[1,n];表示第i个训练样本的观测标签;zi表示第i个训练样本的真实子标签;n表示样本数;表示一种优化函数,通过调整优化参数θ使得处理对象获得最大值;p()表示概率函数,表示已知训练样本的变量xi和观测标签前提下,训练样本满足zi=c
jk
的概率;c
jk
表示第j个运行状态的第k个子类,j∈[1,j],k∈[1,rj];j表示运行状态的数目,rj表示第j个运行状态的子类数目;
[0023]
所述训练样本的变量xi的运行状态的转移概率条件分布概率p(xi|zi=c
jk
)及先验概率p(zi=c
jk
)具体根据以下公式确定:
[0024][0025]
p(xi|zi=c
jk
)=s(μ
jk
,∑
jk
,v
jk
)
[0026][0027]
p(zi=c
jk
)=π
jk
[0028]
其中,rm表示第m个运行状态的子类数目,m∈[1,j];π
jk
表示第j个运行状态的第k个子类c
jk
的先验概率;μ
jk
、∑
jk
、v
jk
分别表示第j个运行状态的第k个子类c
jk
的均值、方差及自由度;c
mr
表示第m个运行状态的第r个子类;γ
jkmr
表示第j个运行状态的第k个子类c
jk
到第
m个运行状态的第r个子类c
mr
的子标签转移概率,r∈[1,rj];表示第i个训练样本的观测子标签,d表示训练样本中的变量数目,s()表示学生t分布函数,γ()表示伽马函数;
[0029]
设定γ
jkmr
,π
jk
,μ
jk
,∑
jk
,v
jk
为分析模型的初始化参数。
[0030]
所述步骤3.1中初始化后的分析模型参数集如下:
[0031]
θ={γ
jkmr
,π
jk
,μ
jk
,∑
jk
,v
jk
};j,m∈[1,j];k,r∈[1,rj]
[0032]
其中,θ表示初始化的分析模型参数集。
[0033]
步骤3.2.1中,将训练样本集输入初始化的分析模型参数集θ获得分析模型隐变量估计的更新值,所述更新值包括变量xi被判断为属于第j个运行状态的第k个子类的估计概率p
ijk
、真实类别为第j个运行状态的第k个子类c
jk
被观测为第m个运行状态的第r个子类c
mr
的概率p
mjkr
、隐变量ui的充分统计量e
ijk
(ui)以及隐变量ui的对数的充分统计量e
ijk
(logui),所述更新值具体根据以下公式确定:
[0034][0035][0036][0037]eijk
(logui)=ψ(a
ijk
)-logb
ijk
[0038]
其中,ψ()表示对角伽马函数;s(xi|μ
jk
,σ
jk
,v
jk
)表示第i个训练样本的变量xi在均值为μ
jk
,方差为σ
jk
,自由度为v
jk
下的学生t函数;p
ijk
表示变量xi被判断为属于第j个运行状态的第k个子类的估计概率;p
mjkr
表示真实类别为第j个运行状态的第k个子类c
jk
被观测为第m个运行状态的第r个子类c
mr
的概率;ui表示变量xi的隐变量;e
ijk
(ui)与e
ijk
(logui)分别表示隐变量ui的充分统计量、隐变量ui的对数的充分统计量;
[0039]
式中,第一辅助变量a
ijk
及第二辅助变量b
ijk
具体通过以下公式确定:
[0040][0041][0042]
其中,λ
jk
表示第j个运行状态的第k个子类c
jk
的方差∑
jk
的倒数。
[0043]
步骤3.2.2中,根据步骤3.2.1获得的更新值确定分析模型的更新参数具体如下:
[0044][0045]
[0046][0047][0048][0049]
式中,η
ijk
=e
ijk
(logui)-e
ijk
(ui);
[0050]
其中,为分析模型参数集{γ
jkmr
,π
jk
,μ
jk
,∑
jk
,v
jk
}的更新值;η
ijk
表示隐变量ui的对数的充分统计量与隐变量ui的充分统计量的差。
[0051]
根据步骤3.2构建的分析模型的更新参数集以及贝叶斯法则确定待检测变量x
new
的运行状态y
new
具体如下:
[0052][0053]
式中p(x
new
|z
new
=c
jk
)及p(z
new
=c
jk
)通过步骤3.2.2中分析模型的更新参数确定,具体公式如下:
[0054][0055][0056]
其中,x
new
表示待检测变量;y
new
表示待检测变量x
new
的运行状态;z
new
表示待检测变量的真实子标签;表示求取使得()内函数最大的j值;p(j|x
new
)表示待检测变量x
new
属于第j个运行状态的概率;p(x
new
|z
new
=c
jk
)表示待检测变量x
new
属于第j个运行状态的第k个子类c
jk
时的概率密度函数;p(x
new
)表示待检测变量x
new
的概率密度函数;
[0057]
所述待检测变量x
new
的运行状态y
new
的表达式即构建的噪声容忍学生t混合判别分析模型。
[0058]
本发明的有益效果是:由于本发明能够模拟标签转移的概率且选用了具有重尾结构的分布函数,因此本发明能够非常稳定地减少甚至消除工业过程中由于先验知识不充分及专家打标分歧导致的随机噪声问题,且对非随机噪声问题也具有一定程度的鲁棒性。
附图说明
[0059]
图1为噪声容忍学生t混合判别分析模型示意图。
[0060]
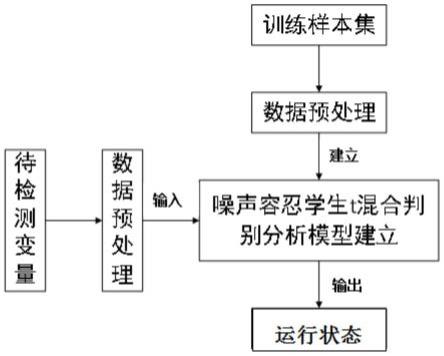
图2为本发明中监测方法的流程框图。
具体实施方式
[0061]
下面结合附图及具体实施例对本发明作进一步详细说明。
[0062]
如图2所示,本方法包括以下步骤:
[0063]
步骤1:采集真实工业过程中的变量及变量的运行状态作为训练样本,从而组成用于建模的训练样本集;
[0064]
步骤2:对训练样本集的训练样本进行归一化的预处理;
[0065]
步骤3:根据预处理后的训练样本集构建噪声容忍学生t混合判别分析模型;
[0066]
步骤4:在线收集工业过程中的待检测变量,并对待检测变量进行归一化的预处理;
[0067]
步骤5:利用步骤3中构建的分析模型对待检测变量进行分析获得待检测变量的运行状态完成运行状态的监测。变量的运行状态即反映着工业过程中的故障情况。
[0068]
步骤2中,对训练样本进行归一化处理后的训练样本集x
l
如下:
[0069]
x
l
=[x1,x2,
…
,xn]∈rm×n[0070]
其中,xn表示第n个训练样本,m和n分别代表训练样本的变量数量和训练样本的数量;
[0071]
式中,训练样本的数量n具体通过以下公式确定:
[0072][0073]
其中,nm表示训练样本的运行状态为m的样本数目。
[0074]
步骤2及步骤4对变量进行归一化处理后,各个变量的均值为0,方差为1。
[0075]
其中,工业过程中的变量包括循环流量、反应器进料速度、排放速度、总进料量、排放阀和搅拌速度等;变量的运行状态包括正常状态、阶跃故障、随机变量故障和未知故障。
[0076]
其中,变量的运行状态在分析模型的构造中作为标签。
[0077]
步骤3具体如下:
[0078]
3.1对分析模型参数集进行初始化,获得初始化后的分析模型参数集;
[0079]
3.2通过训练样本集利用分析算法迭代获得分析模型的更新参数集,过程具体为:
[0080]
第一步,输入训练样本集通过初始化后的分析模型参数集获取分析模型隐变量估计的更新值;
[0081]
第二步,通过第一步的更新值获得分析模型的更新参数集,即完成构建噪声容忍学生t混合判别分析模型,如图1所示。
[0082]
分析模型参数集,以极大似然函数展开后具体如下:
[0083][0084]
其中,表示待估计的参数集;xi表示训练集中第i个训练样本的变量,i∈[1,n];表示第i个训练样本的观测标签;zi表示第i个训练样本的真实子标签;n表示样本数;
表示一种优化函数,通过调整优化参数θ使得处理对象获得最大值;p()表示概率函数,表示已知训练样本的变量xi和观测标签前提下,训练样本满足zi=c
jk
的概率;c
jk
表示第j个运行状态的第k个子类,j∈[1,j],k∈[1,rj];j表示运行状态的数目,rj表示第j个运行状态的子类数目。
[0085]
训练样本的变量xi的运行状态的转移概率条件分布概率p(xi|zi=c
jk
)及先验概率p(zi=c
jk
)具体根据以下公式确定:
[0086][0087]
p(xi|zi=c
jk
)=s(μ
jk
,∑
jk
,v
jk
)
[0088][0089]
p(zi=c
jk
)=π
jk
[0090]
其中,rm表示第m个运行状态的子类数目,m∈[1,j];π
jk
表示第j个运行状态的第k个子类c
jk
的先验概率;μ
jk
、∑
jk
、v
jk
分别表示第j个运行状态的第k个子类c
jk
的均值、方差及自由度;c
mr
表示第m个运行状态的第r个子类;γ
jkmr
表示第j个运行状态的第k个子类c
jk
到第m个运行状态的第r个子类c
mr
的子标签转移概率,r∈[1,rj];表示第i个训练样本的观测子标签,d表示训练样本中的变量数目,s()表示学生t分布函数,γ()表示伽马函数。
[0091]
设定γ
jkmr
,π
jk
,μ
jk
,∑
jk
,v
jk
为分析模型的初始化参数。
[0092]
步骤3.1中初始化后的分析模型参数集如下:
[0093]
θ={γ
jkmr
,π
jk
,μ
jk
,∑
jk
,v
jk
};j,m∈[1,j];k,r∈[1,rj]
[0094]
其中,θ表示初始化的分析模型参数集。
[0095]
步骤3.2.1中,将训练样本集输入初始化的分析模型参数集θ获得分析模型隐变量估计的更新值,更新值包括变量xi被判断为属于第j个运行状态的第k个子类的估计概率p
ijk
、真实类别为第j个运行状态的第k个子类c
jk
被观测为第m个运行状态的第r个子类c
mr
的概率p
mjkr
、隐变量ui的充分统计量e
ijk
(ui)以及隐变量ui的对数的充分统计量e
ijk
(logui),更新值具体根据以下公式确定:
[0096][0097][0098]
[0099]eijk
(logui)=ψ(a
ijk
)-logb
ijk
[0100]
其中,ψ()表示对角伽马函数;s(xi|μ
jk
,σ
jk
,v
jk
)表示第i个训练样本的变量xi在均值为μ
jk
,方差为∑
jk
,自由度为v
jk
下的学生t函数;p
ijk
表示变量xi被判断为属于第j个运行状态的第k个子类的估计概率;p
mjkr
表示真实类别为第j个运行状态的第k个子类c
jk
被观测为第m个运行状态的第r个子类c
mr
的概率;ui表示变量xi的隐变量;e
ijk
(ui)与e
ijk
(logui)分别表示隐变量ui的充分统计量、隐变量ui的对数的充分统计量。
[0101]
式中,第一辅助变量a
ijk
及第二辅助变量b
ijk
具体通过以下公式确定:
[0102][0103][0104]
其中,λ
jk
表示第j个运行状态的第k个子类c
jk
的方差∑
jk
的倒数。
[0105]
步骤3.2.2中,根据步骤3.2.1获得的更新值确定分析模型的更新参数具体如下:
[0106][0107][0108][0109][0110][0111]
式中,η
ijk
=e
ijk
(logui)-e
ijk
(ui);
[0112]
其中,为分析模型参数集{γ
jkmr
,π
jk
,μ
jk
,∑
jk
,v
jk
}的更新值;η
ijk
表示隐变量ui的对数的充分统计量与隐变量ui的充分统计量的差;
[0113]
由于更新后的第j个运行状态的第k个子类c
jk
的自由度不存在闭式解,实际应用中通过二分法等一维搜索方法求解自由度
[0114]
步骤3.2.2具体为,通过分析算法对分析模型反复迭代直至分析模型收敛,并记录下此时分析模型的参数集作为该分析模型的更新参数集。
[0115]
根据步骤3.2构建的分析模型的更新参数集以及贝叶斯法则确定待检测变量x
new
的运行状态y
new
具体如下:
[0116][0117]
式中p(x
new
|z
new
=c
jk
)及p(z
new
=c
jk
)通过步骤3.2.2中的分析模型参数集确定,具体公式如下:
[0118][0119][0120]
其中,x
new
表示待检测变量;y
new
表示待检测变量x
new
的运行状态;z
new
表示待检测变量的真实子标签;表示求取使得()内函数最大的j值;p(j|x
new
)表示待检测变量x
new
属于第j个运行状态的概率;p(x
new
|z
new
=c
jk
)表示待检测变量x
new
属于第j个运行状态的第k个子类c
jk
时的概率密度函数;p(x
new
)表示待检测变量x
new
的概率密度函数;
[0121]
待检测变量x
new
的运行状态y
new
的表达式即构建的噪声容忍学生t混合判别分析模型。
[0122]
具体的,田纳西-伊斯曼工业过程主要由五个操作单元组成:反应器、冷凝器、压缩机、分离器和汽提塔,通过各单元的相互作用从而模拟动态、非线性等复杂化学过程。
[0123]
本发明选取53种变量分别在22种运行状态下的数据作为该分析模型的训练样本。
[0124]
本实施例分别采集工业过程中的反应器进料流速、排放流速、汽提塔流量和总进料量作为检测变量,将检测变量输入本分析模型后获得工业过程的运行状态具体如表1所示。
[0125]
表1
[0126][0127]
综上,本发明利用集散控制系统收集不同运行状态下的数据及其对应的标签,建立了噪声容忍学生t混合判别分析模型。该分析模型具有两种形式的条件概率结构,并可以通过分析算法得到结构参数。对不同运行状态下的变量进行采集与预处理,获得测试样本集,然后利用已有的模型结构估计测试样本的最大后验概率及对应的预测标签实现对该分析模型的模型参数的确定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1