基于强化学习的多机器人围捕多目标的分布式决策方法
1.本发明属于机器人的技术领域,具体涉及基于强化学习的多机器人围捕多目标的分布式决策方法。
背景技术:
2.移动目标的围捕,是指多个追逐者对可移动目标进行包围,约束移动目标的活动范围,使得移动目标无法移动。由于移动目标的速度较快,活动较灵活,单个追逐者无法独立完成对目标的包围,需要多个追逐者之间相互协作,从不同角度同时进行包围才能高效地完成追逐任务。
3.目前,对于多机器人围捕问题的大部分研究都比较传统与局限:
4.1.未考虑环境内的障碍物情况,然而在现实应用中,环境中存在着诸如障碍物、禁航区、禁行区等无法进入的区域;
5.2.未考虑多个逃跑者的情况,多机器人围捕多目标的问题区别于传统的多机器人追逐单目标的问题,多机器人围捕多目标任务需要将目标分配和运动规划统筹考虑,对目标分配和多机器人的协同性提出了重要挑战;
6.3.将逃跑者的运动策略以诸如人工势场法等非学习类的策略来表示,然而此种非学习类表示方法欠缺智能性,以此逃跑策略为目标而设计/训练出的围捕策略模型极易过拟合,并由于其缺乏鲁棒性和泛化性而无法现实应用;
7.4.将围捕追逐问题定义为追逐者追到逃跑者(即判定依据为追逐者和逃跑者发生碰撞),但是在更一般的场景而言,如水面舰艇的包围或地面车辆的包围,多数的情况是以不损毁己方机器人和目标机器人的情况下从而限制目标机器人的运动;
8.5.追逐者和逃跑者的数量不多,无法适应大规模集群围捕的场景,同时由于增加了追逐者后智能体的整体数量变多,容易导致状态空间维度爆炸和环境的不稳定性,如何更好地表示大规模集群问题中的观测值极为重要。
9.因此怎样对多机器人追捕者围捕多个机器人逃跑者进行训练提升追逐者协同学习对抗仍然是需要改进的问题。
技术实现要素:
10.为了实现以上目的,本发明提供了基于强化学习的多机器人围捕多目标的分布式决策方法。
11.本发明采用以下技术方案:基于多智能体强化学习的多机器人围捕多目标的分布式决策方法,包括以下步骤:
12.步骤一、对仿真环境进行初始化,随机生成障碍物、追逐者和逃跑者的状态信息,所述追逐者和逃跑者都为智能体的机器人;
13.步骤二、获取每个机器人的观测值信息;
14.步骤三、获取机器人的可行动作,通过遍历机器人的动作空间得到可行动作集;
15.步骤四、策略神经网络根据每个机器人的观测值信息,从该机器人当前状态的可行动作集中选择出一个动作;
16.步骤五、仿真环境根据策略神经网络输出的每个机器人的动作对每个机器人进行位置和状态更新,并计算执行该动作所获得的奖励;
17.步骤六、将步骤四-步骤五的决策过程存储到经验收集池中;
18.步骤七、重复步骤二-步骤六,直到达到单轮最大的仿真时间;
19.步骤八、根据存储器中的各个智能体与仿真环境的交互信息,使用多智能体强化学习算法进行训练;
20.步骤九、重复步骤一-步骤八,直到达到最大的交互训练轮数。
21.进一步的,所述步骤一具体为:
22.11、对仿真环境进行初始化,定义仿真环境的地图大小后,对追逐者与逃跑者的期望距离、期望距离系数进行定义,对相同类别的智能体的惩罚距离、惩罚距离的惩罚系数进行定义,对两个机器人之间的危险距离、危险距离的惩罚系数进行定义,对约束距离、禁止动作的距离进行定义;
23.12、随机生成障碍物、追逐者和逃跑者的状态信息。
24.进一步的,所述步骤二中,追逐者的观测值信息包括自身的位置和速度信息、其他追逐者相对于自己的位置和速度信息、逃跑者相对于自己的位置和速度信息、障碍物的半径和其相对于自己的位置信息;
25.逃跑者的观测值信息包含自身的位置和速度信息、其他逃跑者相对于自己的位置和速度信息、追逐者相对于自己的位置和速度信息、障碍物的半径和其相对于自己的位置信息。
26.进一步的,所述步骤三具体为:
27.追逐者和逃跑者的动作空间定义为离散的动作,每个机器人可选速度有m个,可选角度/角速度为n个,对其进行组合,则该机器人一共有m
×
n个可选动作;
28.已知仿真环境的地图信息和其他机器人的状态信息,在当前位置状态下,对所有的可选动作在一个仿真步长内进行一次试探性的虚拟更新,如果更新得到的新的位置不满足预先设置的要求,将这个动作记录为不可执行动作,遍历完毕所有的可选动作之后,每一个机器人都得到一个可行动作集。
29.更进一步的,所述预先设置的要求为:与其他机器人或障碍物发生碰撞或进入危险碰撞区域。
30.进一步的,所述步骤四具体为:
31.根据追逐者、逃跑者的当前状态和当前可行动作集,利用循环神经网络(rnn)对己方、对方和障碍物的信息进行特征提取,将提取出的特征信息与自身状态信息进行拼接,将得到的拼接结果输入到一个全连接层,经全连接层计算输出计算结果;
32.将全连接层的计算结果和循环神经网络上一个时间步的隐层状态输入到循环神经网络,然后使用循环神经网络的隐层状态和当前可行动作集作为动作决策层的输入,动作决策层输出当前状态下可执行动作的概率分布,追逐者从该概率分布中采样获得具体执行的一个动作。
33.进一步的,所述步骤五中计算执行该动作所获得的奖励具体为:基于追逐者和逃
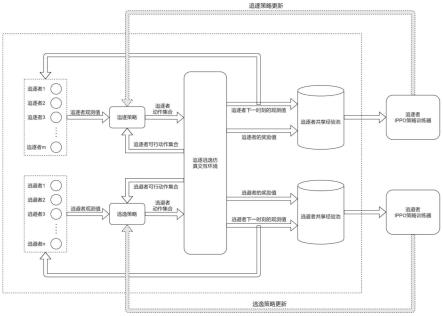
跑者在完成“追逐”或“逃跑”这个最高层级的任务时,还需要完成底层的任务,底层的任务包括避免与其他的追逐者、逃跑者、仿真环境的边界、障碍物中任一者的距离过近,追逐者和逃跑者的奖励都采用复合奖励函数。
34.进一步的,所述步骤六包括:
35.(6.1)初始化,为充分利用计算机资源进行训练数据的收集与策略交互,开辟n
rollout
个线程进行训练过程中的策略交互和数据收集;
36.(6.2)策略交互,记录当前追逐者的策略网络为记录当前逃跑者的策略网络为使用当前追逐者和逃跑者的策略与仿真环境进行交互n
length
步,由于追逐者和逃跑者内部为策略参数共享,所以可以将不同的追逐者视为“并行的”经验收集器,将每一步收集到的马尔可夫决策过程(s
t
,a
t
,r
t
,s
t+1
)分别存储到追逐者、逃跑者各自内部共享的经验存储池当中。
37.本发明的有益效果为:本分布式决策方法能够在有限的、随机散布障碍物的区域内实现对于多个快速移动并且具备智能性的逃跑者进行围捕,主要通过多智能体强化学习的方法对逃跑者和追逐者同时进行训练以引入博弈对抗的仿真环境,训练得到的分布式围捕策略能够实现运动过程中避免碰撞、协同围捕,训练得到的分布式逃跑策略具备较强的智能性以供追逐者学习对抗,该分布式决策方法高效可靠。
附图说明
38.图1是我们设计的追逐逃逸仿真训练框架;
39.图2是成功围捕的三种情况:追逐者把逃避者围在环境边缘、追逐者包围逃避者和追逐者把逃避者包围在障碍物上;
40.图3是训练得到的追逐者和逃避者策略模型的仿真验证;
41.图4是步骤四的流程图。
具体实施方式
42.结合附图对本发明具体方案具体实施例作进一步的阐述,使得本技术方案更加清楚、明白。本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
43.本实施例涉及基于强化学习的多机器人围捕多目标的分布式决策方法,如图1所示,针对智能体如机器人进行训练,主要在一个设定大小的仿真环境中,利用多个作为追逐者的机器人群体协作,对多个作为逃跑者的机器人进行追捕,在追捕过程中避免单个机器人与环境中的障碍物或其他机器人或环境边界发生碰撞。
44.步骤一、对仿真环境进行初始化,随机生成障碍物、追逐者和逃跑者的状态信息,状态信息包括坐标、朝向角等相关信息,所述追逐者和逃跑者都为智能体的机器人。
45.具体的,如图2所示,我们构建了这么一个场景的仿真环境,如图2中最外圈的大圆代表仿真环境的边界,在该环境内,最小的圆球为速度较慢、半径较小的同构追逐者,中等的圆球为速度较快、半径较大的逃跑者,最大的圆球为环境中存在着的随机分布的障碍物。
其中的追逐者的目的是尽可能快的在避免碰撞的前提下围捕包围逃跑者,逃跑者的目的是尽可能地在避碰的前提下躲避追逐者的围捕,区别于传统的研究将追逃问题定义为追逐者(最小的圆球)与逃跑者(中等大小的圆球)发生碰撞,在我们的研究中将围捕成功定义为逃跑者被追逐者包围,如图中所示的不同位置中多个追逐者包围一个逃跑者。由于在现实生活中的机器人集群追逃场景中,如海上针对目标舰艇的包围、地面针对目标车辆的包围,均需要考虑与障碍物的避碰和智能体之间的避碰,所以我们相信我们所设计的场景更贴合于实际应用需求。
46.对仿真环境进行初始化,定义仿真环境的地图大小。对追逐者与逃跑者的相关参数进行定义,包括:
47.定义追逐者与逃避者的期望距离为:expectedd;
48.定义追逐者与逃避者的期望距离系数为:ratio
expected
;
49.定义相同类别的智能体的惩罚距离为:innerd;
50.定义相同类别的智能体的惩罚距离的惩罚系数为:ratio
inner
;
51.定义危险距离为:dangerousd;
52.定义危险距离的惩罚系数为:ratio
dangerous
;
53.定义约束距离为:constrianedd;
54.定义禁止动作的距离为:forbiddend。
55.下标d均表示距离。
56.随机生成障碍物、追逐者和逃跑者的坐标和朝向角等状态信息,所有追逐者和逃避者的初始速度为零。
57.这里我们定义追逐者:半径大小为r
p
,最大速率为v
p
,受到最大角速度的约束限制,最大角速度为ω
p
;定义逃跑者:半径大小为re,最大速率为ve,不受到最大角速度限制,朝向角能够瞬时改变。p表示pursuer,表示该属性为追逐者的属性,e为evader,表示该属性为逃避者的属性。
58.定义追逐者:将速度离散为m
p
个选项,角速度离散为n
p
个选项;逃跑者:将速度离散为me个选项,由于不受到最大角速度的限制,所以将角度变化量由-π~π离散为ne个选项。
59.步骤二、获取每个机器人的观测值信息,智能体的观测信息具体包括:自身信息、己方信息、对方信息和环境信息(障碍物等)。具体的:
60.对于追逐者而言,观测值包含自身的位置和速度信息、其他追逐者相对于自己的位置和速度信息、逃跑者相对于自己的位置和速度信息、障碍物相对于自己的位置信息;
61.对于逃跑者而言,观测值包含自身的位置和速度信息、其他逃跑者相对于自己的位置和速度信息、追逐者相对于自己的位置和速度信息、障碍物相对于自己的位置信息。
62.本方法对于观测值的设计和考虑如下:
63.采用实验的仿真环境为圆形的环境,所有的智能体均在此仿真环境的范围中进行“围捕”和“逃脱”任务,考虑到圆形环境的对称性,本方法设计如下的坐标规范化方法:以智能体的朝向角为x轴,以该轴逆时针旋转90
°
为y轴,以智能体当前位置为原点,建立“自我坐标系”,为方便后续区别,这里记为
″
self-frame
″
,与此相对应的,是世界坐标系(绝对位置坐标系),记为
″
abs-frame
″
。
64.自身信息:《是否发生碰撞,
″
abs-frame
″
的原点在
″
self-frame
″
下的极坐标表达,
当前速率》;
65.己方的队友信息:《该队友是否发生碰撞,该队友的
″
abs-frame
″
坐标在
″
self-frame
″
下的极坐标表达,队友当前速度矢量与自身速度矢量差》;
66.目标信息:《该目标是否发生碰撞,该目标的
″
abs-frame
″
坐标在
″
self-frame
″
下的极坐标表达,目标当前速度矢量与自身速度矢量差》;
67.障碍物信息:《障碍物半径,障碍物的
″
abs-frame
″
坐标在
″
self-frame
″
下的极坐标表达》。
68.步骤三、获取机器人的可行动作,通过遍历机器人的动作空间得到可行动作集。本方法将追逐者和逃避者的动作空间定义为离散的动作,假设对某一个机器人而言,其可选速度有m个,可选角度/角速度为n个,则该机器人一共有m
×
n个可选动作。由于我们对地图信息已知,对于场景中其他机器人的状态信息也已知,那么我们在当前的位置状态下,对所有的可选动作在一个仿真步长内进行一次试探性地虚拟更新,如果更新得到的新的位置不满足预先设置的要求(如发生碰撞或进入危险碰撞区域等),我们将这个动作记录为不可执行动作,遍历完毕之后,对于每一个机器人而言都能得到一个可选动作的集合即可行动作集。
69.获取可行动作具体过程为:当我们得到了智能体的观测值,我们对该智能体所有的可选动作在一个仿真步长内进行一次试探性地虚拟更新,具体的更新方式参见后面对智能体动作空间的所有动作进行遍历,按照后面步骤五中的位置更新方法进行一次试探性地虚拟更新执行。
70.智能体之间的碰撞判定:智能体a的坐标为(posax,posay),智能体b的坐标为(posbx,posby),两者之间的距离为如果d小于智能体a和智能体b的半径之和,即d<ra+rb,则认为智能体之间发生碰撞。
71.智能体与障碍物的碰撞判定:智能体a的坐标为(posax,posay),障碍物o的坐标为(posox,posoy),两者之间的距离为如果d小于智能体a和障碍物o的半径之和,即d<ra+ro,则认为智能体与障碍物发生碰撞。
72.智能体与环境的碰撞判定:智能体a的坐标为(posax,posay),环境圆心的坐标为(0,0),两者之间的距离为如果d$d$和智能体a的半径之和大于环境的半径,即d+ra>r
env
,则认为智能体与环境边缘发生碰撞。
73.步骤四、追逐者/逃避者的策略神经网络根据对应的机器人的观测值信息,从该机器人当前状态的可行动作集中选择出一个动作。
74.由于追逐者和逃避者均设计为离散的动作空间,神经网络每次以观测值作为输入,并以动作空间中的一个动作作为输出。
75.经步骤一一步骤三,我们得到当智能体当前状态和当前的可行动作集,观测值中包含着自身信息、己方信息、对方信息和环境信息等,由于环境中的智能体数目较多,采用循环神经网络rnn对己方和对方的信息进行处理,解决维度爆炸的问题,并将循环神经网络的输出与自身信息和环境信息进行拼接,将拼接的结果输入到一个全连接层,全连接层的节点数为128或256,经过全连接层的计算,我们得到一个全连接层的输出,我们将这个输出输入到一个循环神经网络,同时,循环神经网络将上一个时间步长上的状态输出同时作为
输入进行计算,我们提取循环神经网络的隐层状态和此前得到的当前时刻可选动作集合作为动作决策层的输入,输出当前状态下可执行动作的概率分布,智能体从该分布中进行采样获得具体执行的一个动作。
76.策略神经网络的结构及实现过程如图4所示,其中包含全连接层、动作决策层和多个循环神经网络(rnn),这些子网络组合构成了策略神经网络。策略神经网络以状态作为输入,经过内部的子网络(全连接层、rnn等)做特征提取和动作选择(动作输出层),输出一个动作。
77.策略神经网络的动作输出:由智能体的观测和获取可执行动作,我们得到了当前状态下的观测值信息和当前状态下的可执行动作,我们将观测值信息输入到策略神经网络中的子网络,经过子网络内部的状态处理和特征提取,得到一个离散动作的概率分布,我们根据当前状态下的可执行动作集合,对不可执行的动作(非法动作)在概率分布上将其进行屏蔽,得到一个新的分布,我们从这个新的概率分布中进行采样,便可以获得当前状态下的合法动作,采样得到的动作便是策略神经网络的输出动作。
78.步骤五、仿真环境根据策略神经网络所输出的这个动作进行位置和状态更新,并计算执行该动作所获得的奖励。考虑到追逐者和逃跑者在完成“追逐”或“逃跑”这个最高层级的任务时,需要完成一些底层的目标,如避免与其他的追逐者逃避者、与环境边界、与障碍物的距离过近等。基于这些考虑,本方法将追逐者和逃避者的奖励均设计为复合奖励函数。
79.针对智能体的位置更新过程如下。
80.追逐者:追逐者的运动学模型为,追逐者的最大速率为v
p
,受到最大角速度的约束限制,最大角速度为ω
p
;追逐者的离散动作空间为,追逐者的速度离散为m
p
个选项,角速度离散为n
p
个选项,对可选的速度和角速度进行排列组合,得到m
p
×np
个选项。神经网络的输出为0~(m
p
×np-1)的整数值,将其按照此前规定的m
p
×np
个选项进行索引映射,得到具体选择的速率v
p
′
和具体选择的角速度ω
p
′
,位置更新按照如下公式进行更新:
81.θ
new
=θ
old
+dt
×
ω
p
′
82.x
new
=x
old
+v
p
′
×
cos(θ
new
)
×
dt
83.y
new
=y
old
+v
p
′
×
sin(θ
new
)
×
dt
84.逃跑者:逃跑者的运动学模型,逃跑者的最大速率为ve,不受最大角速度的限制,其朝向角可以瞬间改变,角度变化范围为-π~π;逃跑者的离散动作空间为,逃跑者的速度离散为me个选项,角度变化范围-π~π离散为ne个选项,对可选的速度和角度改变量进行排列组合,得到me×
ne个选项。神经网络的输出为0~(me×
ne)的整数值,将其按照此前规定的me×
ne个动作选项进行索引映射,得到具体选择的速率ve′
和具体选择的角度改变量dθ,位置更新按照如下公式进行更新:
85.θ
new
=θ
old
+dθ
86.x
new
=x
old
+ve′
×
cos(θ
new
)
×
dt
87.y
new
=y
old
+ve′
×
sin(θ
new
)
×
dt
88.需要说明的是,如果智能体发生碰撞,则认为其已经“死亡”,其速度保持为0,并且不对其进行位置更新。本方法对所有目标的观测信息按照两者之间的距离,以从小到大的顺序进行排序,增加观测值的规范化,便于神经网络的学习。
89.计算执行该动作所获得的奖励具体包括如下两部分。
90.首先,对追逐者i而言,它的奖励ri的计算如下:
91.(1.1)与障碍物距离的惩罚:计算追逐者i与障碍物j的距离,将d
i,j
定义为追逐者i的圆心与障碍物j圆心的距离减去两者的半径大小。追逐者i与所有障碍物的惩罚为:
[0092][0093]
其中,k为环境中障碍物的总数。
[0094]
(1.2)与环境边界距离的惩罚:
[0095]
计算追逐者i与环境边界的距离,记为d
wall
。追逐者i与环境边界距离的惩罚奖励为:
[0096][0097]
(1.3)与同类距离的惩罚:
[0098]
计算追逐者i与其他追逐者j的距离,记为d
i,j
。追逐者i与其他同类的追逐者距离的惩罚为:
[0099][0100]
(1.4)与逃避者距离的奖励:
[0101]
计算追逐者i与逃避者j的距离,将d
i,j
定义为追逐者i的圆心与逃避者j圆心的距离减去两者的半径大小。计算如下两个奖励:
[0102]
r1=ratio
dangerous
×
max(dangerous
d-d
i,j
,0),
[0103][0104]
如果逃避者j的速度为0,并且追逐者i与其的距离大于constrainedd,则r
i,j
=r1,否则r
i,j
=r1+r2。
[0105]
(1.5)追逐者i与所有逃避者的距离奖励为:
[0106][0107]
经过上述(1.1)-(1.5)步骤,最终得到追逐者i的总奖励为:
[0108][0109]
其次,对逃跑者i而言,它的奖励ri的计算如下:
[0110]
(2.1)与障碍物距离的惩罚:计算逃跑者i与障碍物j的距离,将d
i,j
定义为逃跑者i的圆心与障碍物j圆心的距离减去两者的半径大小。逃跑者i与所有障碍物的惩罚为:
[0111][0112]
其中,k为环境中障碍物的总数。
[0113]
(2.2)与环境边界距离的惩罚:计算逃跑者i与环境边界的距离,记为d
wall
。逃跑者i与环境边界距离的惩罚奖励为:
[0114][0115]
(2.3)与同类距离的惩罚:计算逃跑者i与其他逃跑者j的距离,记为d
i,j
。逃跑者i与其他同类的逃跑者距离的惩罚为:
[0116][0117]
(2.4)与追逐者距离的奖励:计算逃跑者i与追逐者j的距离,将d
i,j
定义为逃跑者i的圆心与追逐者j圆心的距离减去两者的半径大小。
[0118][0119]
(2.5)逃跑者i与所有追逐者的距离奖励为:
[0120][0121]
经过上述步骤(2.1)-(2.5),最终得到逃跑者i的总奖励为:
[0122][0123]
对于多个智能体的任务而言,对所有的智能体训练一个全局最优的联合动作十分困难,同时,由于所有追逐者的属性相同,结构相同,并且他们的目标均为“围捕逃跑者”,我们可以想到将所有追逐者共享同一个围捕策略,同理所有逃跑者也共享同一个逃跑策略。另外,由于追逐者集群内部和逃跑者集群内部为合作的关系,所以对于每一个追逐者或者逃跑者而言,他们实际获得的奖励是集群内部奖励的平均值(集群奖励总和/集群个体数目)。
[0124]
步骤六、将步骤四-步骤五的决策过程存储到经验收集池中。
[0125]
6.1、初始化,为充分利用计算机资源进行训练数据的收集与策略交互,开辟n
rollout
个线程进行训练过程中的策略交互和数据收集。环境的初始化是在每个线程内都创建一个单独的仿真环境,同时,为了避免每个线程之间的策略交互和数据收集的一致性,对每个线程的环境设置不同的随机种子,其中每个环境的初始化均按照如下规则生成:
[0126]
追逐者,在半径为r的环境内随机生成n
pursuer
个追逐者,追逐者分布位置随机,半径大小固定,朝向角随机;
[0127]
逃跑者,在半径为r的环境内随机生成n
evader
个逃跑者,逃跑者分布位置随机,半径大小固定,朝向角随机;
[0128]
障碍物:在半径为r的环境内随机生成n
obs
个障碍物,障碍物的分布位置随机,半径大小在一定的范围内随机。
[0129]
在初始化时,需要注意追逐者、逃跑者和障碍物之间维持一个初始的安全距离,避免在初始化的时候发生位置重叠导致碰撞使得策略与环境的交互步骤过短,导致收集不到有效的交互数据。
[0130]
6.2策略交互
[0131]
记录当前追逐者的策略网络为记录当前逃跑者的策略网络为使用当前追逐者和逃跑者的策略与仿真环境进行交互n
length
步,由于追逐者和逃跑者内部为策略参数共享,所以可以将不同的追逐者视为“并行的”经验收集器,将每一步收集到的马尔可夫决策过程(s
t
,a
t
,r
t
,s
t+1
)分别存储到追逐者、逃跑者各自内部共享的经验存储池当中,具体的示意图如图1所示。
[0132]
本方法以ippo算法为例,对多机器人围捕多目标的分布式决策方法的策略训练部
分进行说明。
[0133]
根据前述的策略交互过程,我们在追逐者的经验池中收集到n
rollout
×nlength
×npursuer
步追逐者的马尔可夫决策过程,也在逃跑者的经验池中收集到了n
rollout
×nlength
×nevader
步逃跑者的马尔可夫决策过程,对其中的每一个追逐者/逃跑者的长度为n
length
的马尔可夫决策链,我们估计其最后一个状态的状态价值。例如,对于某一个追逐者与环境交互了n
length
步,得到的马尔可夫奖励过程为(s0,a0,r0,s1,a1,r1,s2,...,sn),我们使用ippo算法中的critic网络对最后一个状态sn进行评估,得到状态价值记为v(sn)。随后,我们以最后一个状态的估计状态价值v(sn)倒推计算n
length
步决策过程中每一个状态的回报值。然后我们分别从追逐者和逃跑者的经验回放池中随机进行采样,获得训练样本,然后分别对actor神经网络和critic神经网络进行更新。
[0134]
步骤七、重复步骤二-步骤六的多智能体与环境的交互,直到达到单轮最大的仿真时间。
[0135]
步骤八、根据追逐者和逃避者经验存储器中各自存储的交互信息,使用多智能体强化学习ippo算法对分别对追逐者的追逐策略和逃避者的逃逸策略进行训练。通过不断进行策略神经网络与仿真环境的交互,并从交互得到的数据中进行学习,以进行策略训练。
[0136]
这里的交互信息指的是步骤二到步骤五所产生的数据,具体而言,在某一时间步t,某个机器人的状态/观测值为s
t
,该状态下的可行动作集合为a
t
,将状态s
t
和可行动作集合a
t
输入到机器人的策略网络π
θ
,从输出的动作概率分布中采样获得动作a
t
,机器人在环境中执行该动作a
t
,机器人取得奖励r
t
并转移到下一个状态s
t+1
,这一步的交互过程得到的信息为(s
t
,a
t
,r
t
,s
t+1
),然后将其存入追逐者或逃避者的经验收集池中。
[0137]
在步骤八中的使用多智能体强化学习ippo算法指的是通过ippo算法来优化机器人策略网络的参数θ以获得更好的策略。
[0138]
步骤九、重复步骤一-步骤八,重复迭代,直到达到最大的交互训练轮数。通过上述进行多次训练提升抓捕的协调配合的智能度。
[0139]
下面利用本方法结合具体进行实验。实验场景设计:我们将智能体的速度和场景半径同比例缩小,在仿真实验中,设计仿真环境的半径为5m,追逐者(蓝色圆球)的半径为0.1m,逃避者(红色圆球)的半径为0.2m,障碍物(黑色圆球)的半径为0.5m。
[0140]
实验智能体数目:为了验证本算法在智能体集群中的分布式决策效果,我们将智能体的数目设定为28个,其中,24个追逐者,4个逃避者,环境中随机分布的障碍物数目为6个。
[0141]
实验效果:我们将训练了21720800步仿真交互数据之后的智能体actor模型取出进行实验验证,具备相当智能性的逃避者均能够被追逐者所围捕,并且双方均没有发生碰撞,仿真示例如图3所示,实验结果证明了本方法的可行性和卓越性。
[0142]
近些年来将强化学习应用于追逃问题的相关研究大多没有考虑运动学模型,并且逃跑者的数目只有一个,场景中也大多不存在障碍物信息,无法适用于复杂环境(如复杂的运动学模型、场景中的随机障碍物等)。在本方法中,我们将逃避者的数目增多,即本方法能够将目标分配策略和目标导航避碰运动策略同时进行解算,所有的智能体都受到unicycle的运动学约束,环境中存在着随机分布的障碍物,经过实验验证,本方法能够解决此复杂环境的集群追逃问题。
[0143]
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1