一种融合历史信息的强化学习路径规划方法
1.本发明涉及机器人路径规划技术领域,具体涉及一种融合历史信息的强化学习路径规划方法。
背景技术:
2.近年来,移动机器人在各种行业得到了广泛的应用,同时对移动机器人性能的要求也在不断提高。移动机器人中的路径规划问题是实现移动机器人功能的关键技术。路径规划是根据人为定义的某一性能指标,获得机器人从初始位置到达目标位置的最优运动路径。像人工势场法、蚁群算法、可视图法等传统的路径规划算法大都存在实时性不高、容易陷入局部最优等缺点。因强化学习算法不需要环境模型,可以在未知环境中通过智能体不断与环境交互寻找最优路径,这使得强化学习算法越来越多的被应用在移动机器人路径规划领域。
3.在移动机器人路径规划领域应用最为广泛的强化学习算法是q-learning算法。q-learning算法是强化学习中基于值的算法,对于给定的状态动作对(s,a),都会有相应的值函数q(s,a)与之对应,环境会根据智能体所采取的动作给与奖励r,以此来更新q值。算法的主要思想就是将状态和动作构建成一张q表来存储q值,然后根据q值来选取能够获得最大收益的动作。q-learning算法的迭代就是一个试错和探索的过程,其收敛的条件是保证智能体对每一个状态动作对都进行足够多次的尝试,智能体才能最终学习到最优的策略。当把q-learning算法应用于移动机器人路径规划时,如何减少无效的探索,加快智能体的收敛速度,提高算法效率是当前研究的热点。
技术实现要素:
4.为了提高q-learning算法应用于移动机器人路径规划时的学习速度,本发明提出一种融合历史信息的强化学习路径规划方法,在状态空间中引入智能体的上一个历史状态来反映环境变化特征,在智能体动作选择之前,动态调整动作空间,禁止智能体重复返回上一位置,减少无效探索,提高算法的探索效率,缩短路径规划时间。
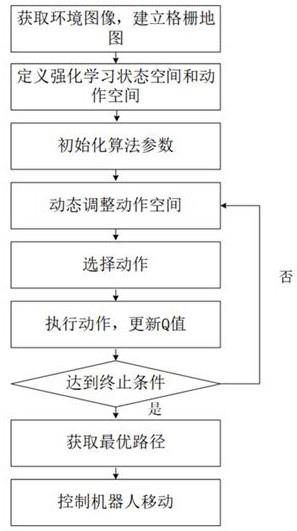
5.本发明提供的一种融合历史信息的强化学习路径规划方法,包括以下步骤:s1:获取环境图像,建立格栅地图;s2:定义强化学习状态空间和动作空间;s3:初始化算法参数;s4:动态调整动作空间;s5:在调整后的动作空间中,采用ε-贪婪策略选择动作;s6:执行动作,更新q值;s7:复执行第四步、第五步、第六步,直到达到一定步数或一定收敛条件为止;s8:每一步选择q值最大的动作,得出最优路径;s9:把最优路径发送给移动机器人的控制器,控制移动机器人按照最优行走。
6.进一步的,所述步骤s1的具体操作如下:基于移动机器人所搭载的摄像头获得环境图像,并将图像分割成20
×
20的栅格,采用栅格法建立环境模型,如果在格栅中发现障碍物,则定义该栅格为障碍物位置,机器人不能经过;如果格栅中发现目标点,则定于该格栅为目标位置,为移动机器人最终要到达的位置;其他的栅格定义为无障碍物的栅格,机器人可以经过。
7.进一步的,所述步骤s2的具体操作如下:定义强化学习的状态空间为智能体的当前位置坐标和上一位置坐标,动作空间为上、下、左、右四个方向的动作,每次执行动作之后智能体朝相应的方向移动一个栅格。
8.进一步的,所述步骤s3中的算法参数包括学习率
ɑ
∈(0,1),折扣因子γ∈(0,1),贪婪因子ε∈(0,1),最大迭代次数,奖赏函数r;把所有q值初始化为0,并随机给定一个动作,执行该动作到达下一状态。
9.进一步的,所述步骤s4中的动态调整动作空间为若上一步动作为上,则动作空间调整为{上,左,右};若上一步动作为下,则动作空间调整为{下,左,右};若上一步动作是左,则动作空间调整为{上,下,左};若上一步动作是右,则动作空间调整为{上,下,右}。
10.进一步的,所述步骤s6的具体操作如下:执行步骤s5所选择的动作a,到达s,得到即时奖励r(s,a),更新q值函数,更新规则如式(1)(1)其中,(s,a)为当前状态-动作对,(s
,
,a
,
)为下一时刻的状态-动作对,r(s,a)为状态s下执行动作a的即时奖励。
11.本发明的有益效果:本发明针对传统的q-learning算法应用于移动机器人路径规划问题时的收敛速度慢,运行效率低等问题,提出一种融合历史信息的改进q-learning算法,把状态空间定义为智能体的当前位置坐标和上一位置坐标,来反映位置的变化特征;在智能体选择动作之前,动态调整动作空间,禁止智能体重复返回上一位置,减少无效探索。将改进后的算法应用于移动机器人的路径规划问题,结果证明算法的可行性。基于格栅地图的仿真结果表明,改进的q-learning算法在应用于移动机器人路径规划问题时,规划时间缩短25.93%,收敛前的运行步数减少26.29%,提高了算法效率。
附图说明
12.为了更清楚地说明本技术实施例的技术方案,下面将对本技术实施例中所需要使用的附图做简单的介绍,显而易见地,下面所描述的附图仅仅是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下还可以根据这些附图获得其他的附图。
13.图1为本发明所述方法总体流程示意图。
14.图2为本发明实施例的移动机器人运行格栅地图。
15.图3为传统q-learning收敛情况图。
16.图4为本发明实施例的改进q-learning收敛情况图。
17.图5为本发明实施例的改进q-learning规划出的最优路径图。
具体实施方式
18.下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。
19.参阅图1,本发明提供的一种融合历史信息的强化学习路径规划方法,其方法步骤如下所述:第一步:基于移动机器人所搭载的摄像头获得环境图像,并将图像分割成20
×
20的栅格,采用栅格法建立环境模型,本实施例中的格栅地图如图2所示,如果在格栅中发现障碍物,则定义该栅格为障碍物位置,机器人不能经过;如果格栅中发现目标点,则定于该格栅为目标位置,为移动机器人最终要到达的位置;其他的栅格定义为无障碍物的栅格,机器人可以经过。
20.第二步:定义强化学习的状态空间为智能体的当前位置坐标和上一位置坐标,动作空间为上、下、左、右四个方向的动作,每次执行动作之后智能体朝相应的方向移动一个栅格。
21.第三步:初始化算法参数包括:学习率
ɑ
∈(0,1),折扣因子γ∈(0,1),贪婪因子ε∈(0,1),最大迭代次数,奖赏函数r。把所有q值初始化为0,并随机给定一个动作,执行该动作到达下一状态。
22.在本实施例中,学习率
ɑ = 0.01,折扣因子γ = 0.9,贪婪因子ε=0.2,最大迭代次数设置为3000次,奖励函数设置为:第四步:动态调整动作空间若上一步动作为上,则动作空间调整为{上,左,右};若上一步动作为下,则动作空间调整为{下,左,右};若上一步动作是左,则动作空间调整为{上,下,左};若上一步动作是右,则动作空间调整为{上,下,右}。
23.第五步:在调整后的动作空间中,采用ε-贪婪策略选择动作,保证智能体不再重复返回上一位置,减少无效探索。
24.第六步:执行第三步所选择的动作a
,
到达s
,
,得到即时奖励r(s,a),更新q值函数,更新规则如式(1)。
25.(1)其中,(s,a)为当前状态-动作对,(s
,
,a
,
)为下一时刻的状态-动作对,r(s,a)为状态s下执行动作a的即时奖励。
26.重复执行第四步、第五步、第六步,直到达到一定步数或一定收敛条件为止。
27.第七步:每一步选择q值最大的动作,得出最优路径。
28.第八步:把最优路径发送给移动机器人的控制器,控制移动机器人按照最优行走。
29.在本实施例中,我们利用上述方法,通过上述参数设置,可得到最优路径如图5所示。
30.图4为本发明实施例的改进q-learning收敛情况图。通过和图3的传统q-learning收敛情况图相比,本实施例的融合历史信息的强化学习路径规划方法使得收敛时间缩短25.93%,迭代次数减少26.29%,提高了算法效率。
31.需要注意的是,除非另有说明,本技术使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1