一种知识与数据协同驱动的无人机机动决策方法与系统
1.本发明属于无人机技术领域,具体涉及一种知识与数据协同驱动的无人机机动决策方法与系统。
背景技术:
2.无人机由于造价相对低廉、机动性好、安全系数高,已广泛应用于地质勘探、巡检、航拍等民用领域,同时也越来越多地被应用于侦察监视、预警、电子对抗等军事领域,在现代战争中发挥着越来越难以替代的作用。其中研究较多的便是无人机机动决策,即根据当前空战态势,自动生成合适的机动动作。但由于智能化水平的限制,目前仍无法实现无人机自主决策。因此,提升无人机的智能化水平,让无人机实现空战态势到机动动作的映射是当前主要的研究方向。
3.当前,无人机机动决策方法有很多。常用的方法可分为以下三类:基于对策理论的方法,如微分对策,矩阵对策等;基于专家知识的方法,如专家系统,影响图等;基于启发式学习的方法,如神经网络,遗传算法,强化学习等。其中,基于对策理论的方法求解复杂性较高,基于专家知识的方法难以对新知识进行扩展,且这两种方法的决策策略一般是固定的,无法满足复杂且瞬时变化的空战环境。基于启发式学习的方法在训练过程中优化自身模型的结构和参数,自适应性强,能够应对复杂多变的空战环境,其中深度强化学习方法通过与环境进行交互实时更新参数,选出的动作具有较强的合理性和实时性,能够更好地解决空战决策问题。但该方法仍存在数据利用率低,探索与利用的矛盾等问题。
技术实现要素:
4.发明目的:本发明为了解决无人机机动决策问题,提出一种知识与数据协同驱动的无人机机动决策方法与系统,能够解决基于强化学习的机动决策中数据利用率低,探索与利用的矛盾等问题,通过专家知识进行预训练,加快收敛速度,同时改进探索策略,构建结合专家知识的动作决策方法,从而将专家知识引入到强化学习中,减少智能体与环境的交互,提升智能体的学习性能。
5.技术方案:本发明所述的一种知识与数据协同驱动的无人机机动决策方法,包括以下步骤:
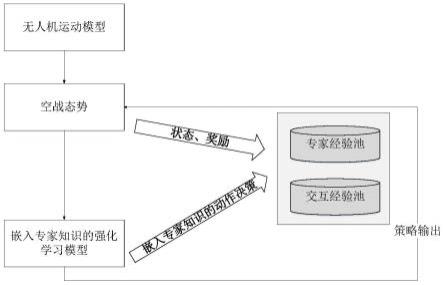
6.建立无人机运动模型及作战双方的相对关系,构建空战机动决策的马尔科夫博弈模型,定义空战机动决策过程中无人机的状态空间、动作空间以及奖励函数;
7.初始化作战双方的相对态势,初始化强化学习模型的价值q网络参数、交互经验池、专家经验池以及用于实现探索的参数;
8.在预训练阶段,我方无人机只与专家经验池进行交互,预训练损失函数定义为单步损失函数、多步损失函数、监督损失函数和网络参数正则化损失的加权和;
9.在正式训练阶段,我方无人机开始与环境进行交互,动态更新交互经验池,针对专家经验池无法包含空战过程中所有状态的问题,使用行为克隆模型对专家经验池中的数据
进行训练,得到状态到动作的映射;从专家经验池与交互经验池中随机抽取数据,根据空战状态、探索参数选择动作并执行,如果抽取的数据为专家经验池中数据,则损失函数与预训练损失函数计算方式相同,如果抽取到的数据为交互经验池中数据,则不计算损失函数中的监督损失函数。
10.作为优选,无人机在地面坐标系下的三维空间运动学模型如下:
[0011][0012]
无人机在地面坐标系下的三维空间动力学模型如下:
[0013][0014]
其中,x、y和z分别表示无人机在地面坐标系中的坐标值,v表示无人机的行进速度,θ、ψ分别表示无人机的俯仰角和偏航角;g表示重力加速度;度,θ、ψ分别表示无人机的俯仰角和偏航角;g表示重力加速度;分别表示x、y、z对时间t求微分,n
x
为无人机的切向过载;nz为无人机的法向过载;μ是无人机的滚转角。
[0015]
作为优选,空战过程中对敌双方的相对关系用态势来表示,包括:角度态势,高度态势,速度态势和距离态势;角度态势包括脱离角和偏离角,高度态势为红方和蓝方的高度以及最佳空战高度的关系,速度态势为红方和蓝方的速度以及最佳空战速度的关系,距离态势为红方和蓝方的距离。
[0016]
作为优选,将空战机动决策过程建模为马尔科夫博弈模型,确定双方的状态空间、动作空间以及奖励函数,用元组(s,a,γ,r)表示,s,a,γ,r分别为状态空间,动作空间,折扣因子和奖励函数;其中将状态空间包括双方的速度、位置、俯仰角和偏航角,动作空间包括定常飞行、加速飞行、减速飞行、左转弯、右转弯、向上拉起和向下俯冲;奖励函数包括即时奖励和最终奖励,即时奖励包括角度态势、高度态势、速度态势和距离态势的奖励,最终奖励是指一方获胜、平局或失败获得的奖励。
[0017]
作为优选,以红方为例相关奖励的定义如下:综合偏离角ata和脱离角aa的角度奖励定义为:
[0018][0019]
在高度奖励函数中引入一个校正量,校正后的高度奖励定义为:
[0020]
[0021][0022]
式中,是红方速度在竖直方向上的分量,h0是一个常数参量,用来调整高度奖励函数的梯度,h
opt
是最佳空战高度,zr,zb是红方和蓝方高度,v
opt
是最佳空战速度;
[0023]
速度奖励定义为:rv=r'v+r
v_self
[0024]
当v
opt
>1.5vb时
[0025][0026]
当v
opt
≤1.5vb时
[0027][0028]
vr,vb是红方和蓝方速度;
[0029][0030]
距离奖励定义为:
[0031][0032]dopt
为最佳空战距离,d0是一个常数参量,用来调整距离奖励函数的梯度,d是红方和蓝方的距离。
[0033]
作为优选,预训练损失函数表示为:
[0034]
j(q)=j
dq
(q)+λ1jn(q)+λ2je(q)+λ3j
l2
(q)
[0035]
式中,λ1、λ2和λ3为分别为n步损失函数jn(q)、监督损失函数je(q)和l2正则化损失函数j
l2
(q)的权重参数;
[0036]
设专家经验池d
demo
中每条专家数据的格式为(s
t
,a
t
,r
t
,r
tn
,s
t+1
,done),分别表示t时刻的状态、动作、一步奖励值、n步奖励值(n≥2)以及回合是否结束;
[0037]
为使训练比较稳定,引入两个网络:价值q网络和目标q网络,二者的网络结构相
同,参数更新方式不同;价值q网络随着训练时刻进行参数更新,目标q网络每隔一段时间复制价值q网络的参数进行更新。
[0038]
单步损失函数j
dq
(q)定义如下:
[0039][0040]
式中,θ-为目标q网络参数,θ为价值q网络参数,γ为折扣因子,为t+1时刻的最佳动作;
[0041]
n步损失函数jn(q)定义如下:
[0042][0043]rtn
=r
t
+γr
t+1
+...+γ
n-1rt+n-1
[0044]
式中,n步奖励值r
tn
=r
t
+γr
t+1
+...+γ
n-1rt+n-1
,为t+n时刻的最佳动作;
[0045]
监督损失函数je(q)定义如下:
[0046][0047]
l(ae,a
t
)是边界损失,其恒大于等于0,ae是专家动作;
[0048]
l2正则化损失函数定义如下:
[0049][0050]
式中,w是价值q网络的权重参数。
[0051]
作为优选,正式训练阶段,构建行为克隆模型,对专家经验池中的数据进行训练,得到状态到动作的映射,从而对探索策略进行改进;改进探索策略的探索方法具体如下:如果随机数rand()<ε,在动作空间内随机选取动作;如果随机数ε≤rand()<δ,从行为克隆模型中选取当前状态对应最优的动作;如果随机数rand()>δ,选取最大q值对应的动作,ε和δ为预设的用于实现探索的参数。
[0052]
作为优选,正式训练阶段,从缓冲池中随机抽取数据,根据当前空战状态s
t
、探索参数ε和参数δ选择动作并执行;如果抽取的数据为专家知识,则损失函数为j(q),如果抽取到的数据为交互数据,则损失函数j(q)中的参数λ2=0;使用优化器进行价值q网络参数更新,在一段时间后,将其网络参数赋值给目标q网络进行目标q网络参数更新;重复上述步骤直到达到设定的正式训练次数。
[0053]
一种知识与数据协同驱动的无人机机动决策系统,包括:
[0054]
模型构建与初始化模块,用于建立无人机运动模型及作战双方的相对关系,构建空战机动决策的马尔科夫博弈模型,定义空战机动决策过程中无人机的状态空间、动作空间以及奖励函数;以及初始化对敌双方的相对态势,初始化强化学习的价值q网络参数、缓冲经验池、专家经验池以及用于实现探索的参数;
[0055]
预训练模块,用于与专家经验池进行交互,预训练损失函数定义为单步损失函数、多步损失函数、监督损失函数和网络参数正则化损失的加权和;
[0056]
以及,正式训练模块,用于开始与环境进行交互,动态更新交互经验池,针对专家经验池无法包含空战过程中所有状态的问题,使用行为克隆模型对专家经验池中的数据进
行训练,得到状态到动作的映射;从专家经验池与交互经验池中随机抽取数据,根据空战状态、探索参数选择动作并执行,如果抽取的数据为专家经验池中数据,则损失函数与预训练损失函数计算方式相同,如果抽取到的数据为交互经验池中数据,则不计算损失函数中的监督损失函数。
[0057]
一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的知识与数据协同驱动的无人机机动决策方法。
[0058]
有益效果:与现有技术相比,本发明具有如下优点:
[0059]
(1)本发明采用深度强化学习方法,使无人机在空战过程中实现自主决策,根据环境信息,敌方状态等选择无人机机动动作,使决策生成更加准确。
[0060]
(2)本发明将专家知识与强化学习相结合,利用专家知识进行预训练,通过设置n步损失函数同时使专家的价值传播到更早的状态,设置监督损失函数使专家经验池中不存在的动作价值较为合理,设置l2正则化损失函数防止网络过拟合,从而在预训练后获取较好的初始策略,能够改进基于强化学习的机动决策中数据利用率低的问题。
[0061]
(3)本发明改进探索策略,平衡专家知识与自学习策略,能够解决预训练的数据集无法包含全部空战状态的问题,同时改进基于强化学习的机动决策中存在的探索与利用的矛盾问题。
附图说明
[0062]
图1为本发明实施例的方法流程图。
[0063]
图2为本发明实施例的仿真实验效果图。
具体实施方式
[0064]
下面结合附图和具体实施例对本发明的具体实施方式进行详细描述。
[0065]
如图1所示,本发明实施例公开了一种知识与数据协同驱动的无人机机动决策方法,包括如下步骤:
[0066]
步骤1:建立无人机运动模型、作战双方的相对关系及博弈模型。本发明实施例中假定对敌双方无人机为我方和敌方,我方无人机为红机,敌方无人机为蓝机,建立无人机运动模型及相对关系,构建空战机动决策的马尔科夫博弈模型,定义空战机动决策过程中我方及敌方无人机的状态空间、动作空间以及奖励函数。具体包括如下:
[0067]
步骤1-1:建立无人机运动模型。构建以地面为参考系的三维空间,其中,x轴指向地面坐标系的正东方向,y轴指向正北方向,z轴指向垂直向上的方向;无人机在地面坐标系下的三维空间运动学模型如下:
[0068][0069]
无人机在地面坐标系下的三维空间动力学模型如下:
[0070][0071]
其中,x、y和z分别表示无人机在地面坐标系中的坐标值,v表示无人机的行进速度,θ、ψ分别表示无人机的俯仰角和偏航角;俯仰角是无人机的行进速度方向与水平面之间的夹角(向上为正,向下为负),偏航角是无人机的行进速度方向在水平面的投影与正东方之间的夹角(向右为正,向左为负),g表示重力加速度;分别表示x、y、z对时间t求微分,即(n
x
,nz,μ)为无人机的控制变量,其中,n
x
为无人机的切向过载,表示无人机在前进速度方向上受到的推力和自身重力的比值,可以改变无人机的速度大小;nz为无人机的法向过载,表示无人机收到的与其机身屏幕垂直且方向向上的过载,可以改变无人机的俯仰方向;μ是无人机的滚转角,表示无人机绕自身速度方向的夹角;因此通过(n
x
,nz,μ)的值控制无人机进行机动动作。
[0072]
则无人机状态更新公式如下:
[0073]st+1
=f(s
t
,a)
ꢀꢀꢀ
(3)
[0074]
其中,s
t
为无人机在当前时刻t的状态,s
t+1
为无人机在下一时刻t+1的状态,a为无人机执行的机动动作,f(
·
)为计算函数,为保证精度,一般使用龙格库塔方法进行解算。
[0075]
步骤1-2:确定空战过程中我方和敌方的相对关系。我方为红方,用下标r表示,敌方为蓝方,用下标b表示。空战过程中双方的相对关系一般用态势来表示,包括:角度态势,高度态势,速度态势和距离态势。角度态势主要是脱离角(aspect angle,aa)和偏离角(antenna train angle,ata),其计算公式如下,高度态势为我方和敌方的高度以及最佳空战高度的关系,速度态势为我方和敌方的速度以及最佳空战速度的关系,距离态势为我方和敌方的距离,其公式如下:
[0076][0077][0078][0079]
步骤1-3:构建空战机动决策的马尔科夫博弈模型,定义空战机动决策过程中我方及敌方无人机的状态空间、动作空间以及奖励函数;
[0080]
步骤1-3-1:将空战机动决策过程建模为马尔科夫博弈模型,确定双方的状态空间、动作空间以及奖励函数,用元组(s,a,γ,r)表示,分别为状态空间,动作空间,折扣因子和奖励函数;
[0081]
步骤1-3-2:结合无人机运动方程,将状态空间定义为:s={vr,xr,yr,zr,θr,ψr,vb,xb,yb,zb,θb,ψb};
[0082]
步骤1-3-3:使用美国nasa提出的基本空战机动集合,设定七种机动动作,分别为:定常飞行,加速飞行,减速飞行,左转弯,右转弯,向上拉起,向下俯冲;
[0083]
步骤1-3-4:设置奖励函数。奖励函数包括即时奖励和最终奖励两部分。即时奖励是指在对战过程中依据双方态势设定的奖励,一般分为角度态势、高度态势、速度态势和距离态势四个部分。最终奖励是指一方获胜、平局或失败获得的奖励。(下面均以红方为例);
[0084]
角度态势中影响最大的是偏离角ata和脱离角aa,综合二者的角度奖励定义为:
[0085][0086]
高度奖励函数定义为:
[0087][0088]
式中:h
opt
是最佳空战高度。在空战过程中,战机为了获胜有一定的概率下降到较低高度,此时有坠机风险。为了使战机具备在高度过低时自主纠正高度的能力,在高度奖励函数中引入一个校正量,校正后的高度奖励函数如下所示:
[0089][0090]
式中,是红方速度在竖直方向上的分量,h0是一个常数参量,用来调整高度奖励函数的梯度,当无人机高度较大时,校正量权重较小,奖励值对速度在竖直方向上的变化不敏感,即高度变化不敏感;当无人机高度较小时,校正量权重较大,奖励值对速度在竖直方向上的变化比较敏感,即高度变化比较敏感,无人机会增加高度获取更大的奖励,从而避免坠机的危险。
[0091]
速度奖励函数定义为:当v
opt
>1.5vb时
[0092][0093]
当v
opt
≤1.5vb时
[0094]
[0095]
式中:v
opt
是最佳空战速度。在空战过程中,战机的速度过小时会失速,有坠机的危险。为了使战机的速度保持在合适的数值,在速度奖励函数中引入一个约束,无人机速度约束的奖励如下所示:
[0096][0097]
式中,v
min
为最小空战速度,实验中取值为50。
[0098]
综合的速度奖励函数如下所示:
[0099]
rv=r'v+r
v_self
ꢀꢀꢀ
(13)
[0100]
距离奖励函数定义为:
[0101][0102]
式中,d
opt
为最佳空战距离,d0是一个常数参量,用来调整距离奖励函数的梯度。
[0103]
综合上述奖励函数,定义空战中红方战机的即时奖励为:
[0104]
r1=w1×
ra+w2×
rh+w3×
rv+w4×
rdꢀꢀꢀ
(15)
[0105]
式中,w1、w2、w3和w4为权重参数,其和为1。
[0106]
定义最终奖励需要先设定空战中红方获胜的条件:
[0107][0108]
式中,aa
max
为占据攻击优势时的最大脱离角,实验中取值为π/6;ata
max
为占据攻击优势时的最大偏离角,实验中取值为π/3。
[0109]
同理,当蓝方达到上述条件时,红方失败;设定最大步数来约束双方战机对抗的步数上限,双方每进行一步机动对抗,步数加1,达到最大步数时此次对抗视为平局,当某一方战机飞出限定空域边界时也视为平局。
[0110]
因此,定义空战中红方战机的最终奖励为:
[0111][0112]
式中,r
fin
为获胜时得到的最终奖励,实验中取值为30。
[0113]
综上,奖励函数如下所示:
[0114]
r=r1+r2ꢀꢀꢀ
(18)
[0115]
步骤2:构建基于知识的强化学习算法,利用专家知识改进探索策略。具体包括:
[0116]
步骤2-1:首先进行初始化,确定红方和蓝方的相对态势,设定双方的位置,速度等状态信息;初始化强化学习算法的价值q网络参数,初始化交互经验池d
replay
,用于保存探索交互得到的经验数据;初始化专家经验池d
demo
,用来存放包含n步奖励值的专家演示数据,总的缓冲经验池d包含d
replay
和d
demo
,初始化参数ε和参数δ,用于实现探索。
[0117]
步骤2-2:预训练阶段,此时缓冲池为专家经验池d
demo
,从经验池d
demo
中随机采样batch_size条专家数据,每条专家数据的格式为(s
t
,a
t
,r
t
,r
tn
,s
t+1
,done),分别表示t时刻的状态、动作、一步奖励值、n步奖励值(n≥2)和回合是否结束;为使训练比较稳定,引入两个网络:价值q网络和目标q网络,二者的网络结构相同,参数更新方式不同;价值q网络随着训练时刻进行参数更新,目标q网络每隔一段时间复制价值q网络的参数进行更新。
[0118]
单步损失函数j
dq
(q)定义如下:
[0119][0120]
式中,θ-为目标q网络参数,θ为价值q网络参数,γ为折扣因子,为t+1时刻的最佳动作;j
dq
(q)中的q是价值q网络的简写,jn(q)、je(q)、j
l2
(q)和j(q)中也是相同的含义。
[0121]
为了使专家的价值传播到更早的状态,从而更好地进行预训练,使用n步时序差分算法进行预训练,因此n步损失函数jn(q)定义如下:
[0122][0123]rtn
=r
t
+γr
t+1
+...+γ
n-1rt+n-1
ꢀꢀꢀ
(21)
[0124]
式中,r
tn
为n步的奖励值,为t+n时刻的最佳动作。
[0125]
为了对演示数据中未包含动作的价值进行约束,强制任何与专家动作ae不同的动作的价值小于专家动作的价值,使未包含动作的价值变为合理价值,监督损失函数je(q)定义如下:
[0126][0127]
l(ae,a
t
)是边界损失,其恒大于等于0,定义如下:
[0128][0129]
为了防止过拟合,使用l2正则化对网络参数进行约束,因此l2正则化损失函数j
l2
(q)定义如下:
[0130][0131]
式中,w是价值q网络的权重参数。
[0132]
损失函数如下:
[0133]
j(q)=j
dq
(q)+λ1jn(q)+λ2je(q)+λ3j
l2
(q)
ꢀꢀꢀ
(25)
[0134]
使用优化器进行价值q网络参数更新,在一段时间后,将其网络参数赋值给目标q网络进行目标q网络参数更新。重复上述步骤,直到仿真达到设定的预训练次数,定义为pre_episodes。
[0135]
步骤2-3:正式训练阶段,智能体开始与环境进行交互,缓冲区包含专家经验池d
demo
和交互经验池d
replay
。使用行为克隆模型对专家数据集进行训练,得到状态到动作的映射,用其改进探索策略,添加两个探索参数ε和δ。
[0136]
行为克隆模型从专家数据中进行学习,挖掘和模拟专家数据中的知识和经验。行为克隆模型通过建立一个状态到行动的映射来学习如何正确应对当前的状态,通过最小化
模型输出的动作a和专家在相同状态下的动作ae之间的差异来模拟专家知识。对于离散的动作空间,该问题可被视为一个多标签分类问题,行为克隆模型的学习过程通过最小化交叉熵损失来完成,如式所示
[0137]
l
bc
=h(a,ae|s)
ꢀꢀꢀ
(26)
[0138]
式中,h代表交叉熵损失函数,s为某一时刻的状态,a为该状态下模型输出的动作,ae为该状态下的专家动作。
[0139]
改进探索策略的探索方法具体如下:如果随机数rand()<ε,在动作空间内随机选取动作;如果随机数ε≤rand()<δ,从行为克隆模型中选取当前状态对应最优的动作;如果随机数rand()>δ,选取最大q值对应的动作。
[0140]
从缓冲池中随机抽取batch_size条数据,根据当前空战状态s
t
、参数ε和参数δ选择动作并执行,根据式(3)得到下一时刻的状态s
t+1
,根据式(18)获得当前时刻的一步奖励值r
t
,根据式(21)获得当前时刻的n步奖励值r
tn
。如果抽取的数据为专家知识,则损失函数为j(q)=j
dq
(q)+λ1jn(q)+λ2je(q)+λ3j
l2
(q),如果抽取到的数据为交互数据,则损失函数j(q)=j
dq
(q)+λ1jn(q)+λ3j
l2
(q)。计算网络的梯度值并使用优化器进行更新,重复上述步骤,直到仿真达到设定的正式训练次数,定义为episodes。
[0141]
具体实施例:研究设定我机和敌机的初始状态如表1所示:
[0142]
表1:双方起始状态
[0143][0144]
导弹的最大攻击距离为1000m;无人机最佳空战速度为200m/s,最佳空战高度为6000m,最佳空战距离为1000m。
[0145]
根据上述场景,设置决策周期t=0.25s,每次抽取样本数量batch_size=64,预训练10000个episode,正式训练5000个episode后的效果如图2所示。图中实线为我方轨迹,虚线为敌方轨迹,可以看出,我方在初始时刻开始靠近敌机,消除了距离劣势,进而向上爬升再下降,进而形成了对敌方的尾追优势,证明本发明提出的知识与数据协同驱动的无人机机动决策方法,通过训练能够让无人机完成自主决策。
[0146]
基于相同的发明构思,本发明实施例公开了一种知识与数据协同驱动的无人机机动决策系统,包括:模型构建与初始化模块,用于建立无人机运动模型及作战双方的相对关系,构建空战机动决策的马尔科夫博弈模型,定义空战机动决策过程中无人机的状态空间、动作空间以及奖励函数;以及初始化对敌双方的相对态势,初始化强化学习的价值q网络参数、缓冲经验池、专家经验池以及用于实现探索的参数;预训练模块,用于与专家经验池进行交互,预训练损失函数定义为单步损失函数、多步损失函数、监督损失函数和网络参数正则化损失的加权和;以及,正式训练模块,用于开始与环境进行交互,动态更新交互经验池,针对专家经验池无法包含空战过程中所有状态的问题,使用行为克隆模型对专家经验池中的数据进行训练,得到状态到动作的映射;从专家经验池与交互经验池中随机抽取数据,根据空战状态、探索参数选择动作并执行,如果抽取的数据为专家经验池中数据,则损失函数与预训练损失函数计算方式相同,如果抽取到的数据为交互经验池中数据,则不计算损失
函数中的监督损失函数。
[0147]
基于相同的发明构思,本发明实施例公开了一种计算机系统,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现所述的知识与数据协同驱动的无人机机动决策方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1