针对间歇过程容错控制的二维数据驱动型强化学习方法
1.本发明涉及信息技术技术领域,尤其涉及针对间歇过程容错控制的二维数据驱动型强化学习方法。
背景技术:
2.间歇过程作为我国两大主要生产方式之一,其应用涉及了诸多领域,在机械、五金和塑胶等行业均能看见间歇生产过程的身影。与连续过程不同,间歇过程具有“多重时变”的生产特性,“多”即多样产品,间歇过程在同一设备上切换生产不同的产品;“重”即重复运行,间歇过程生产同一产品的过程会重复进行;“时”即时段切换,间歇过程在同一批次生产产品会进行多种操作工序切换;“变”即“变换指标”,针对不同产品,间歇过程会在不同操作阶段具有不同的控制目标和控制方案。以上间歇过程所具有的特殊大范围非平稳运行特点决定了对间歇过程进行控制远要比对连续过程进行控制难,特别是现阶段现代生产过程中反映出了生产流程更智能高效、生产规模愈发庞大、生产设备更加精密复杂等特点,这使得间歇过程更容易受故障或干扰的影响。故障和干扰的存在会让系统变得更难控制,一味的忽略这些因素对系统控制非但可能达不到理想的控制效果,更可能造成不可逆的灾难性损失。此外,被控对象精确模型无法获取时,传统基于模型的控制方法会出现控制效果不好甚至完全失效的情况。因此,如何解决间歇过程精确数学模型无法获取情况下的容错控制问题值得深入研究。
技术实现要素:
3.鉴于现有技术的上述缺点、不足,本发明提供针对间歇过程容错控制的二维数据驱动型强化学习方法,其解决了现有技术中针对具有执行器故障的间歇过程的容错控制的问题。该方法基于强化学习里的q学习算法,凭借对间歇过程实际所产生的数据进行不断学习,得到最优的控制策略,最终达到良好的容错控制效果和跟踪性能。
4.为了达到上述目的,本发明采用的主要技术方案包括:
5.本发明实施例提供针对间歇过程容错控制的二维数据驱动型强化学习方法,包括以下步骤:
6.(1)结合迭代学习控制律在具有执行器故障的原系统状态空间模型基础上建立等价模型,所述等价模型是以跟踪误差和状态增量构成的变量作为状态、迭代更新律作为输入的2d-roesser增广状态空间模型,并根据所述2d-roesser增广状态空间模型提出二维性能指标;
7.(2)在2d-roesser增广状态空间模型的系统稳定性得到满足的条件下,给出关于二维值函数和二维q函数的定义,并构建相应的最优控制律和最优控制增益的表达式;
8.(3)在步骤(2)的基础上,给定能使2d-roesser增广状态空间模型的系统稳定的最初的控制增益k0,并收集数据θj(t,k)及ρ
j+1
(t,k),θj(t,k)及ρ
j+1
(t,k)分别是第j次迭代和第j+1次迭代在第t时刻所产生的包含2d-roesser增广状态空间模型的系统生产信息的数
据;
9.(4)在步骤(2)和步骤(3)的基础上,通过执行q学习更新最优控制增益k;
10.(5)在步骤(4)的基础上,如果达到迭代结束条件,则迭代结束,否则转步骤(4)继续迭代。
11.进一步地,所述步骤(1)中的2d-roesser增广状态空间模型为:
[0012][0013]
其中,xc(t+1,k)是原系统在t+1时刻第k-1批次到第k批次的状态增量,可用变量zh(t+1,k)表示,yc(t+1,k)是原系统在第t+1时刻第k批次的跟踪误差,可用变量zv(t,k+1)表示;xc(t,k)是原系统在t时刻第k-1批次到第k批次的状态增量,可用变量zh(t,k)表示,yc(t+1,k-1)是原系统在第t+1时刻第k-1批次的跟踪误差,可用变量zv(t,k)表示;r(t,k)是原系统在第t时刻第k批次的迭代更新律;第t时刻第k批次的迭代更新律;分别是与z(t,k)、α、z(t,k)维数相匹配的2d-roesser增广状态空间模型的系统矩阵,组成的{a,b,c}是原系统的系统矩阵,i是单位矩阵,里的0代表着相应维数的0矩阵;α是故障系数;z(t,k)作为2d-roesser增广状态空间模型在第t时刻第k批次的状态,r(t,k)作为2d-roesser增广状态空间模型在第t时刻第k批次的输入。
[0014]
进一步地,所述步骤(1)中基于2d-roesser增广状态空间模型提出的二维性能指标为:
[0015][0016]
其中,z(t+i,k+j)、r(t+i,k+j)分别是在第t-i时刻第k-j批次的状态、第t+i时刻第k-j批次的输入,z(t+i,k+j)
t
指的是矩阵z(t+i,k+j)的转置,r(t+i,k+j)
t
指的是矩阵r(t+i,k+j)的转置,i=0,1,...,∞;q、r是与状态z(t+i,k+j)、输入r(t+i,k+j)维数相匹配的正定矩阵。
[0017]
进一步地,所述步骤(2)中的二维值函数为:
[0018][0019]
其中,z(t,k)是在第t时刻第k批次的状态,r(t,k)是在第t时刻第k批次的输入,z(t,k)
t
指的是矩阵z(t,k)的转置,r(t,k)
t
指的是矩阵r(t,k)的转置,是对称的正定矩阵,同时,二维值函数满足以下条件:
[0020]
[0021]
j*是待实现的二维性能指标j。
[0022]
进一步地,所述步骤(2)中的二维q函数为:
[0023]
q*(z(t,k),r(t,k))=z(t,k)
t
qz(t,k)+r(t,k)
t
rr(t,k)+v*(z1(t,k)),
[0024]
其中,z(t,k)是在第t时刻第k批次的状态,r(t,k)是在第t时刻第k批次的输入,z(t,k)
t
指的是矩阵z(t,k)的转置,r(t,k)
t
指的是矩阵r(t,k)的转置,q、r是与状态z(t,k)、输入r(t,k)维数相匹配的正定矩阵,v*(z1(t,k))是在z1(t,k)状态下的值函数。
[0025]
进一步地,所述步骤(2)中最优控制律和最优控制增益的表达式分别为:
[0026]
r(t,k)=kz(t,k)=-(h
rr
)-1
(h
zr
)
t
z(t,k),
[0027]
k=-(h
rr
)-1
(h
zr
)
t
[0028]
其中,矩阵h
rr
,h
zr
分别是由二维值函数和二维q函数所推得的矩阵h的组成部分,(h
rr
)-1
指的是矩阵h
rr
的逆,(h
zr
)
t
指的是矩阵h
zr
的转置。
[0029]
进一步地,所述步骤(3)中让j=0,j是迭代指标。
[0030]
进一步地,在步骤(2)和步骤(3)的基础上,所述步骤(4)中通过执行q学习更新最优控制增益将根据以下公式进行:
[0031]
θj(t,k)l
j+1
=ρj(t,k),
[0032]
其中,θj(t,k)=[θ
1j
(t,k)θ
2j
(t,k)θ
3j
(t,k)],(t,k)],(t,k)],l
j+1
=[(vec(l
1j+1
))
t (vec(l
2j+1
))
t (vec(l
3j+1
))
t
]
t
,l
1j+1
=p
j+1
,l
2j+1
=h
zrj+1
;l
3j+1
=h
rrj+1-r,ρj(t,k)=z(t,k)
t
(q+(kj)
t
rkj)z(t,k),z(t,k)是在第t时刻第k批次的状态,r(t,k)是在第t时刻第k批次的输入,q、r是与状态z(t,k)、输入r(t,k)维数相匹配的正定矩阵,矩阵右上角带有t均指的是该矩阵的转置,p
j+1
是在第j+1次迭代所得到的p,矩阵h
rrj+1
,h
zrj+1
是由二维值函数和二维q函数所推得的矩阵h
j+1
的组成部分,j+1指的是第j+1次迭代,kj是第j次迭代所得到的控制增益。
[0033]
进一步地,所述步骤(4)中更新最优控制增益的公式为:k
j+1
=-(r+l
3j+1
)-1
(l
2j+1
)
t
,k
j+1
是第j+1次迭代所得到的控制增益,(r+l
3j+1
)-1
指的是矩阵(r+l
3j+1
)的逆,(l
2j+1
)
t
指的是矩阵l
2j+1
的转置。
[0034]
进一步地,所述步骤(5)中的迭代结束条件为:
[0035]
||k
j+1-kj||≤ε,ε>0,
[0036]
其中,ε是非常小的正整数,kj和k
j+1
分别是第j次和第j+1次迭代所产生的控制增益。
[0037]
本发明的有益效果是:本发明提出一种针对间歇过程容错控制的二维数据驱动型强化学习方法,与大多数在一维框架下进行的容错控制不同,本发明所提出的方法充分考虑了间歇过程在时间方向和批次方向上的特性,在二维框架下设计控制方法更贴合间歇过程的生产特性。此外,基于二维数据驱动型强化学习所设计出的容错控制方法有别于传统基于模型的容错控制方法,具有能够不需要获知系统精确的模型信息的优点,在获取系统精确模型信息较难或者获取成本过高时可以起到关键作用。由于是对系统在生产过程中所产生的信息进行最优控制律和最优控制增益的学习,而这些真实数据诞生并储存在间歇过程中,可以充分的反映出系统动态,进而也使得本发明所提出的这种方法具有更实用、更有
效的有益效果。在当前及此后的间歇过程控制问题中,本发明所提出的容错控制方法能够很好的替代传统基于模型的控制方法,使得系统不论是在系统正常的情况下还是系统具备执行器故障的情况下都能够达到期望的控制效果。在一定程度上起到节约成本的作用,更具使用价值,有利于维护间歇过程安全高效生产。
附图说明
[0038]
图1显示了本发明学习过程中矩阵kj收敛到矩阵k的情况;
[0039]
图2显示了本发明学习过程中矩阵hj收敛到矩阵h的情况;
[0040]
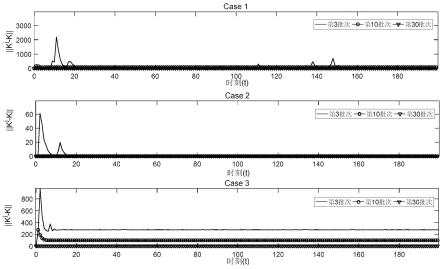
图3给出了本发明(2d q-learning)和传统基于模型的二维模型预测容错跟踪控制方法(2d mpftc)在case1(故障系数α=1)情况下各批次的输入对比图;
[0041]
图4给出了本发明(2d q-learning)和传统基于模型的二维模型预测容错跟踪控制方法(2d mpftc)在case2(故障系数α=0.4)情况下各批次的输入对比图;
[0042]
图5给出了本发明(2d q-learning)和传统基于模型的二维模型预测容错跟踪控制方法(2d mpftc)在case3(故障系数α=1.6)情况下各批次的输入对比图;
[0043]
图6给出了本发明(2d q-learning)和传统基于模型的二维模型预测容错跟踪控制方法(2d mpftc)在case1(故障系数α=1)情况下各批次的输出对比图;
[0044]
图7给出了本发明(2d q-learning)和传统基于模型的二维模型预测容错跟踪控制方法(2d mpftc)在case2(故障系数α=0.4)情况下各批次的输出对比图;
[0045]
图8给出了本发明(2d q-learning)和传统基于模型的二维模型预测容错跟踪控制方法(2d mpftc)在case3(故障系数α=1.6)情况下各批次的输出对比图;
[0046]
图9给出了本发明(2d q-learning)和传统基于模型的二维模型预测容错跟踪控制方法(2d mpftc)在case1(故障系数α=1)、case2(故障系数α=0.4)、case3(故障系数α=1.6)情况下的跟踪性能对比图。
具体实施方式
[0047]
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
[0048]
本发明提供一种针对间歇过程容错控制的二维数据驱动型强化学习方法。该方法能够使具有执行器故障的间歇过程摆脱对过去容错控制方法对精确模型的依赖性,填补传统基于模型控制方法无法应对系统精确模型未知的控制问题的缺口,具有良好的控制效果。其包括以下步骤:
[0049]
(1)结合迭代学习控制律在具有执行器故障的原系统状态空间模型基础上建立等价模型,该等价模型是以跟踪误差和状态增量构成的变量作为状态、迭代更新律作为输入的2d-roesser增广状态空间模型,并根据2d-roesser增广状态空间模型提出二维性能指标。
[0050]
其中,步骤(1)具体包括以下步骤:
[0051]
用u
if
(t,k),i=1,
…
,m代表故障执行器的输出信号,可以建立故障模型:u
if
(t,k)=αiui(t,k),i=1,2,
…
,m。其中,α=diag[α
1 α2,
…
,αm],α=diag[α
1 α2,
…
,αm],αi≤1,都是已知的常数,αi未知,但假设在一个已知的范围内变化。因此,会有uf(t,k)=αu(t,k)。如果对应着实际模型u
if
(t,k)=ui(t,k),此时意味着原系统处于执行器不发生故障的理想状况;如果αi=0,这对应着完全失效故障;如果αi>0,这对应着部分失效故障。
[0052]
因此,具有执行器故障的间歇过程原系统模型为:
[0053][0054]
其中,k代表的是间歇过程所在的批次,t为间歇过程在批次内所处的运行时刻,分别是原系统在第k批次的第t时刻的状态、输入和输出,是原系统在第k批次的第t+1时刻的状态,n,m,l是相应变量的维度,{a,b,c}是维数与状态、输入维数相对应的原系统矩阵。
[0055]
考虑设计迭代学习控制律u(t,k)=u(t,k-1)+r(t,k),其中,u(t,k),u(t,k-1)分别是原系统在第t时刻第k批次和第t时刻k-1时刻的输入,r(t,k)是迭代更新率。
[0056]
对于给定的期望输出轨迹yd(t,k),若原系统跟踪误差和沿批次方向的状态增量分别为yc(t,k)=yd(t,k)-y(t,k),xc(t+1,k)=x(t+1,k)-x(t+1,k-1),是原系统第k批次的第t时刻的输出,x(t+1,k),x(t+1,k-1)分别是原系统在第k批次的第t+1时刻的状态和原系统在第k-1批次的第t+1时刻的状态。由以上可得到与具有执行器故障的间歇过程原系统模型等价的2d-roesser增广状态空间模型:
[0057][0058]
其中,xc(t+1,k)是原系统在t+1时刻第k-1批次到第k批次的状态增量,可用变量zh(t+1,k)表示,yc(t+1,k)是原系统在第t+1时刻第k批次的跟踪误差,可用变量zv(t,k+1)表示;xc(t,k)是原系统在t时刻第k-1批次到第k批次的状态增量,可用变量zh(t,k)表示,yc(t+1,k-1)是原系统在第t+1时刻第k-1批次的跟踪误差,可用变量zv(t,k)表示;r(t,k)是原系统在第t时刻第k批次的迭代更新律;第t时刻第k批次的迭代更新律;分别是与z(t,k)、α、z(t,k)维数相匹配的2d-roesser增广状态空间模型的系统矩阵,组成的{a,b,c}是原系统的系统矩阵,i是单位矩阵,里的0代表着相应维数的0矩阵;α是故障系数;z(t,k)作为2d-roesser增广状态空间模型在第t时刻第k批次的状态,r(t,k)作为2d-roesser增广状态空间模型在第t时刻第k批次的输入。
[0059]
基于2d-roesser增广状态空间模型提出的二维性能指标函数为:
其中,z(t+i,k+j)、r(t+i,k+j)分别是在第t+i时刻第k+j批次的状态、第t+i时刻第k+j批次的输入,z(t+i,k+j)
t
指的是矩阵z(t+i,k+j)的转置,r(t+i,k+j)
t
指的是矩阵r(t+i,k+j)的转置,i=0,1,...,∞。q、r是与状态z(t+i,k+j)、输入r(t+i,k+j)维数相匹配的正定矩阵。
[0060]
本发明所提出的二维数据驱动强化学习方法能够找到一种最优控制律r(t,k)=kz(t,k),这种形式的控制律能够使二维性能指标j在控制律的作用下成为二维性能指标j*,从而使2d-roesser增广状态空间模型的系统的状态z(t+i,k+j)趋于0,并完成2d-roesser增广状态空间模型的系统输出y(t,k)对期望的输出轨迹的yd(t,k)跟踪。
[0061]
(2)在2d-roesser增广状态空间模型的系统稳定性得到满足的条件上给出关于二维值函数和二维q函数的一些定义,并构建相应的最优控制律和最优控制增益的表达式。
[0062]
二维值函数为:
[0063][0064]
其中,z(t,k)是在第t时刻第k批次的状态,r(t,k)是在第t时刻第k批次的输入,z(t,k)
t
指的是矩阵z(t,k)的转置,r(t,k)
t
指的是矩阵r(t,k)的转置,是对称的正定矩阵,同时,二维值函数满足条件:
[0065][0066]
其中,j*是待实现的二维性能指标j。
[0067]
二维q函数为:
[0068]
q*(z(t,k),r(t,k))=z(t,k)
t
qz(t,k)+r(t,k)
t
rr(t,k)+v*(z1(t,k))
[0069]
其中,z(t,k)是在第t时刻第k批次的状态,r(t,k)是在第t时刻第k批次的输入,z(t,k)
t
指的是矩阵z(t,k)的转置,r(t,k)
t
指的是矩阵r(t,k)的转置,q、r是与状态z(t,k)、输入r(t,k)维数相匹配的正定矩阵,v*(z1(t,k))是在z1(t,k)状态下的值函数。
[0070]
显然二维值函数和二维q函数有着关系:同时,控制律r(t,k)=kz(t,k)的作用下二维值函数和二维q函数都具有二次型的形式:v*(z(t,k))=z(t,k)
t
pz(t,k),其中,进而可以得到与最优控制律、最优控制增益的表达式r(t,k)=kz(t,k)=-(h
rr
)-1
(h
zr
)
t
z(t,k),k=-(h
rr
)-1
(h
zr
)
t
。矩阵h
rr
,h
zr
是由二维值函数和二维q函数所推得的矩阵h的组成部分,(h
rr
)-1
指的是矩阵h
rr
的逆,(h
zr
)
t
指的是矩阵h
zr
的转置。
[0071]
(3)在步骤(2)的基础上,给定能使2d-roesser增广状态空间模型的系统稳定的最初的控制增益k0,并收集数据θj(t,k)及ρ
j+1
(t,k),k0是最初的控制增益,θj(t,k)及ρ
j+1
(t,k)是第j次迭代t时刻所产生的包含2d-roesser增广状态空间模型的系统生产信息的数据。
[0072]
让j=0,j是迭代指标,给定能使2d-roesser增广状态空间模型的系统稳定的最初的控制增益k0;收集数据θj(t,k)及ρ
j+1
(t,k),θj(t,k)及ρ
j+1
(t,k)是第j次迭代所产生的包含2d-roesser增广状态空间模型的系统生产信息的数据。
[0073]
(4)在步骤(2)和步骤(3)的基础上,通过执行q学习更新最优控制增益k。
[0074]
将根据以下公式进行:
[0075]
θj(t,k)l
j+1
=ρj(t,k),
[0076]
用最小二乘法学习l
1j+1
到l
3j+1
,进而更新控制增益:
[0077]kj+1
=-(r+l
3j+1
)-1
(l
2j+1
)
t
,
[0078]
其中,k
j+1
是第j+1次迭代所得到的控制增益。
[0079]
引入了目标策略rj(t,k),由步骤(2)会有:
[0080][0081]
另外,会有rj(t,k)=kjz(t,k)。化简并结合克罗内克积得到θj(t,k)l
j+1
=ρj(t,k),其中:
[0082]
θj(t,k)=[θ
1j
(t,k) θ
2j
(t,k) θ
3j
(t,k)],
[0083][0084][0085][0086]
l
j+1
=[(vec(l
1j+1
))
t (vec(l
2j+1
))
t (vec(l
3j+1
))
t
]
t
,l
1j+1
=p
j+1
,l
2j+1
=h
zrj+1
,
[0087]
l
3j+1
=h
rrj+1-r,ρj(t,k)=z(t,k)
t
(q+(kj)
t
rkj)z(t,k)。
[0088]
z(t,k)是在第t时刻第k批次的状态,r(t,k)是在第t时刻第k批次的输入,q、r是与状态z(t,k)、输入r(t,k)维数相匹配的正定矩阵,矩阵右上角带有t均指的是该矩阵的转置,p
j+1
是在第j+1次迭代所得到的p,矩阵h
rrj+1
,h
zrj+1
是由二维值函数和二维q函数所推得的矩阵h
j+1
的组成部分,j+1指的是第j+1次迭代,kj是第j次迭代所得到的控制增益。
[0089]
(5)在步骤(4)的基础上,如果达到迭代结束条件,则迭代结束,否则转步骤(4)继续迭代。
[0090]
当||k
j+1-kj||≤ε,(ε是一个极小的正数)满足则迭代停止。否则令j=j+1,回到步骤(4)。kj和k
j+1
分别是第j次和第j+1次迭代所产生的控制增益。
[0091]
实施例1:
[0092]
本实施例采用注塑成型过程,塑料制品已经成为当代社会各行业生产和人类生活中不可或缺的元素。作为将树脂材料加工制成塑料制品的一种典型间歇过程,注塑成型过程在生产过程中扮演着重要的角色,在航空航天、芯片生产、汽车制造等诸多领域都能看见注塑成型过程的身影。保压阶段作为注塑成型过程的重要阶段之一,对塑料产品的最终质量有着极大的影响:注塑机通过阀门的开度去控制喷嘴的压力。阀门状态将会直接影响到
阀门开度,进而影响到喷嘴压力,压力最终会对塑料产品的密度造成关键影响:压力较大的区域,塑料产品相对密实;压力较小的区域,塑料产品相对疏松。事实上,在保压阶段,阀门可以视作执行器,执行器并不一定能够一直维持在正常的状态(α=1),很有可能发生执行器故障,最终执行器故障主要反映在两种情况:一是阀门过紧(α<1),二是阀门松动(α>1)。阀门过紧时的阀门开度将会比正常的阀门开度小,而阀门松动时则会造成相反的情况。保压阶段的喷嘴压力np和开度vo之间有如下关系:
[0093][0094]
算法具体步骤为:
[0095]
step1:当定义状态空间模型里的状态、输入和输出分别为:
[0096]
x(t,k)=[np(t,k)
ꢀ‑
0.3259np(t,k-1)
ꢀ‑
156.8vo(t,k-1)]
t
,u(t,k)=vo(t,k),y(t,k)=np(t,k)时,能够得到保压阶段的状态空间模型如下:
[0097][0098]
其中,x(t,k),u(t,k),y(t,k)分别是原系统在第k批次的第t时刻的状态、输入和输出,x(t+1,k)是原系统在第k批次的第t+1时刻的状态。结合迭代学习控制律在具有执行器故障的原系统状态空间模型基础上建立等价模型,该等价模型是以跟踪误差和状态增量构成的变量作为状态、迭代更新律作为输入的2d-roesser增广状态空间模型并选择控制器参数为r=1,设定期望输出值为yd=300,确定二维性能指标。
[0099]
step2:在2d-roesser增广状态空间模型的系统稳定性得到满足的条件上给出关于二维值函数和二维的q函数的一些定义,并构建相应的最优控制律和最优控制增益的表达式;
[0100]
r(t,k)=kz(t,k)=-(h
rr
)-1
(h
zr
)
t
z(t,k),k=-(h
rr
)-1
(h
zr
)
t
。
[0101]
其中,矩阵h
rr
,h
zr
是由二维值函数和二维q函数所推得的矩阵h的组成部分,(h
rr
)-1
指的是矩阵h
rr
的逆,(h
zr
)
t
指的是矩阵h
zr
的转置。
[0102]
step3:在步骤(2)的基础上,给定能使2d-roesser增广状态空间模型的系统稳定的最初的控制增益k0并收集数据θj(t,k)及ρ
j+1
(t,k),k0是最初的控制增益,θj(t,k)及ρ
j+1
(t,k)是第j次迭代t时刻所产生的包含2d-roesser增广状态空间模型的系统生产信息的数据。
[0103]
step4:在步骤(2)和步骤(3)的基础上,通过执行q学习更新最优控制增益k;
[0104]
将根据以下公式进行:
[0105]
θj(t,k)l
j+1
=ρj(t,k),
[0106]
其中,θj(t,k)=[θ
1j
(t,k) θ
2j
(t,k) θ
3j
(t,k)],
l
j+1
=[(vec(l
1j+1
))
t (vec(l
2j+1
))
t (vec(l
3j+1
))
t
]
t
,l
1j+1
=p
j+1
,l
2j+1
=h
zrj+1
;l
3j+1
=h
rrj+1-r,ρj(t,k)=z(t,k)
t
(q+(kj)
t
rkj)z(t,k),z(t,k)是在第t时刻第k批次的状态,r(t,k)是在第t时刻第k批次的输入,q、r是与状态z(t,k)、输入r(t,k)维数相匹配的正定矩阵,矩阵右上角带有t均指的是该矩阵的转置,p
j+1
是在第j+1次迭代所得到的p,矩阵h
rrj+1
,h
zrj+1
是由二维值函数和二维q函数所推得的矩阵h
j+1
的组成部分,j+1指的是第j+1次迭代,kj是第j次迭代所得到的控制增益。
[0107]
用最小二乘法学习l
1j+1
到l
3j+1
,进而更新控制增益:
[0108]kj+1
=-(r+l
3j+1
)-1
(l
2j+1
)
t
,
[0109]
其中,k
j+1
是第j+1次迭代所得到的控制增益,(r+l
3j+1
)-1
指的是矩阵(r+l
3j+1
)的逆,(l
2j+1
)
t
指的是矩阵l
2j+1
的转置。
[0110]
step5:在步骤(4)的基础上,如果达到迭代结束条件则迭代结束,否则转步骤(4)继续迭代。
[0111]
||k
j+1-kj||≤ε,ε>0,其中ε是非常小的正整数,kj和k
j+1
分别是第j次和第j+1次迭代所产生的控制增益。
[0112]
给定初始的h,进而得到初始的k0,通过学习最终获得的最优的矩阵h和最优的控制增益k分别为:
[0113]
case1:α=1
[0114]
k=[-0.0075,-0.0057,0.0030]
[0115]
case2:α=0.4
[0116]
k=[-0.0188,-0.0142,0.0074]
[0117]
case3:α=1.6
[0118]
k=[-0.0047
ꢀ‑
0.0035 0.0019]
[0119]
然后实现强化学习算法,经过多次学习之后,本发明提出来的容错控制方法所求出来的矩阵h和k逐渐收敛到最优的h以及最优的k。
[0120]
附图1到9分别显示了本实施例在仿真中得到的控制效果。通过对执行器的状态进行分类,考虑执行器处于正常情况(case1:α=1)、执行器故障情况(case2:α<1)和执行器故障(case3:α>1)情况这三种情况进行了仿真实验,分别选取了故障参数α为1、0.4、1.6。为了进一步直观的展示出本发明的学习效果,分别选取了第3批次、第10批次、第30批次的
数据进行了图像的绘制。此外,本发明所绘制的图像考虑了为输出位置添加了干扰的情况以证明算法的抗干扰性。图1展示了本发明在添加了噪声的情况下,面对三种不同的故障系数,矩阵kj是如何在学习过程中随着批次的增加最终逼近到最优的矩阵k的。图2反映了在添加了噪声的情况下,面对三种不同的故障系数,矩阵hj是如何在学习过程中随着批次的增加最终收敛到最优容错控制增益h的。图3-图5反映的是两种控制算法在不同执行器故障系数(case1、case2、case3)下第3、第10、第30批次的输入图像对比。三种情况下,输入曲线反映出一种共性:本发明的输入值在多数时间都会小于2d mpftc的输入值,这表明了本发明通过较小的输入就能实现良好的控制效果。同时,图像表明,无论是正常情况还是故障情况,本发明的控制输入的曲线都处于稳定的状态,使系统在故障情况下也能保持稳定生产。图6-图8反映的是两种控制算法在不同执行器故障系数(case1、case2、case3)下第3、第10、第30批次的输出图像对比。在case1时,很明显本发明和传统基于模型的2d mpftc的跟踪速度都随着批次的增加而加快,但最终本发明的输出能够先一步的跟踪上期望的输出轨迹。在case2和case3能够发现故障对传统基于模型的2d mpftc的输出跟踪速度有了较大的影响,使得其输出曲线到第10批次还未能在短时间内快速跟踪上期望输出轨迹,而本发明所受的影响不大,虽然在第3批次时未能快速的跟踪上,但到第10批次就已经实现了对期望输出轨迹的快速跟踪。图9对比的是两种控制方法面对三种不同的执行器故障系数(case1、case2、case3)的跟踪性能图像。随着批次的增加,跟踪性能曲线逐渐向0靠近,比较三种故障系数下两种算法的图像不难发现本发明的收敛速度更快,能够比更快的收敛到0。
[0121]
综上,本实施例以注塑过程为例,验证了本发明的控制效果有效性及可行性。本发明基于强化学习里的q学习理念,能够在系统信息获取成本较高时起到关键作用,使得控制成本的降低。在系统信息获取较难时也能突显出优异的控制效果,是应用范围广、控制效果好、跟踪速度快的有效控制方法,可以为当前及此后的间歇过程生产保驾护航,有助于注塑成型过程及其他间歇过程的顺利进行。
[0122]
最后应该说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,其可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1