一种基于Kmeans和SVM的无人机飞控参数组合测试方法
本发明涉及软件测试,具体为一种基于kmeans和svm的无人机飞控参数组合测试方法。
背景技术:
1、近些年武器装备系统迎来了快速发展期,系统的软硬件都变得越来越复杂。就软件而言,其结构和功能的复杂性显著增加,处理能力显著增强,软件中一个函数可同时处理的输入参数数量也随之增加,已多达十几甚至几十到上百个。这些输入参数相互耦合,相互依赖,关系非常复杂,一些微小的输入错误或偶然因素的影响就可能带来巨大的财产损失和严重的人员伤害,造成难以估计的后果。测试是减少损失、降低伤害且保证质量和可靠性的一种重要手段。
2、理论上对测试空间中的全部数据进行全因子测试才能保证全面性,然而测试空间中可能的测试数据举不胜举,无法在实际测试中应用。组合测试是一种科学有效的黑盒测试方法,可以使用较少的测试数据有效地检测待测系统中参数之间的相互作用产生的影响。组合测试可以使用较少的测试数据达到全因子测试的效果,因此,实际中常常使用组合测试代替全因子测试。
3、在实际的待测系统的参数数量和参数的取值个数往往较多,从十几个到几十个不等,而且参数之间的交互关系复杂。只覆盖两个或三个参数的取值组合,也就是覆盖力度为2或3,难以保证测试覆盖率。如果生成力度更大的测试数据,那么测试数据的规模将是非常大的,可以达到成千上万,甚至更多。有时执行一条测试数据的时间很长,量级在秒级,这样完全测试这些测试数据也是很难完成的。
技术实现思路
1、本发明的目的是:针对现有技术中无人机飞控参数的测试效率低的问题,提出一种基于kmeans和svm的无人机飞控参数组合测试方法。
2、本发明为了解决上述技术问题采取的技术方案是:
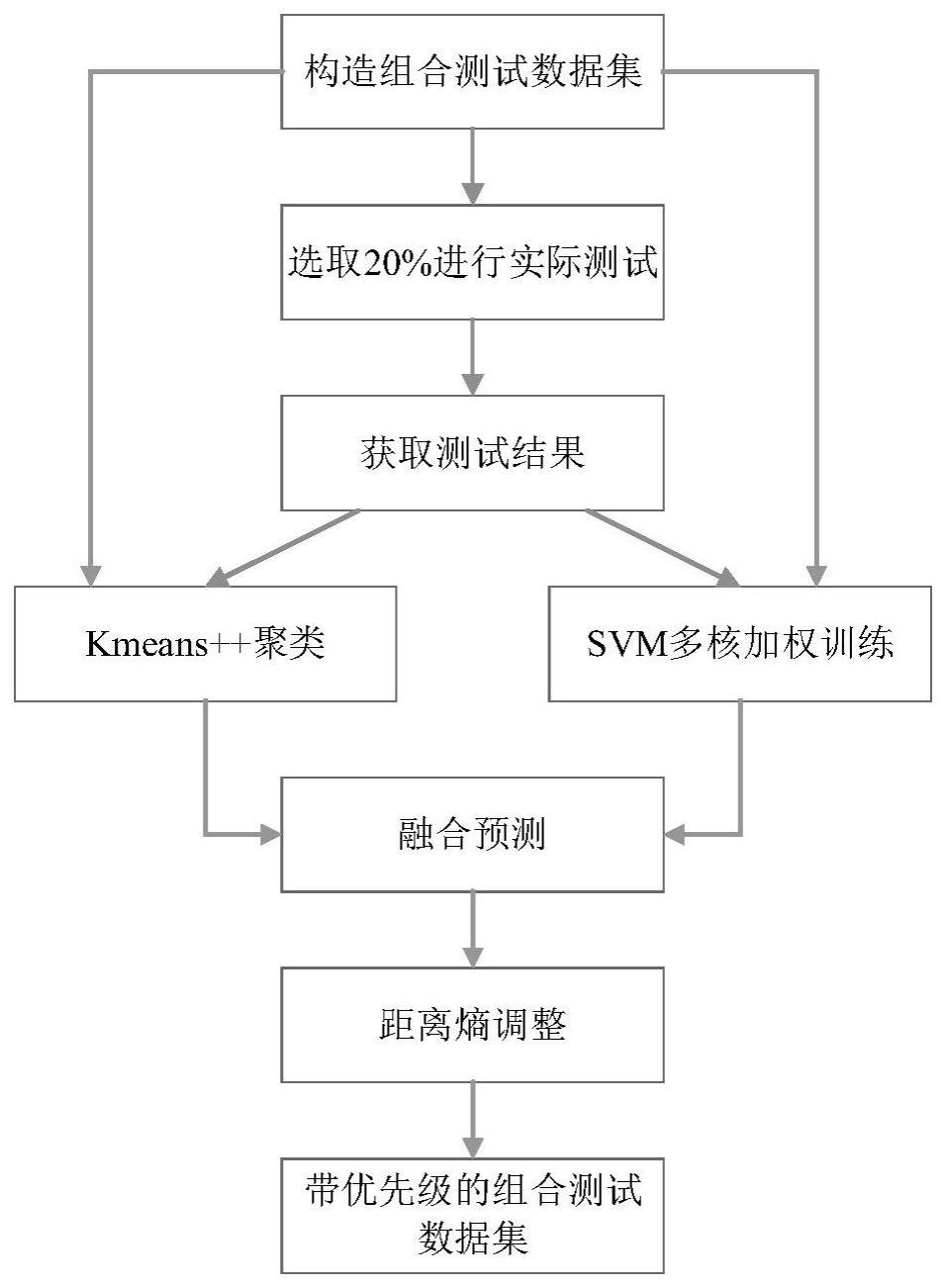
3、一种基于kmeans和svm的无人机飞控参数组合测试方法,包括以下步骤:
4、步骤一:无人机飞控计算机接收前端传感器选择的典型测试值,即测试数据集;
5、步骤二:在测试数据集中选择20%的数据作为前期小样本测试数据,并利用选择的前期小样本测试数据激励飞控计算机,得到飞控计算机的响应结果,并以前期小样本测试数据以及对应的响应结果作为训练数据分别训练kmeans和svm模型,kmeans将前期小样本测试数据聚类成两类,即有故障类和无故障类;
6、步骤三:分别利用kmeans和svm对测试数据集中的测试数据进行预测,并根据预测结果对测试数据进行优先级融合,按照融合后的优先级大小进行排序,针对优先级相同的测试数据,通过距离熵值调整优先级;最终输出带有优先级的测试数据;
7、步骤四:带有优先级的测试数据作为飞控计算机的激励用于最终的测试。
8、进一步的,所述测试数据集中每个测试数据基于贪心算法得到,具体步骤为:
9、步骤一一:以力度为2的参数取值组合为基础,并根据参数之间的相关性,通过力度为3和力度为4的参数取值组合,得到参数的取值集;
10、步骤一二:根据参数的每个取值在取值集中出现的次数,得到该参数的取值未覆盖度;
11、步骤一三:选取每个参数未覆盖度最大的取值构成一条测试数据;
12、步骤一四:利用取值集中的取值组合替换步骤三中测试数据对应的取值组合,若替换后能提高这条测试数据的覆盖能力,则保留替换后的测试数据,否则不替换,结束;
13、步骤五:将替换后的测试数据中覆盖的取值从取值集中移除,然后判断取值集是否为空,若取值集为空,则结束,若取值集不为空,则执行步骤二。
14、进一步的,所述kmeans为kmeans++,所述kmeans++对测试数据集中的测试数据进行预测的具体步骤为:
15、步骤1:假设n条测试数据集合为随机选取一条故障测试数据作为第一个聚类中心c1;
16、步骤2:计算任意一条测试数据与当前已确定的聚类中心c1的最小距离并根据得到成为下一个聚类中心的概率sim;
17、步骤3:重复步骤1和步骤2,得到概率集合si1,si2,…,sin,然后在[0,1]区间生成一个随机数ri,用ri依次减去概率集合si1,si2,…,sin中的每个概率,取差值首次小于或等于0时对应的测试数据为下一个聚类中心;
18、步骤4:重复步骤2与步骤3,以最后得到的聚类中心为故障聚类中心,之后重新选择一条不会引起故障的测试数据,重复步骤2与步骤3,以最后得到的聚类中心为非故障中心;
19、步骤5:计算集合中每条测试数据分别到故障聚类中心和非故障中心的距离,将集合中每条测试作为一个点,并将每个点划分到距离其最近的聚类中心形成相应的子集合;
20、步骤6:采用各子集合的均值mik更新故障聚类中心和非故障中心,并计算误差平方和,最后重复步骤5与步骤6,待故障聚类中心和非故障中心收敛;
21、误差平方和表示为:
22、
23、其中,nc表示聚类个数,ck表示隶属第k个聚类的测试数据集合,pik表示第k个聚类的测试数据集合中的每i个测试数据,nk表示ck的个数,mik表示各子集合的均值。
24、进一步的,所述表示为:
25、
26、进一步的,所述sim表示为:
27、
28、其中,m表示1-n中任意一个取值。
29、进一步的,所述步骤二中训练svm模型通过多核加权训练进行,加权之后的核函数表示为:
30、
31、其中,x、y表示两条测试数据,γ=0.5。
32、进一步的,所述优先级融合表示为:
33、p(t)=kmeans(t)+svm(t)
34、其中,kmeans(t)和svm(t)表示测试数据t的kmeans预测结果和svm预测结果,
35、p(t)表示测试数据t的优先级,为两个模型预测结果之和,如果t不会引起故障则kmeans(t)=0,svm(t)=0,否则会引起故障,最终测试数据t的优先级有三种,即0,1,2。
36、进一步的,所述通过距离熵值调整优先级具体为:
37、测试数据之间的距离定义如下:
38、设待测系统具有k个参数,假设k个参数分别有v1,v2,...,vk个可能的取值,
39、t1=(t11,t12,...,t1k)和t2=(t21,t22,...,t2k)为待测系统的两条测试数据,利用归一化方法,定义两条测试数据之间的距离为:
40、
41、引用信息熵计算距离熵,距离熵表示为:
42、sd=-d(t1,t2)logd(t1,t2)
43、在测试数据的优先级排序结果中,对于优先级相同的测试数据根据距离熵的大小对其进行优先级调整,如果距离熵相同,则按照概率熵进行局部调整,概率熵表示为:
44、
45、其中,f表示测试数据中预测的缺陷的数量,pj表示第j个预测的缺陷的概率。
46、进一步的,所述步骤4中重复步骤2与步骤3的次数为30次。
47、进一步的,所述步骤6中重复步骤5和步骤6的次数为50次。
48、本发明的有益效果是:
49、本技术首先利用少量的无人机飞控参数数据先进行测试,获取到的测试结果作为测试数据的标签;其次利用kmeans++和支持向量机(support vector machine,svm)建立待测系统的模型;再次由这两个模型对组合测试数据进行预测,将预测结果进行融合;最后根据预测结果进行优先级排序。本技术在只对20%的组合测试数据进行优先测试的情况下,最终排序的组合测试数据的可以更快地检测出更多的故障,极大地提升了检测效率。
- 还没有人留言评论。精彩留言会获得点赞!