一种基于强化学习的旋翼无人机逃逸方法及系统与流程
本发明属于无人机自主决策,更具体地,涉及一种基于强化学习的旋翼无人机逃逸方法及系统。
背景技术:
1、近年来,伴随航空、电子信息技术以及控制理论的不断发展,无人机领域被各国所重视,无人机技术得到长足发展。相较于固定翼无人机,目前的旋翼无人机具备体积较小、飞行自由度比较高、所需造价相对较低、易于控制等优点,旋翼无人机能够在狭窄空间作业,能够在指定位置悬停、垂直升空与降落,在民用以及军事领域越来越受重视。
2、伴随旋翼无人机所涉及的应用领域增加,无人机面临飞行安全威胁类型也逐渐增加。旋翼无人机在执行飞行任务的途中可能会遭遇到各种安全威胁,其中甚至可能遭遇无人机群进行围捕的情形,旋翼无人机的安全将更难以保证。因此,在无人机群围捕场景下,旋翼无人机如何逃脱追捕,保护自身的安全,成为了无人机自主决策领域亟待解决的重要课题。
技术实现思路
1、针对现有技术的缺陷,本发明的目的在于提供一种基于强化学习的旋翼无人机逃逸方法及系统,旨在解决无人机群围捕场景下旋翼无人机如何逃逸的问题。
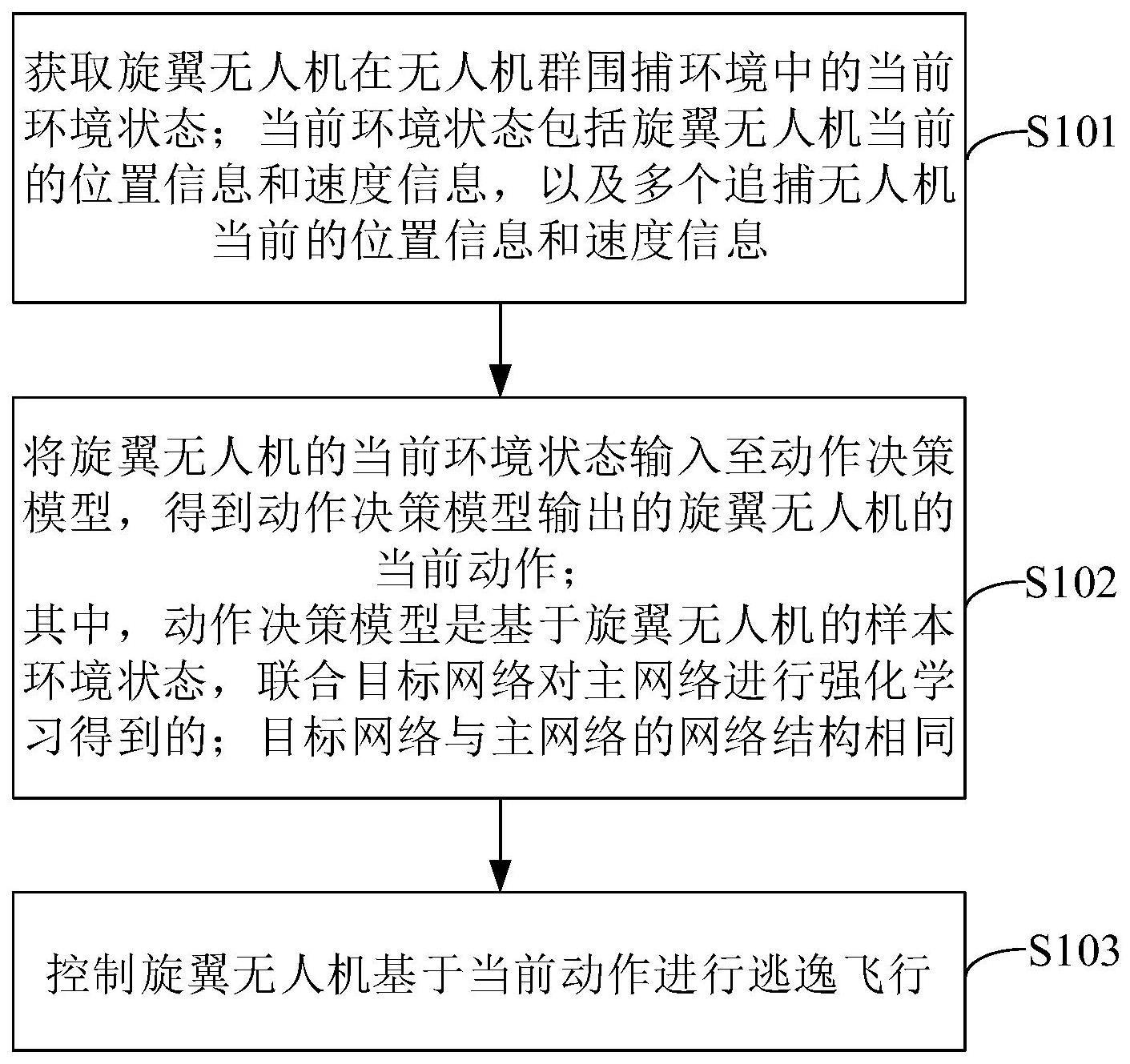
2、为实现上述目的,第一方面,本发明提供了一种基于强化学习的旋翼无人机逃逸方法,包括:
3、s101获取旋翼无人机在无人机群围捕环境中的当前环境状态;所述当前环境状态包括所述旋翼无人机当前的位置信息和速度信息,以及多个追捕无人机当前的位置信息和速度信息;
4、s102将所述旋翼无人机的当前环境状态输入至动作决策模型,得到所述动作决策模型输出的所述旋翼无人机的当前动作;
5、s103控制所述旋翼无人机基于所述当前动作进行逃逸飞行;
6、其中,所述动作决策模型是基于旋翼无人机的样本环境状态,联合目标网络对主网络进行强化学习得到的;所述目标网络与所述主网络的网络结构相同。
7、在一个可选的示例中,所述动作决策模型具体基于如下步骤强化学习得到:
8、将所述样本环境状态输入至主网络中,采用ε-greedy策略从动作空间中选择动作,并在无人机群围捕环境中执行所述动作,获得所述无人机群围捕环境返回的奖励和下一环境状态;
9、基于所述样本环境状态、动作、奖励以及下一环境状态,通过最小化主网络输出的预测q值与目标网络输出的目标q值之差来更新主网络的权重参数,直至满足预设终止条件,且在更新过程中,每隔预设数量个时间步将主网络的权重参数赋值给目标网络;
10、将更新完成的主网络确定为所述动作决策模型。
11、在一个可选的示例中,所述旋翼无人机的动作空间包含无驱动状态、向前驱动、向后驱动、向左驱动、向右驱动、向上驱动和向下驱动;所述旋翼无人机的奖励函数包含相对位置变化奖励、相对速度变化奖励、逃脱任务完成奖励、围捕中心远离奖励和被包围情形奖励。
12、在一个可选的示例中,所述旋翼无人机的相对位置变化奖励具体为:
13、
14、式中,δup(pi)为在一个时间步前后,旋翼无人机在第i个追捕无人机产生的相对位置势场作用下的势能变化,n为追捕无人机的总数,所述相对位置势场定义为:
15、
16、式中,η是值大于零的势场系数常量,ρ0表示所述第i个追捕无人机的影响半径,ρ(pe,pp)是所述第i个追捕无人机与所述旋翼无人机的欧氏距离。
17、在一个可选的示例中,所述旋翼无人机的相对速度变化奖励具体为:
18、
19、式中,δup(pi)为在一个时间步前后,旋翼无人机在第i个追捕无人机产生的相对速度势场作用下的势能变化,所述相对速度势场定义为:
20、
21、式中,μ是系数常量,vre表示所述第i个追捕无人机与所述旋翼无人机的相对速度向量,θre表示所述旋翼无人机与所述第i个追捕无人机的距离向量和所述第i个追捕无人机与所述旋翼无人机的相对速度向量之间的夹角。
22、第二方面,本发明提供了一种基于强化学习的旋翼无人机逃逸系统,包括:
23、状态获取模块,用于获取旋翼无人机在无人机群围捕环境中的当前环境状态;所述当前环境状态包括所述旋翼无人机当前的位置信息和速度信息,以及多个追捕无人机当前的位置信息和速度信息;
24、动作决策模块,用于将所述旋翼无人机的当前环境状态输入至动作决策模型,得到所述动作决策模型输出的所述旋翼无人机的当前动作;其中,所述动作决策模型是基于旋翼无人机的样本环境状态,联合目标网络对主网络进行强化学习得到的;所述目标网络与所述主网络的网络结构相同;
25、动作执行模块,用于控制所述旋翼无人机基于所述当前动作进行逃逸飞行。
26、在一个可选的示例中,所述动作决策模块中的所述动作决策模型具体基于如下步骤强化学习得到:
27、将所述样本环境状态输入至主网络中,采用ε-greedy策略从动作空间中选择动作,并在无人机群围捕环境中执行所述动作,获得所述无人机群围捕环境返回的奖励和下一环境状态;
28、基于所述样本环境状态、动作、奖励以及下一环境状态,通过最小化主网络输出的预测q值与目标网络输出的目标q值之差来更新主网络的权重参数,直至满足预设终止条件,且在更新过程中,每隔预设数量个时间步将主网络的权重参数赋值给目标网络;
29、将更新完成的主网络确定为所述动作决策模型。
30、在一个可选的示例中,所述动作决策模块中的所述旋翼无人机的动作空间包含无驱动状态、向前驱动、向后驱动、向左驱动、向右驱动、向上驱动和向下驱动;所述旋翼无人机的奖励函数包含相对位置变化奖励、相对速度变化奖励、逃脱任务完成奖励、围捕中心远离奖励和被包围情形奖励。
31、在一个可选的示例中,所述旋翼无人机的相对位置变化奖励具体为:
32、
33、式中,δup(pi)为在一个时间步前后,旋翼无人机在第i个追捕无人机产生的相对位置势场作用下的势能变化,n为追捕无人机的总数,所述相对位置势场定义为:
34、
35、式中,η是值大于零的势场系数常量,ρ0表示所述第i个追捕无人机的影响半径,ρ(pe,pp)是所述第i个追捕无人机与所述旋翼无人机的欧氏距离。
36、在一个可选的示例中,所述旋翼无人机的相对速度变化奖励具体为:
37、
38、式中,δup(pi)为在一个时间步前后,旋翼无人机在第i个追捕无人机产生的相对速度势场作用下的势能变化,所述相对速度势场定义为:
39、
40、式中,μ是系数常量,vre表示所述第i个追捕无人机与所述旋翼无人机的相对速度向量,θre表示所述旋翼无人机与所述第i个追捕无人机的距离向量和所述第i个追捕无人机与所述旋翼无人机的相对速度向量之间的夹角。
41、总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
42、本发明提供一种基于强化学习的旋翼无人机逃逸方法及系统,针对群围捕环境下无人机逃逸问题,研究基于强化学习的旋翼无人机逃逸策略,先通过联合目标网络对主网络进行强化学习,由此得到动作决策模型,提高了动作决策模型的稳定性和收敛性,在此基础上,将旋翼无人机的当前环境状态输入到动作决策模型中,再根据决策得到的动作进行旋翼无人机的逃逸飞行,极大提升了旋翼无人机的逃逸能力,保证旋翼无人机的航行安全性,避免旋翼无人机受到抓捕或破坏。
- 还没有人留言评论。精彩留言会获得点赞!