一种数控车床车削过程能耗预测方法与流程
本发明涉及数据处理,具体涉及一种数控车床车削过程能耗预测方法。
背景技术:
1、数控机床的车削加工工艺主要流程为分析图纸,确定工艺,选择刀具,确定夹具,编程加工。车削加工工艺包含多个步骤,每个步骤设计的参数是不同的,整个车床车削过程中的能耗主要发生在刀具切削过程中。数控机床的车削过程中车削刀具做平面运动,按照车削运动的作用,车削运动分为主运动和进给运动。
2、数控机床的能耗组成结构决定了车削过程中能耗的影响参数,能耗预测需要利用车削过程中的采集数据建立数控机床车削过程的能耗预测模型,其次利用能耗预测模型和车削过程的参数数据预测能耗值。但是由于机床包含多个工艺步骤,能耗预测模型与采集数据之间没有明确的定量关系,预测的能耗值与实际车削过程中能耗会存在差异,因此为了提高能耗预测模型的可靠性,提高车削加工的工作效率,应当结合数控机床的能耗系统组成,分析每个加工工艺中影响能耗的因素,确定车削能耗与参数数据之间的定量关系。其次可以基于定量关系修正能耗预测值,确定车削加工的最佳参数,减少能源损耗。
技术实现思路
1、本发明提供一种数控车床车削过程能耗预测方法,以解决现有的数控机床能耗建模的参数选择客观性不足,从而影响能耗分析准确性的问题,所采用的技术方案具体如下:
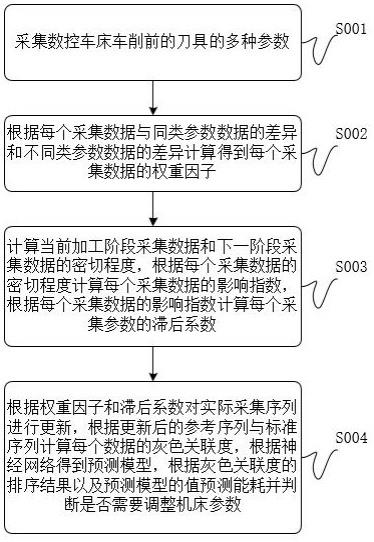
2、本发明一个实施例提供了一种数控车床车削过程能耗预测方法,该方法包括以下步骤:
3、采集数控车床每个阶段不同参数的数据,记为采集数据;
4、将每个加工阶段记为当前加工阶段,在当前加工阶段随机抽取部分采集数据,令每个加工阶段的每个采集数据为第一采集数据,根据第一采集数据与抽取部分的采集数据得到第一采集数据与抽取部分采集数据的差异值;
5、根据差异值得到第一采集数据的同类数据集和不同类数据集,根据第一采集数据、第一采集数据的同类数据集和不同类数据集的每个采集数据以及数据集最大最小参数计算每一次随机抽取中第一采集数据的同类显著度和异类相似度;
6、根据第一采集数据在每次随机抽取结果中的同类显著度和异类相似度、每次随机抽取结果中的同类数据集和不同类数据集采集数据的数量以及随机抽取的次数得到第一采集数据在当前加工阶段的权重因子;
7、对于第一采集数据,在下个加工阶段和第一采集数据物理意义相同的采集数据记为第二采集数据,根据当前加工阶段的第一采集数据、下一个加工阶段的第二采集数据、以及第一采集数据和第二采集数据的差值的均值得到第一采集数据的密切程度;
8、在当前加工阶段和第一采集数据物理意义相同的采集数据记为第三采集数据,根据每个第一采集数据的密切程度以及所有第二采集数据的和得到每个第一采集数据的影响指数,根据当前阶段每个第一采集数据影响指数与所述第一采集数据对应的所有第三采集数据的影响指数累加和的比值得到每个第一采集数据的滞后系数;
9、根据每个加工阶段的所有参数和数据构成实际采集序列和标准序列,根据权重因子和滞后系数对实际采集序列进行更新得到参考序列,根据更新后的参考序列与标准序列计算每个数据的灰色关联度,根据神经网络得到预测模型,以及灰色关联度的排序结果以及预测模型的值预测能耗并判断是否需要调整机床参数。
10、优选的,所述根据第一采集数据与抽取部分的采集数据得到第一采集数据与抽取部分采集数据的差异值的方法为:
11、计算所有抽取部分采集数据的均值和方差,令第一采集数据与均值差值的绝对值减去抽取部分任意采集数据与均值差值的绝对值比上方差得到第一采集数据与抽取部分每个采集数据的差异值。
12、优选的,所述根据差异值得到第一采集数据的同类数据集和不同类数据集,根据第一采集数据、第一采集数据的同类数据集和不同类数据集的每个采集数据以及数据集最大最小参数计算每一次随机抽取中第一采集数据的同类显著度和异类相似度的方法为:
13、
14、
15、式中,是当前加工阶段第p次随机抽取结果中与第一采集数据i同类的数据集,是当前加工阶段第p次随机抽取结果中与第一采集数据i不同类的数据集,是集合中的第j个采集数据,是集合中的第j个采集数据,、分别是数据集、中采集数据的数量,,分别是集合中的最大值,最小值;,分别是集合中的最大值,最小值;是第p次随机抽取结果中采集数据i的同类显著度,是第p次随机抽取结果中采集数据i的异类相似度。
16、优选的,所述根据当前加工阶段的第一采集数据、下一个加工阶段的第二采集数据、以及第一采集数据和第二采集数据的差值的均值得到第一采集数据的密切程度的方法为:
17、
18、式中,x是当前加工阶段的任意一个采集数据,是在下一个加工阶段且与x物理意义相同的第c个采集数据,是下一个加工阶段与采集数据x具有相同物理意义的数据量,是采集数据x与采集数据的差值的均值,是采集数据x的密切指数。
19、优选的,所述根据每个第一采集数据的密切程度以及所有第二采集数据的和得到每个第一采集数据的影响指数的方法为:
20、令每个第一采集数据所对应的所有第二采集数据的值进行累加,将每个第一采集数据对应的密切指数和第二采集数据值的累加和的乘积作为每个第一采集数据的影响指数。
21、优选的,所述根据每个加工阶段的所有参数和数据构成实际采集序列和标准序列的方法为:
22、得到每个加工阶段的所有参数和数据,令其构成一个序列,序列为:
23、
24、其中,是指第g个参数的第d个采集数据,就是实际采集序列;
25、根据标准加工时所有参数和数据,构成一个序列,序列为:
26、
27、是指第g个采集数据的第d个标准采集数据,就是标准序列。
28、优选的,所述根据权重因子和滞后系数对实际采集序列进行更新得到参考序列的方法为:
29、将实际采集序列进行分解,每个参数得到一个对应的采集序列,根据采集序列中每个数据的权重因子进行排序,得到第一采集序列,滞后计算每个数据的滞后系数,按照滞后系数大小对第一采集序列按照从大到小排序,得到每个参数的更新序列,按照分解顺序将每个参数的更新序列组合得到参考序列。
30、本发明的有益效果是:本发明提出一种数控车床车削过程能耗预测方法,针对传统灰色关联分析法部分参数最优解无法获取的问题,根据车削加工流程中的采集数据构建了权重因子和滞后系数两个指标。权重因子的有益效果在于对于任何大小的采集数据都会获取足够多的抽取数据,通过数据在同类数据和不同类数据的显著程度衡量此数据与能耗的关系,避免采集数据过大或者过小时,无法获取足够相邻数据求解距离的问题。滞后系数的有益效果在于考虑了当前加工阶段的参数对下一阶段加工过程中能耗的影响,后续获取的参考序列更加符合实际加工的情况,避免预测能耗过程中机床外界因素对数据的影响。通过对参数最优解的准确获取,能够有效降低大量参数所导致的预测时间过长的问题,提升预测效率,同时最优参数的获取还能够有效提升参数选择的客观性,使得参数选择更加符合实际加工的情况,从而提升能耗的数据分析的准确性。
- 还没有人留言评论。精彩留言会获得点赞!