一种基于深度强化学习的无人机路径优化方法、存储介质及设备
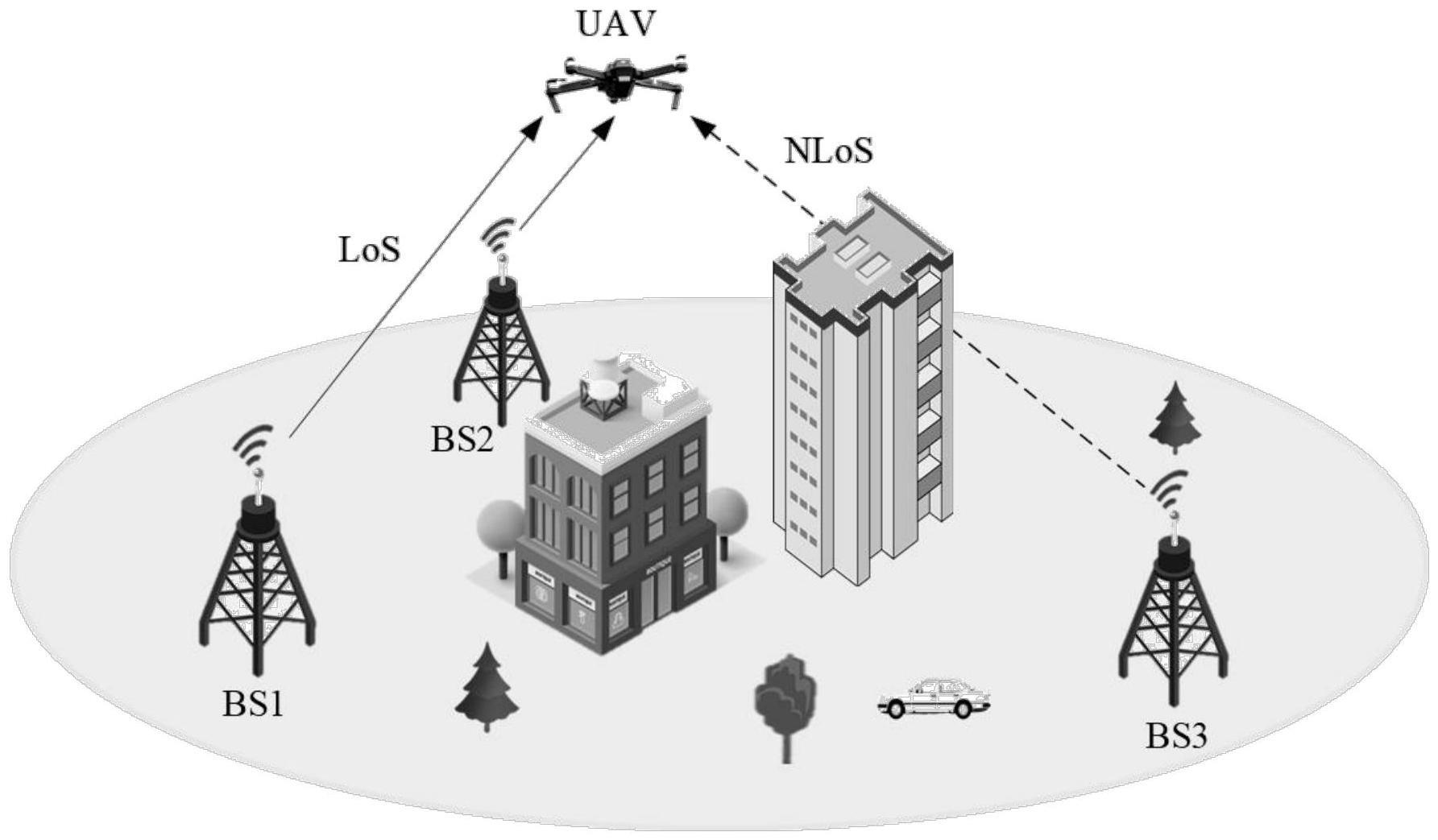
本发明涉及蜂窝网络下无人机与基站之间的通信连通性增强技术,属于无线信息传输领域;具体是针对一种基于深度强化学习的无人机路径优化方法、存储介质及设备。
背景技术:
1、近年来,蜂窝网络与无人机结合的通信方式受到广泛关注。首先,蜂窝网络基础设施遍布全球,可提供经济高效的通信链路,减少通信范围的限制。其次,可以降低延迟,提高数据传输速率,补充定位精度。然而蜂窝连接无人机的通信形式也存在一些问题。由于现有的蜂窝网络主要面向地面用户,基站天线通常是朝向地面倾斜的,导致无法保证完善的空中通信覆盖。同时,蜂窝连接的无人机易受到其它非关联基站的严重干扰。为了保证无人机的飞行安全以及任务完成效率,需要利用无人机的可控移动性,对无人机的飞行路径进行优化,避开弱覆盖区域,从而保证无人机与基站之间的连通性。
2、目前,在路径规划领域广泛使用的dqn算法存在以下问题:样本利用率低,即在回放经验池中进行重采样数据训练,原本的随机采样机制会导致训练样本种类比较单一,进而导致智能体对环境探索率较低,易获取局部最优解,降低训练速度。本发明提出了一种基于深度强化学习的无人机路径优化方法、存储介质及设备,该方法采用优先经验回放机制代替传统的均匀采样,在保证样本多样性的同时提高了重要样本的利用率,获取更精确的回报值,更加有效地对无人机路径进行优化。
技术实现思路
1、本发明针对现有技术中的不足,提供一种基于深度强化学习的无人机路径优化方法、存储介质及设备;通过在保证样本多样性的同时提高了重要样本的利用率,能够获取更精确的回报值,更加有效地对无人机路径进行优化。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于深度强化学习的无人机路径优化方法,包括以下步骤:
4、s1:建立无人机与无线电网络的通信模型,包括场景模型、基站天线辐射模型以及信号模型,其中,
5、(一)场景模型:
6、设定无人机飞行区域范围d×d,以及在该范围内的障碍物高度和位置;
7、定义无人机在时刻t的位置为q(t)=(xt,yt),t∈[0,t],xt∈[0,d],yt∈[0,d],式中xt和yt表示无人机在时刻t位置的x坐标和y坐标;t表示无人机从起点位置至终点位置所用的飞行总时间;
8、(二)基站天线辐射模型:
9、设定基站扇区共有m个,并构建出基站天线辐射模型aa(θ,φ),其中基站天线为多阵元均匀线阵;
10、(三)信号模型:
11、分析无人机在q(t)位置与小区m,m∈m之间的路径损耗模型,包括视距路径损耗和非视距路径损耗
12、s2:计算无人机在不同位置的信号中断概率,以此构建无线电覆盖概率图e,具体方法如下:
13、s2.1:根据步骤s1建立的通信模型,分析无人机在时刻t位置从小区m接收到的瞬时信号功率为ym(t)
14、s2.2:根据ym(t)计算时刻t的信号干扰比sir(t);
15、s2.3:根据信号干扰比sir(t)测量无人机在时刻t所在位置q(t)与每个关联小区b(t)间的通信中断概率pout(q(t),b(t));
16、s2.4:根据测量的通信中断概率,确定在q(t)位置的最佳关联小区b(t)*:
17、
18、s2.5:因此q(t)位置的通信覆盖概率=1-无人机在q(t)位置的中断概率,并将通信覆盖概率值保存到无线电覆盖概率图e中;其中无人机在q(t)位置的中断概率为pout(q(t)):
19、
20、s3:综合考虑无人机飞行时间和不同位置的通信覆盖概率设定无人机飞行路径的优化目标;基于优化目标,利用深度强化学习算法对无人机飞行路径进行优化。
21、为优化上述技术方案,采取的具体措施还包括:
22、进一步地,在步骤s1中,基站天线辐射模型中aa(θ,φ)构建过程如下:
23、aa(θ,φ)=ge,max-min{-[ae,v(θ)+ae,h(φ)],am}+10log10[1+ρ(|a·wt|2-1)]
24、式中,θ和φ分别是基站天线的俯仰角和方位角;ge,max是天线阵元在主瓣方向上的最大方向增益,ae,v(θ)和ae,h(φ)分别是天线的垂直和水平辐射图,am是前后比,ρ为相关系数,a表示幅度向量,w为波束成形向量;
25、参量ae,v(θ)和ae,h(φ)的具体计算公式为:
26、
27、
28、式中,θ3db和φ3db分别是天线在垂直和水平方向的半功率波束宽度;slav是天线的旁瓣电平限制。
29、进一步地,在步骤s1中信号模型对于视距路径损耗和非视距路径损耗的计算内容如下:
30、
31、
32、式中,dm(q(t))是无人机在q(t)位置与小区m之间的距离;fc是载波频率;h是无人机在q(t)位置时所处的高度。
33、进一步地,在步骤s2.1中无人机在q(t)位置从小区m接收到的瞬时信号功率为ym(t)具体计算公式为:
34、
35、式中,pm是小区m的发射功率;hm(t)是t时刻的信道功率增益;β(q(t))表示在q(t)位置的基站天线增益,是一个随机变量,表示t时刻无人机与小区m之间的小尺度衰落;表示无人机在q(t)位置时与小区m之间的大尺度信道功率增益,其中los link表示是在视距路径链接下,nlos link表示是在非视距路径链接下。
36、进一步地,在步骤s2.2中计算时刻t的信号干扰比sir(t)的具体内容为:
37、
38、式中,b(t)表示t时刻无人机的某个关联小区;yb(t)(t)表示t时刻无人机从关联小区b(t)接收到的瞬时信号功率。
39、进一步地,在步骤s2.3中,计算pout(q(t),b(t))的具体内容如下:
40、s2.3.1:定义无人机在q(t)位置与某个关联小区b(t)之间通信的中断概率为pout(q(t),b(t)):
41、
42、式中,pr(·)表示事件发生的概率;γth为设置的阈值,当信号干扰比sir(t)低于γth时,视为无人机处于通信中断状态;
43、s2.3.2:将信号干扰比sir(t)改写为sir(q(t),b(t),即将变量时刻t改为对应时刻下的无人机位置q(t)、关联小区b(t)、无人机与关联小区b(t)之间小尺度衰落定义中断指示函数为c(q(t),b(t),
44、
45、s2.3.3:根据步骤s2.3.2的内容将s2.3.1的中断概率pout(q(t),b(t))改写为的期望值:
46、
47、然后在一定时间内测量无人机与每个关联小区b(t)的信号干扰比sir值j次,获得该位置无人机与每个关联小区b(t)的中断概率:
48、
49、式中,表示为t时刻无人机与关联小区b(t)之间小尺度衰落的第j个测量值。
50、进一步地,在步骤s3,所述设定无人机飞行路径的优化目标的具体内容为:
51、s3.1:构建连续优化目标函数:
52、
53、s.t.q(0)=qs
54、q(t)=qf
55、式中,t表示从无人机从起点到终点的飞行时间;μ是一个非负系数;q(0)表示初始时刻下无人机所在位置;qs代表无人机起始位置;q(t)表示末点时刻下无人机所在位置;qf代表无人机终点位置;
56、s3.2:将步骤s3.1中对连续优化问题进行离散化处理,将无人机飞行区域划分为一系列相邻的网格点,最终目标函数等价于最小化无人机经过的网格点数n和预期中断概率的加权和:
57、
58、s.t.q0=qs
59、qn=qf
60、式中,qn表示无人机在划分网格中n,(n∈n)点的所在位置;pout(qn)表示无人机在n点位置时中断概率;q0表示无人机起始点所在位置;qf表示无人机终点所在位置。
61、进一步地,在步骤s3中,所述基于优化目标,利用深度强化学习算法对无人机飞行路径进行优化具体内容为:
62、(一)、先让无人机从起点至终点进行实际试飞行,内容如下:
63、1):设置无人机实际试飞行的最大迭代次数为nepi、每次迭代中无人机经过网格点的最大数也即称无人机走的最大步数为nstep,初始化无人机探索概率ε→ε0,设置无人机探索概率衰减率α、无人机到达终点奖励值rdes、无人机出界飞行区域围d×d的惩罚值pob、非负系数μ、容量为c的重放经验池d,无线电覆盖概率图e,设置地图神经网络及其参数ξ、深度q网络及其参数θ、目标深度q′网络及其参数θ-=θ;设置并初始化经验回放求和树的默认数据结构,并将每个求和树叶子节点的优先级pi初始化为ps,即pi→ps;
64、2):无人机开始执行实际试飞行任务、设循环变量nepi=1,其表示实际试飞行任务中的第1次迭代;
65、3):初始化大小为n1的滑窗w、初始化无人机实际试飞行初始位置qn=qs,此时qn中的n=0,表示无人机此时所经过网格点或走无人机探索的步数为0;
66、4):以ε-greedy策略选择动作vn,具体是以ε的概率在动作空间中随机选择动作,以1-ε的概率选择到最优动作;
67、5):执行动作vn,得到无人机在下一状态的位置qn+1,通过无线电覆盖概率图e中测量获得的qn+1位置的中断概率pout(qn+1),设置单步奖励rn:
68、rn=-1-μpout(qn+1)
69、6):将(qn,vn,rn,qn+1)存储在滑窗w中;其中当n≥n1时,计算n-n1至n步的累计奖励然后将第n-n1步的位置、动作、n-n1至n步的累计奖励以及第n步位置的数据样本存储到求和树节点中;
70、7):更新无人机探索的步数n,循环步骤4)-7)得到多个数据样本;
71、8):从求和树中采样k个节点的样本其中每个样本j被采样的几率为pj表示节点样本j的优先级,表示求和树所有节点优先级总和,求和树节点样本损失函数权重ωj=(p(j)/minip(i))-β,β决定了优先经验回放对收敛结果的影响;
72、9):计算求和树k个节点样本中各个节点样本j的当前奖励值yj,具体方法如下:
73、
74、式中,表示无人机从j步至j+n1步的累计奖励;表示无人机在j+n1步时候的位置,s表示无人机飞行区域d×d,γ表示回报折扣率,表示目标深度q′网络对深度q网络在qj+n1位置选择最优动作v*的评估奖励值;
75、10):对损失函数执行梯度下降,并更新深度q网络参数θ;其中ωj表示损失函数权重、表示目标q′网络对q网络在qj位置选择动作vj的评估奖励值;
76、11):基于无线电覆盖概率图e,并更新地图神经网络参数ξ;然后进行无人机的模拟试飞行任务:
77、步骤1:初始化无人机模拟试飞行任务的初始位置其中各参量上方的标号“~”是表示当前状态处于模拟试飞行任务,以区分实际飞行中的参量,此时中的表示无人机在模拟试飞行任务中此时所经过网格点或走无人机探索的步数为0;设置循环变量表示在模拟试飞行任务中的第1次迭代;
78、步骤2:同步骤4)-10)处理过程,其中有区别的是在步骤5)中的中断概率由地图神经网络预测输出得到,而地图神经网络的输入参量是无线电覆盖概率图e中的数据;
79、步骤3:判断无人机是否到达终点、或出界、或达到最大步数nstep时,执行步骤4;否则,令重复循环到步骤2中;
80、步骤4:分析迭代次数每迭代循环b次,更新目标深度q′网络参数θ-→θ,然后到步骤5;
81、步骤5:若则循环结束;若则令并返回步骤1中;
82、12)回到实际试飞行任务中,判断无人机是否到达终点、或出界、或达到最大步数nstep,若是则执行步骤13);否则,令n=n+1且无人机探索概率ε→εα,并重复循环到步骤4)中;
83、13)分析迭代次数nepi,每迭代循环b次,更新目标深度q′网络参数θ-→θ;然后到步骤14);
84、14)若nepi=nepi,则循环结束;若nepi<nepi,则令nepi=nepi+1并返回步骤3)中;
85、(二)、通过步骤1)-14)的整个过程能够不断完善目标深度q′网络的参数θ-,因此目标深度q′网络针对深度q网络对于无人机在某一位置qn选择动作vn的评估奖励值也逐渐达到最优;此时不再进行实际试飞行,直接通过最终训练完成后的目标深度q′网络指导无人机从不同的起点飞到不同的终点,期间通过目标深度q′网络指导飞行动作的选择,使得无人机选择奖励值最大的动作,完成路径规划。
86、一种计算机可读存储介质,存储有计算机程序,所述计算机程序使计算机执行如上述任一项所述的无人机路径优化方法。
87、一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行计算机程序时,实现如上述任一项所述的无人机路径优化方法。
88、本发明的有益效果是:
89、1、本技术对无人机的飞行路径进行优化,避开弱覆盖区域,从而保证无人机与基站之间的连通性。
90、2、本发明提出了一种基于深度强化学习的无人机路径优化方法、存储介质及设备;通过使用了基于求和树的优先经验回放机制,打破了均匀采样,赋予学习效率高的样本以更大的采样权重。然后本技术方案在保证样本多样性的同时提高了重要样本的利用率,获取更精确的回报值,更加有效地对无人机路径进行优化。
- 还没有人留言评论。精彩留言会获得点赞!