基于博弈论的机器人最大覆盖面积动态规划方法及系统
本发明涉及机器人路径规划,具体而言,涉及基于博弈论的机器人最大覆盖面积动态规划方法及系统。
背景技术:
1、机器人覆盖问题主要研究:对于一些具有一定感知,通信和计算能力的机器人,通过自组织的方式运动,最终形成对特定环境的最大覆盖的网络,同时保证整体的连通性和一致性。其中的重点在于每个机器人在每个时刻的路径决策,如此一来,我们可以把机器人覆盖问题看作路径规划问题。
2、目前对于动态路径的算法常用的为集中式,集中式算法虽然可以找到优化的策略,但是需要在开始时获知全局信息,是静态的策略,对复杂环境的适应能力差,并且算法的复杂性高,鲁棒性差。
技术实现思路
1、本发明的目的是提供基于博弈论的机器人最大覆盖面积动态规划方法及系统,来解决集中式算法复杂性高,鲁棒性差的问题。
2、本发明的实施例通过以下技术方案实现:
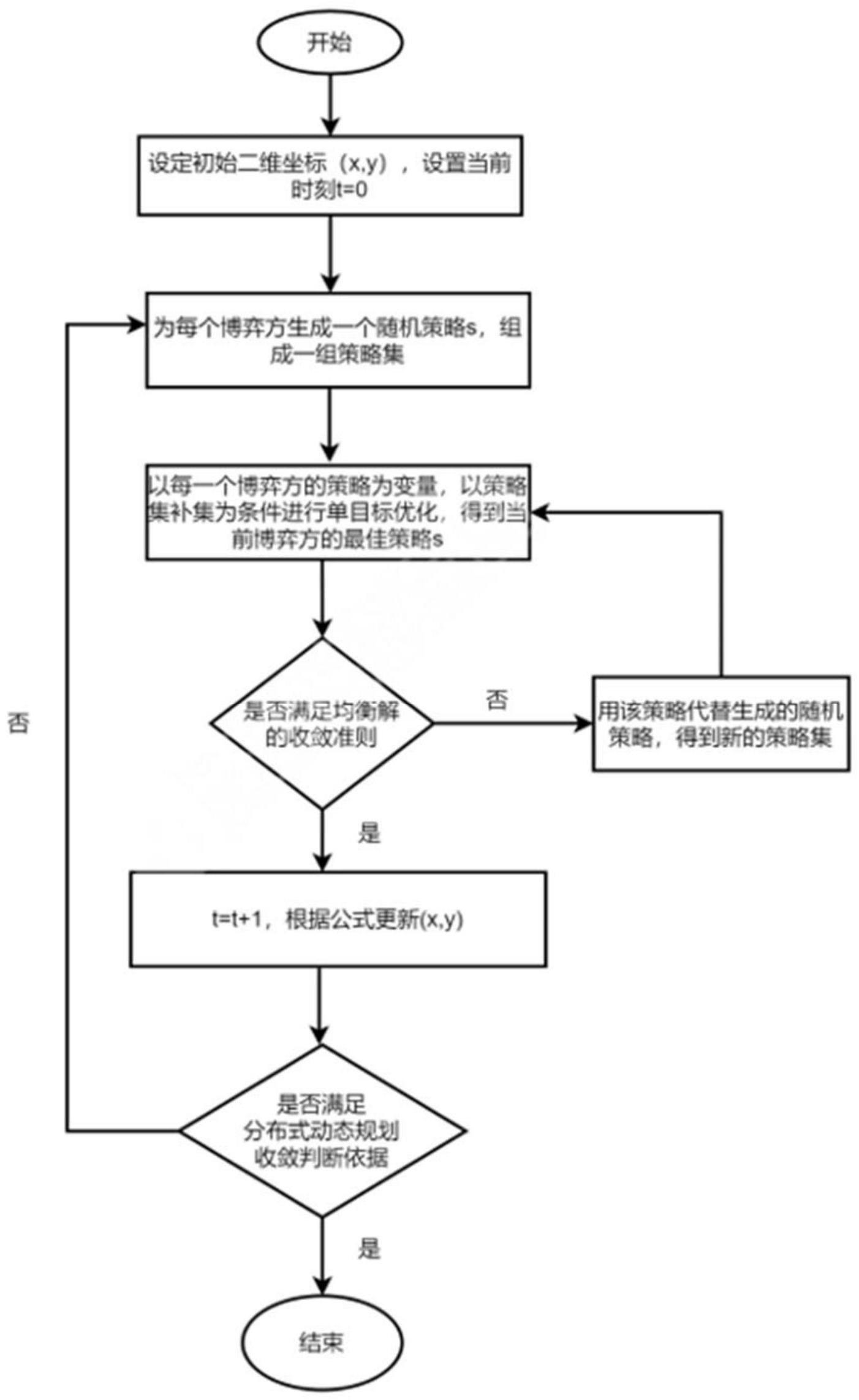
3、第一方面,本发明提供的基于博弈论的机器人最大覆盖面积动态规划方法,包括;
4、获取初始坐标;
5、根据博弈论生成初始策略集;
6、根据单目标优化进化算法为每个博弈方生成最佳策略集;
7、判断该博弈方最佳策略集是否满足均衡解收敛准则;若满足则根据该策略集更新机器人坐标;若不满足则用该策略集替换上一组策略集得到新的策略集,并重复进行新一轮单目标优化;
8、判断是否满足分布式动态规划收敛判断依据;若满足则获得最终机器人位置及行动路线以及最大覆盖面积,构建机器人行动路线模型,得到机器人达到分布最大覆盖面积的路径;若不满足则重复进行新一轮博弈,生成新的博弈策略集。
9、在本发明的一实施例中,所述判断该博弈方最佳策略是否满足均衡解收敛准则包括;
10、计算博弈方收益函数,并设置阈值;
11、所有博弈方中收益函数最大值减最小值的差除以平均值的绝对值小于等于设定阈值,则根据博弈策略集对每个机器人的坐标进行更新并进入下一轮次的博弈;
12、若大于设定阈值,则用该策略集替换上一轮生成的策略集,重新进行单目标优化。
13、在本发明的一实施例中,所述构建机器人行动路线模型包括;
14、给出机器人当前轮次的策略集,并规定约束条件;
15、根据约束条件对当前策略集进行规范,并计算收敛函数。
16、在本发明的一实施例中,所述约束条件包括;
17、每个博弈方博弈策略步长不能超过最大步长;
18、每个博弈方的邻居数大于等于规定的数值;
19、利用约束条件规范策略选择,剔除不符合要求的移动策略。
20、在本发明的一实施例中,所述计算收敛函数包括;
21、计算每个博弈方当前坐标与根据策略移动后的坐标之间的距离和;
22、若该数值小于等于所规定的阈值,则收敛成功,按照每一部策略集得到机器人的移动路径及最大网络覆盖拓扑结构;
23、否则收敛失败,则重新生成新一组的策略集。
24、在本发明的一实施例中,所述根据单目标优化进化算法为每个博弈方生成最佳策略集包括;
25、设置初始种群,规定最大进化代数,以及当前初始进化代数0;
26、随机产生规定个数的父本以及设置初始方差向量;
27、根据初始方差向量让父本变异并选择收益函数高的个体进入下一代;
28、计算每个父本策略集下收益函数;
29、计算结果若满足收敛条件,则确认该策略集为当前博弈方的最优策略集;
30、若不满足则调整方差向量的值,让父本变异并选择合适的个体进入下一代。
31、在本发明的一实施例中,所述满足收敛条件包括,收益函数中最大值减最小值除以收益函数平均值的绝对值结果小于等于所规定的阈值或者当前进化代数大于规定的最大进化代数。
32、第二方面,本发明还提供了机器人路径规划方法,包括;
33、获取雷达影像数据,构建三维坐标体系;
34、根据所述机器人的初始位置数据,将移动方向扩展为三维空间方向角;
35、通过上述的基于博弈论的机器人最大覆盖面积动态规划方法获得机器人最大网络覆盖拓扑结构与路径。
36、第三方面,本发明还提供了基于博弈论的机器人最大覆盖面积动态规划系统,包括;
37、获取模块,被配置为获取初始坐标;
38、生成模块,被配置为根据博弈论生成初始策略集;
39、优化模块,被配置为根据单目标优化进化算法为每个博弈方生成最佳策略集;
40、收敛条件第一判断模块,被配置为判断该博弈方最佳策略集是否满足均衡解收敛准则;若满足则根据该策略集更新机器人坐标;若不满足则用该策略集替换上一组策略集得到新的策略集,并重复进行新一轮单目标优化;
41、收敛条件第二判断模块,被配置为判断是否满足分布式动态规划收敛判断依据;若满足则获得最终机器人位置及行动路线以及最大覆盖面积,构建机器人行动路线模型,得到机器人达到分布最大覆盖面积的路径;若不满足则重复进行新一轮博弈,生成新的博弈策略集。
42、第四方面,本发明还提供了一种计算机可读存储介质所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现上述的基于博弈论的机器人最大覆盖面积动态规划方法。
43、本发明实施例的技术方案至少具有如下优点和有益效果:
44、1.本发明通过已知机器人初始位置的情况下,通过机器人自行获取邻居信息,处理信息,交换信息,协同合作的方式解决机器人最大覆盖问题,提高了系统的准确性、泛用性,鲁棒性及可靠性,解决了将移动方向和移动步长分开作为博弈变量计算量大的问题,实现了在无法获取全局信息的情况下,通过机器人之间的信息交换与写作达到了最大网络覆盖,尤其适用于地势环境复杂,全局数据缺失情况下的机器人最大网络覆盖的路径规划问题。
45、2.机器人的路径不仅限于二维平面移动,可以扩展第三维高度,实现寻找机器人三维立体最大网络覆盖体积,能够增加该方法的泛用性,鲁棒性,使机器人能够适应更复杂的环境。
技术特征:
1.基于博弈论的机器人最大覆盖面积动态规划方法,其特征在于,包括;
2.根据权利要求1所述的基于博弈论的机器人最大覆盖面积动态规划方法,其特征在于,所述判断该博弈方最佳策略是否满足均衡解收敛准则包括;
3.根据权利要求1所述的基于博弈论的机器人最大覆盖面积动态规划方法,其特征在于,所述构建机器人行动路线模型包括;
4.根据权利要求3所述的基于博弈论的机器人最大覆盖面积动态规划方法,其特征在于,所述约束条件包括;
5.根据权利要求3所述的基于博弈论的机器人最大覆盖面积动态规划方法,其特征在于,所述计算收敛函数包括;
6.根据权利要求1所述的基于博弈论的机器人最大覆盖面积动态规划方法,其特征在于,所述根据单目标优化进化算法为每个博弈方生成最佳策略集包括;
7.根据权利要求6所述的基于博弈论的机器人最大覆盖面积动态规划方法,其特征在于,所述满足收敛条件包括,收益函数中最大值减最小值除以收益函数平均值的绝对值结果小于等于所规定的阈值或者当前进化代数大于规定的最大进化代数。
8.机器人路径规划方法,其特征在于,包括;
9.基于博弈论的机器人最大覆盖面积动态规划系统,其特征在于,包括;
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质上存储计算机程序,所述计算机程序被处理器执行时实现如权利要求1至7中任一项所述的基于博弈论的机器人最大覆盖面积动态规划方法。
技术总结
本发明属于机器人路径规划技术领域,具体涉及基于博弈论的机器人路径规划方法,该方法包括步骤:获取初始坐标数据;根据博弈论生成初始策略;根据单目标优化进化算法为每个博弈方生成最佳策略;判断该博弈方最佳策略是否均衡解收敛准则;用该策略替换上一组策略得到新的策略接并重复进行新一轮进化;根据博弈策略集更新机器人坐标;判断是否满足分布式动态规划收敛判断依据;重复进行新一轮博弈;获得最终机器人位置及行动路线以及最大覆盖面积;得到机器人达到分布最大覆盖面积的路径。本发明通过机器人之间信息感知、处理,交互协同作用,实现了全局策略情况未知的情况下规划机器人路径使其最大网络覆盖拓扑结构。
技术研发人员:苏源,马浩然,彭倍,高松,苏泉
受保护的技术使用者:电子科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!