一种基于深度强化学习算法的无人机电力巡检方法
本发明涉及无人机控制和深度强化学习领域,具体涉及一种基于深度强化学习算法的无人机电力巡检方法。
背景技术:
1、电力巡检的任务主要是对电力设备进行定期巡查、检测、维护和保养,以确保电力设备的正常运行和安全运行,保障电力供应的稳定性,提高电力设备的使用效率和经济效益。传统的电力巡检方式通常为人工巡检和机器人巡检。人工巡检的方式,不仅效率低下,对于一些异常情况可能出现漏检,并且成本过高,同时也存在着极大的安全隐患。无人机技术近几年快速发展,其独特的低成本,低消耗,高可控性,让电力巡检有了新的思路。
2、深度强化学习是一种可行的方法,其将深度学习的感知能力和强化学习的决策能力相结合,为复杂系统的感知决策问题提供了解决思路。
3、以上情形都局限于某些山区或是空旷场景,而涉及城市内的电力设备,由于目前国内外城市环境复杂,城市内电路系统向地下改造等,尚未有合适的无人机电力巡检方法。
技术实现思路
1、本发明针对城市内电力巡检的需求,提出了一种基于深度强化学习算法的无人机电力巡检方法,在满足巡检条件的情况下,最大化了数据的采集率并搜寻最短路径。具体技术方案如下:
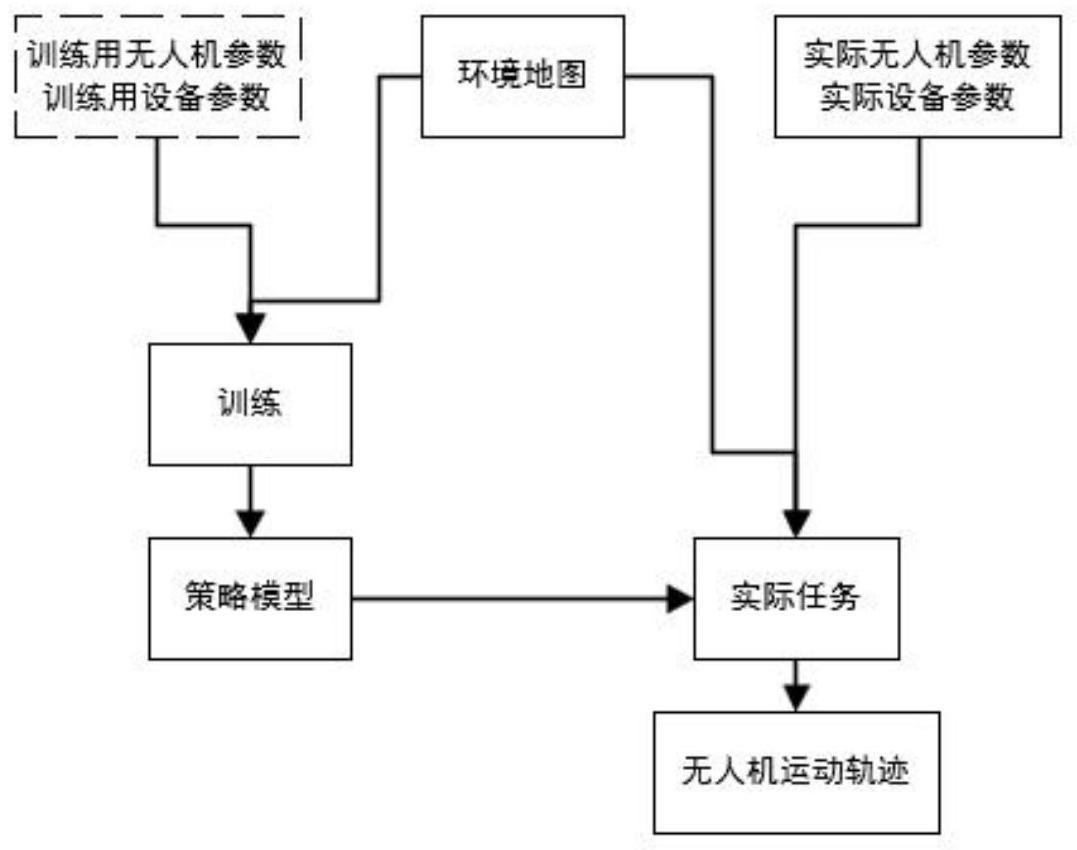
2、一种基于深度强化学习算法的无人机电力巡检方法,该方法包括如下步骤:
3、步骤1:根据真实楼房建模作为环境地图,设定好起降点l,障碍物ob,禁飞区z,设定用于训练的设备和无人机的参数范围,设定无人机运动模型,设定电力设备分布模型,初始化参数;
4、步骤2:将电力设备巡检问题抽象为非中心部分可观测马尔可夫决策过程问题,即用已知的部分局部地图预测未知的全地图信息;
5、步骤3:将地图中心化处理,即将地图放大后,让无人机处于地图中心,空白点由填充值填充,在无人机发生位移时转而由地图产生平移;
6、步骤4:将中心化的地图裁剪为一定大小的局部地图,即围绕处于原点的无人机为中心以一定范围进行裁剪,用以描述无人机附近的地理特征,训练无人机短期避障能力;
7、步骤5:将中心化的地图池化为一定大小的全局地图,即在一定范围内进行平均池化,用以描述全域内的大致地理特征,训练无人机长期决策能力;
8、步骤6:令全局化的地图和局部化的地图分别进入两个独立的卷积神经网络层提取地图特征;
9、步骤7:地图合并后进入基于通道的多头自注意力机制层;
10、步骤8:将数据输入双重深度q网络中,迭代指定次数后,输出策略网络参数,完成训练过程;
11、步骤9:将策略网络参数嵌入无人机中,每次执行巡检任务时,按照本次任务的情况,输入无人机参数和电力设备参数,启动无人机根据策略网络参数执行巡检任务。
12、进一步地,所述步骤1中,对于设备和无人机的参数的初始化,包括以下步骤:
13、所述步骤1中设备和无人机的参数包括:无人机初始电量,无人机数量,设备位置,设备待检测数据量,设备数量;
14、多无人机i={1,2,…,i,…,j,…,n}的运动符合以下方程组:
15、
16、
17、
18、
19、式中pi(t)为当前时刻无人机位置,bi(t)为当前时刻无人机电量,z为禁飞区的点集,l为起降点的点集,t为时间;
20、多无人机i={1,2,…,i,…,j,…,n}的对设备信息的采集符合以下方程组:
21、
22、式中s(t)为当前时刻所有无人机采集数据量,qi(k)为当前无人机对电力设备k的优先级函数组,v(k)为收集速率,k为电力设备的总数量,n为无人机的总数量。
23、进一步地,所述步骤2中,对于非中心部分可观马尔可夫决策过程问题的转化,包括以下步骤:
24、决策过程由五元组(s,t,p,r,o)描述,s表示状态集,t表示动作集,p表示概率分布函数,r表示奖惩函数,o表示观测空间;
25、采用奖惩函数为:
26、
27、式中rt为t时刻的回报,gi(t)为无人机i在任意t时刻受到的采集奖励,与t时刻采集到的数据量s(t)成正相关,γi(t)表示无人机i在任意t时刻受到的超时惩罚,βi(t)表示无人机i在t时刻收到的碰撞惩罚,无人机未到达终点时,会持续受到固定惩罚∈。
28、进一步地,所述步骤3中,对于地图中心化处理的过程,包括以下步骤:
29、假定原地图为a,对应无人机i经过处理的地图为bi,则转换满足:
30、
31、式中bi(m,n)表示地图bi中(m,n)点处的值,a(m+p0-m+1,n+p1-m+1)为a地图上的坐标(m+p0-m+1,n+p1-m+1)处的值,(p0,p1)为无人机i当前位置pi(t),m为a地图的边长。
32、进一步地,所述步骤4中,对于地图局部化处理的过程,包括以下步骤:
33、设转换后的地图为xi,则满足下列公式:
34、
35、式中xi(m,n)表示地图xi上(m,n)点处的值,p为裁剪核尺寸,表示对p取一半后向上取整,m为原地图a的边长。
36、进一步地,所述步骤5中,对于地图全局化处理的过程,包括以下步骤:
37、设转换后的地图为yi,则应满足下列公式:
38、
39、式中yi(m,n)表示地图yi上(m,n)点处的值,池化核尺寸为q,m为原地图a的边长。
40、进一步地,所述步骤6中,对于深度卷积网络的布置,包括以下步骤:
41、神经网络的初始化满足卷积层深度为2,卷积核大小为5x5。
42、与现有技术相比,本发明的有益效果是:
43、1)为了最大化智能体对地图环境的学习,针对电力巡检任务的实际执行中的连续性策略,建立了基于双地图的卷积神经网络结构。双地图由特征池化的全局地图和专注于附近场景的局部地图组成。经过卷积神经网络的特征提取后,再通过基于通道的多自注意力机制层,为每层特征加权后,以地图形式输入深度强化学习网络,更契合复杂多样的地理环境,满足电力巡检任务的要求。
44、2)使用了非固定的无人机与设备参数来对模型进行训练,该机制使模型对不同参数下的场景都有着良好的泛化能力。在实际使用中,不需要因为无人机数量的变化或待巡检电力设备位置和数量的变化而重新进行训练。
45、3)根据巡检任务的要求,建立了巡检任务完整的奖励机制,以做到最高效的训练过程。基于巡检任务的规模,提出了结合基于ddqn的结合多头自注意力机制的巡检路径规划机制,在网络参数规模上和任务完成度上都做到了理想的适配。
技术特征:
1.一种基于深度强化学习算法的无人机电力巡检方法,其特征在于,该方法包括如下步骤:
2.根据权利要求1所述的方法,其特征在于,所述步骤1中,对于设备和无人机的参数的初始化,包括以下步骤:
3.根据权利要求1所述的方法,其特征在于,所述步骤2中,对于非中心部分可观马尔可夫决策过程问题的转化,包括以下步骤:
4.根据权利要求1所述的方法,其特征在于,所述步骤3中,对于地图中心化处理的过程,包括以下步骤:
5.根据权利要求1所述的方法,其特征在于,所述步骤4中,对于地图局部化处理的过程,包括以下步骤:
6.根据权利要求1所述的方法,其特征在于,所述步骤5中,对于地图全局化处理的过程,包括以下步骤:
7.根据权利要求1所述的方法,其特征在于,所述步骤6中,对于深度卷积网络的布置,包括以下步骤:
技术总结
本发明属于无人机控制领域,具体公开了一种基于深度强化学习算法的无人机电力巡检方法,该方法针对城市内电力巡检的需求,在满足巡检条件的情况下,通过对目标区域环境,无人机运动过程,电力设备布置的建模,整合得到地图数据,再通过对地图的中心化和根据无人机动作连续性的分化预处理,使用卷积神经网络和多头自注意力机制提取特征,再通过强化学习算法得出无人机在电力巡检任务上的最佳决策机制,最大化了数据的采集率并搜寻最短路径。本发明以地图形式输入深度强化学习网络,更契合复杂多样的地理环境,满足电力巡检任务的要求。
技术研发人员:吴哲夫,王盛洁
受保护的技术使用者:浙江工业大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!