基于强化学习的四旋翼无人机预置性能跟踪控制方法
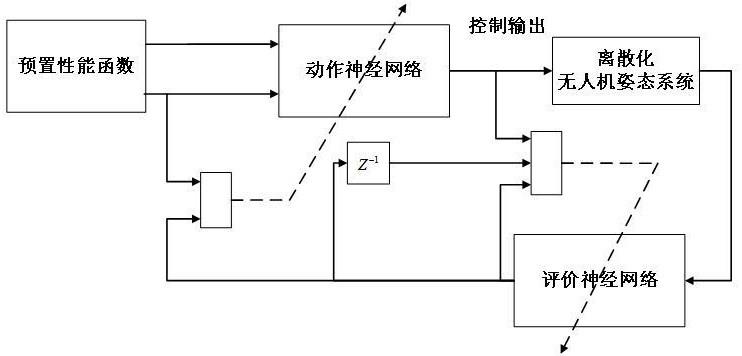
本发明属于无人机自动控制,具体涉及基于强化学习的四旋翼无人机预置性能跟踪控制方法。
背景技术:
1、随着航空航天技术的发展与进步,在各种类型的四旋翼无人机中,四旋翼飞行器作为无人机家族中的一类特殊飞行器,以其低成本、小尺寸、结构简单以及机动性强的特点,多用于监视侦察、紧急救援、空中航拍、大气监测等用途,在军事、民用领域展现出了的巨大应用前景,在全世界范围内形成了研究热潮,而控制系统的研究则是四旋翼飞行器研究中的核心。
2、考虑到四旋翼飞行器是一个多变量、欠驱动、强耦合的非线性系统,一些学者采用了智能控制策略进行非线性系统识别和补偿,但尚未考虑到强非线性条件下的瞬态性能,对瞬态性能控制的不足可能导致系统响应不佳,包括超调、收敛速率和其他相关因素,会危及系统的稳定性,甚至可能导致系统故障。因此,对四旋翼无人机控制系统的瞬态性能进行全面研究具有至关重要的意义,如何增强控制系统有效处理动态突变的能力来提高系统的安全性能成为研究热点。
3、目前,关于四旋翼无人机的跟踪控制方法主要集中以下几个方面:(1) 基于扰动观测器的外部抗干扰控制;(2) 基于势函数或者图像的自适应避障控制;(3) 基于自适应动态规划的姿态控制等。在以往的四旋翼无人机设计过程中,通常情况下针对四旋翼无人机飞行的鲁棒性、安全性和可操控性进行研究,旨在提高四旋翼无人机复杂环境的适应性,但以往的方法在提高系统的瞬态性能以及智能自主性方面还鲜有研究。
技术实现思路
1、本发明所要解决的技术问题是针对上述现有技术的不足,提供基于强化学习的四旋翼无人机预置性能跟踪控制方法,在传统控稳四旋翼无人机的基础上,从动态性能和自主性方面提高四旋翼无人机的性能,为后续的智能自主应用提供强有力的支撑。
2、为实现上述技术目的,本发明采取的技术方案为:
3、基于强化学习的四旋翼无人机预置性能跟踪控制方法,包括以下步骤:
4、步骤1:构建四旋翼无人机的姿态动力模型,采用预置性能函数对姿态动力模型建立姿态角状态约束后,结合姿态角误差变量,构建满足四旋翼无人机瞬态响应性能要求的姿态跟踪误差模型;
5、步骤2:将步骤1构建的姿态跟踪误差模型离散化,基于离散化后的姿态跟踪误差模型构造四旋翼无人机的长期代价函数,形成积分强化学习的实时奖励函数;
6、步骤3:构建四旋翼无人机系统控制行为好坏的评价神经网络,基于评价神经网络对长期代价函数的估计值,构建积分强化学习的误差模型,结合步骤2形成的实时奖励函数,建立评价神经网络-动作神经网络积分强化学习控制模型;
7、步骤4:对评价神经网络-动作神经网络积分强化学习控制模型中的评价神经网络、动作神经网络分别设计权重更新律,使用采用所述权重更新律的积分强化学习控制模型对四旋翼无人机姿态进行跟踪控制。
8、为优化上述技术方案,采取的具体措施还包括:
9、上述的步骤1包括以下子步骤:
10、步骤11:构建四旋翼无人机的姿态动力模型:
11、;
12、其中,为四旋翼无人机姿态角的变化率;
13、为四旋翼无人机姿态角速率的变化率;
14、为四旋翼无人机的姿态角系统的旋转矩阵;
15、、为四旋翼无人机的姿态角速率、转动惯量;
16、为四旋翼无人机的姿态角速率矩阵;
17、为四旋翼无人机的控制力矩;
18、为四旋翼无人机受到的外部有界干扰;
19、步骤12:采用预置性能函数对姿态动力模型建立姿态角状态约束:
20、;
21、其中为i下的四旋翼无人机姿态角;
22、 ,、、分别为滚转角、俯仰角和偏航角,表示下标指代的是滚转角、俯仰角和偏航角中的一个;
23、为预置性能指标函数,满足,;,为常数,满足,为时间变量;
24、为预置性能指标函数的幅值调节参数,满足;
25、步骤13:结合姿态角误差变量,构建满足四旋翼无人机瞬态响应性能要求的姿态跟踪误差模型:
26、;
27、其中,和分别为预置性能跟踪误差向量关于时间的一阶与二阶导数;
28、为姿态角误差变量兼顾四旋翼无人机的状态约束与控制模型,具体为:
29、;
30、为四旋翼无人机姿态角向量,,中间变换变量,其中,辅助姿态角约束变量,为关于时间的一阶导数,为约束姿态角的预置性能指标函数向量,为关于时间的一阶导数,为关于时间的二阶导数,为四旋翼无人机的姿态角系统的旋转矩阵,为四旋翼无人机的姿态角系统的旋转矩阵关于时间的一阶导数,,为引入的中间变量。
31、上述的,与分别为:
32、;
33、其中分别为滚转角速率、俯仰角速率和偏航角速率;、、分别为滚转角、俯仰角和偏航角。
34、上述的为:
35、;
36、其中,表示双曲余割函数,;
37、,和为根据四旋翼无人机的瞬态性能选择的性能参数,,决定四旋翼无人机姿态角运行的初始边界与终点边界,决定四旋翼无人机预置性能函数约束下姿态角的收敛速度。
38、上述的步骤2包括以下子步骤:
39、步骤21:将步骤1构建的姿态跟踪误差模型离散化,得到离散化后的姿态跟踪误差模型:
40、;
41、其中,为基于前向差分法离散化的第步预置性能跟踪误差向量及预置性能跟踪误差向量关于时间的一阶导数;
42、、分别为基于前向差分法离散化的第步预置性能跟踪误差向量及预置性能跟踪误差向量关于时间的一阶导数;
43、为离散化的控制输入力矩;
44、分别为离散化模型的模型矩阵和控制分配矩阵;
45、为离散化后的四旋翼无人机外部有界扰动;
46、步骤22:基于步骤21得到的离散化后的姿态跟踪误差模型中的误差状态量与控制量构造四旋翼无人机的长期代价函数:
47、;
48、其中,为正定函数,反应当前四旋翼无人机姿态角是否发生了越界;
49、为在当前第步基础上,时间向后进行控制性能预测的步数;
50、为离散化后第步的预置性能跟踪误差向量及其一阶导数;
51、为关于的次幂函数值,为折扣因子,满足;
52、为正定矩阵的权重矩阵,平衡四旋翼无人机模型的跟踪误差性能与能量消耗;
53、为离散化后第步的控制输入力矩;
54、为基于前向差分法离散化误差模型的初始时刻;
55、步骤23:根据步骤22的长期代价函数,形成积分强化学习第步的实时奖励函数:
56、;
57、其中,,表示四旋翼无人机姿态模型的输出量;为正定的权重矩阵;为期望的四旋翼无人机姿态角信号。
58、上述的步骤3包括如下子步骤:
59、步骤31:构建四旋翼无人机模型控制行为好坏的评价神经网络:
60、;
61、其中,为理想的评价神经网络的权重矩阵;
62、为期望的长期性能指标函数, 为全是零的向量;
63、为评价神经网络的激活函数;
64、为评价神经网络对期望的长期性能指标函数的估计误差;
65、满足,和 ,均为未知的常数;
66、步骤32:基于评价神经网络对长期代价函数的估计值,构建积分强化学习的误差模型:
67、;
68、其中,为评价神经网络对长期代价函数的估计值,为积分强化学习的误差;
69、步骤33:基于积分强化学习的误差模型与实时奖励函数,建立评价神经网络-动作神经网络积分强化学习控制模型:
70、基于积分强化学习的误差模型,在第步,建立如下的四旋翼无人机姿态角跟踪误差:
71、;
72、其中,和;为期望的四旋翼无人机姿态角跟踪信号;
73、进而,在姿态角跟踪误差的基础上,引入第步的姿态角速率跟踪误差:
74、;
75、依据状态反馈控制律的设计方法,设计理想控制器如下:
76、;
77、其中,为设计的控制增益;
78、引入如下的动作神经网络设计:
79、;
80、其中,为理想的动作神经网络的权重,为动作神经网络的激活函数;
81、动作神经网络的输入定义为;
82、代表动作神经网络中隐层的权重,至此,完成评价神经网络-动作神经网络积分强化学习控制模型建立。
83、上述的步骤4中,评价神经网络的权重更新律设计过程为:
84、对于评价神经网络,引入如下的评价神经网络的近似误差:;
85、其中,神经网络的权重近似误差;为评价神经网络理想权重的估计值;
86、结合bellman迭代方程和经验差分法,积分强化学习的误差进一步演化为:
87、;
88、为最小化长期代价函数,将其映射到如下的误差代价函数中:
89、;
90、进一步,结合离散模型的自适应梯度下降方法,设计如下的评价神经网络权重更新梯度:
91、;
92、其中,,结合链式法则,具体为:
93、;
94、其中,为评价神经网络权重更新律的学习增益;
95、从而可得如下的评价神经网络权重更新律:
96、。
97、上述的步骤4中,动作神经网络的权重更新律设计过程为:
98、针对含有理想权重的动作神经网络,设计如下的神经网络估计策略解决其无法直接应用的问题:
99、;
100、其中,为动作神经网络的输出;
101、,和 ,为未知的常值;
102、进一步,结合四旋翼无人机姿态角速率的跟踪误差,可得:
103、;
104、其中,,为期望的姿态角速率;
105、同时,动作神经网络权重的估计误差定义为;
106、结合四旋翼无人机受到的外部有界干扰和动作神经网络估计误差,将无人机受到的外部有界干扰和动作神经网络估计误差引起的四旋翼无人机姿态角跟踪误差定义为;
107、进一步,引入动作神经网络的估计误差,结合最小化评价神经网络输出的目的,设计如下的动作神经网络误差:
108、;
109、其中,,为理想评价神经网络的输出的估计值;
110、根据最小化动作神经网络误差的目标,引入二次型误差,结合链式法则,动作神经网络权重的更新梯度设计为:
111、;
112、进一步,可得动作神经网络权重更新律:
113、。
114、本发明具有以下有益效果:
115、本发明针对四旋翼无人机姿态控制模型面临的严格瞬态响应性能要求,通过预置性能函数来度量四旋翼无人机姿态的跟踪误差,将具有性能约束的跟踪误差动态转化为等效的“状态约束”模型;进一步,构造基于积分强化学习的性能指标函数,平衡四旋翼无人机姿态控制的长期最优性能与灵活的瞬态响应性能;而后,通过设计以最小化姿态长期性能与瞬态性能代价函数为目标的动作神网络,构成评价神经网络-动作神经网络自适应神经网络控制架构下的积分强化学习预置性能四旋翼无人机姿态控制器,本发明基于预置性能控制技术和积分强化学习控制技术,使得四旋翼无人机能够在未知空气动力学参数、输入约束和外部干扰的情况下,实现准确的姿态跟踪,并满足规定的性能要求,提高了四旋翼无人机运行的自主性与可靠性。
116、本发明基于强化学习的四旋翼无人机预置性能跟踪控制方法中建立融合预置性能控制与积分强化学习的融合应用框架,一方面能够保证提高四旋翼无人机的瞬态性能、系统闭环稳定和输出跟踪,另一方面能够提高四旋翼无人机的自主性、对新场景的适应性,基于预置性能积分强化学习自适应神经网络跟踪控制框架具有简单的结构,因此易于实现。
- 还没有人留言评论。精彩留言会获得点赞!