一种飞行巡逻机器人路径规划方法及其系统与流程
本发明涉及路径规划,具体涉及一种飞行巡逻机器人路径规划方法及其系统。
背景技术:
1、随着社会经济技术的发展,机器人技术的普及应用为人类生活带来了极大便利,拥有自主能力的移动机器人一方面降低了人类工作的成本,另一方面也为人类提供了更加丰富全面的信息资源。飞行巡逻机器人作为近年来移动机器人领域的研究热点,其自身的自主性能也在不断提高。路径规划作为移动机器人典型的自主能力,一直是机器人领域的研究热点,其中飞行巡逻机器人在复杂环境下的自主路径规划能力是飞行巡逻机器人发展的核心研究内容。目前飞行巡逻机器人路径规划的研究通常集中在室外空旷环境,相对而言室内环境空间更加狭小,边界条件多,避障难度大,因此对飞行巡逻机器人的精准避障及规划的实时性提出了更大的挑战。近年来国内也开始引进或研发室内飞行巡逻机器人飞行实验系统,在此背景下研究室内飞行巡逻机器人的路径规划算法,实现飞行巡逻机器人在室内复杂环境中的实时动态路径决策和引导功能,并利用现有技术平台进行实验验证,将为飞行巡逻机器人室内智能自主导航技术奠定坚实的基础,具有重要的理论研究意义及应用参考价值。
2、其中,路径规划是指飞行巡逻机器人在一定的环境下,给定该机器人的起点和目标点,通过一些算法、控制、优化方法等来寻找一条安全、动态可行、最优的路径,使飞行巡逻机器人从起点飞向目标点。到目前为止,路径规划算法已经得到了深入的研究,并且提出了各种各样不同的路径规划算法,如人工势场法、智能仿生算法、基于网格的搜索算法和基于采样的算法。
3、基于采样的算法不需要显式构建配置空间,例如众所周知的快速探索随机树(rrt)算法,该算法通过迭代添加随机节点来绘制边缘,并使用碰撞检测方法来验证边缘的有效性,此外,它在高维配置空间中具有优越的性能,同时rrt算法提供了概率完整性,它确保当迭代次数趋于无穷大时,找到可行路径的概率接近1。然而,传统的rrt算法有一些局限性,如收敛速度低和路径质量波动,许多研究人员对rrt算法进行了改进。例如,kuffner等人通过在rrt算法中引入贪婪启发式采样,提出了rrt-connect算法,与传统的rrt算法相比,rrt-connect算法增量地构建两个同时起源于起始状态和目标状态的快速探索随机树,为了提高算法的搜索效率,这些树中的每一棵都使用简单的贪婪启发式算法向其对应的树前进。也有学者提出了一种基于三角不等式的rrt连接重新布线方法,该算法缩短了规划时间,同时也通过重新布线来寻求优化,尽管rrt-connect显示出良好的搜索环境的能力,但与rrt算法类似,rrt-connect的路径质量不稳定,无法保证最优。为了解决rrt不考虑可行解成本的问题,karaman等人提出了考虑路径成本的rrt*算法,rrt*算法具有渐近最优性,同时继承了rrt算法的概率完备性,它可以在更短的时间内获得高质量的可行路径,但是,它的搜索效率很低。其中,本技术所述的rrt*算法是基于采样的算法,而rrt*算法自身存在上述不足之处。为了进一步提高rrt*算法的性能,nasir等人提出了rrt*智能算法,该算法通过引入智能采样和路径优化技术来帮助接近最优或次优解,比rrt*具有更快的收敛速度,此外,当找到更好的路径时,优化路径的顶点将成为有偏采样的源。然而,随着算法的不断迭代,节点数量无限增加,这对计算机内存是一个重大挑战,为了更有效地使用内存,adiyatov等人提出了rrt*-fn算法,该算法限制了树中节点的最大数量,并在节点数量超过预设值时删除了对优化路径没有帮助的无用节点,这减少了计算机的内存使用,并加快了对相邻节点的搜索。受节点限制的启发,gammell等人提出了informed rrt*算法,该算法通过生成超椭球采样子集来限制节点采样的范围,并在超椭球子集中进行直接采样,以提高算法的收敛速度和最终解的质量,然而,这种算法有一些局限性,事实上,在一些特殊的环境中,如狭窄的室内长走廊和迷宫,由于路径成本大,超椭球采样面积可能过大,甚至整个配置空间都被超椭球包含在内,在这种情况下,informed rrt*的性能与rrt*类似。有的研究人员通过改变树的生长策略,提出了基于三角不等式的quick rrt*算法,这通过在选择最优父节点时考虑相邻节点的父节点来提高算法的收敛速度,然而quick rrt*在诸如狭窄环境之类的特殊环境中是无效的,这又需要对算法继续进行改进。因此,针对上述现有技术的不足有必要进行改进。
技术实现思路
1、本发明主要解决的技术问题是提供一种飞行巡逻机器人路径规划方法及其系统,以提高了rrt*算法在飞行巡逻机器人室内特殊环境下的路径搜索效率。
2、根据第一方面,一种实施例中提供一种飞行巡逻机器人路径规划方法。该飞行巡逻机器人路径规划方法包括:
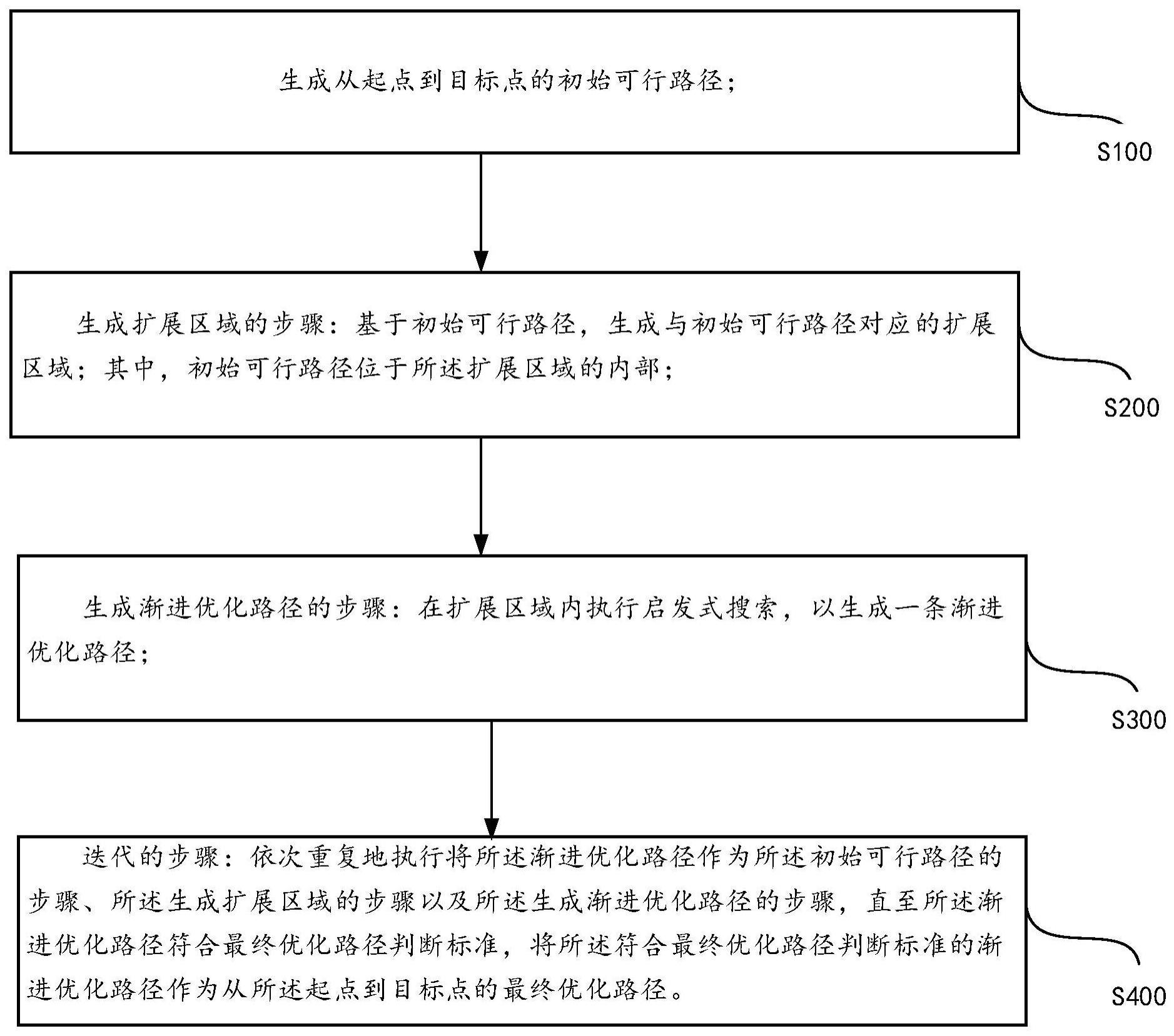
3、生成从起点到目标点的初始可行路径;
4、生成扩展区域的步骤:基于所述初始可行路径,生成与所述初始可行路径对应的扩展区域;其中,所述初始可行路径位于所述扩展区域的内部;
5、生成渐进优化路径的步骤:在所述扩展区域内执行启发式搜索,以生成一条渐进优化路径;
6、迭代的步骤:依次重复地执行将所述渐进优化路径作为所述初始可行路径的步骤、所述生成扩展区域的步骤以及所述生成渐进优化路径的步骤,直至所述渐进优化路径符合最终优化路径判断标准,将所述符合最终优化路径判断标准的渐进优化路径作为从所述起点到目标点的最终优化路径。
7、一实施例中,基于所述初始可行路径,生成与所述初始可行路径对应的扩展区域,包括:
8、获取与所述初始可行路径中的子路径段对应的子扩展区域;
9、基于所述初始可行路径中的子路径段,将与所述初始可行路径中的子路径段对应的子扩展区域进行拼接,以得到所述与所述初始可行路径对应的扩展区域。
10、一实施例中,所述获取与所述初始可行路径中的子路径段对应的子扩展区域,包括:
11、以所述初始可行路径中所述子路径段的邻接点为子路径段顶点,基于与所述子路径段顶点对应的第一子路径段向量和第二子路径段向量确定由所述子路径段顶点指向所述初始可行路径的一侧的方向向量;其中,所述初始可行路径由若干所述子路径段彼此首尾连接而成;所述第一子路径段向量和第二子路径段向量是以所述子路径段顶点为邻接点的第一子路径段和第二子路径段所分别对应的向量;
12、基于实际膨胀距离、所述子路径段顶点和所述方向向量,确定与所述子路径段顶点对应的第一子扩展区域顶点和第二子扩展区域顶点;其中,每个所述子扩展区域对应两个所述第一子扩展区域顶点和两个所述第二子扩展区域顶点,所述第一子扩展区域顶点和第二子扩展区域顶点均作为所述子扩展区域的顶点;所述实际膨胀距离为由所述子路径段顶点沿所述方向向量延伸的距离;
13、将由所述子扩展区域对应的两个所述第一子扩展区域顶点和两个所述第二子扩展区域顶点所围成的区域作为所述子扩展区域。
14、一实施例中,所述与所述子路径段顶点对应的第一子扩展区域顶点所对应的向量和第二子扩展区域顶点所对应的向量的表达式分别为:
15、
16、
17、其中,所述表示所述子路径段顶点所对应的向量,i表示所述子路径段顶点的编号,所述表示所述由所述子路径段顶点指向所述初始可行路径的一侧的方向向量,所述d表示所述实际膨胀距离,所述θi是所述与所述子路径段顶点对应的第一子路径段向量和第二子路径段向量之间的夹角的一半。
18、一实施例中,所述实际膨胀距离d的表达式为:
19、d=k*dbase,
20、其中,所述k为动态扩展系数,所述dbase为初始扩展距离;所述k的取值范围为0.75至1.25。
21、一实施例中,所述动态扩展系数k的表达式为:
22、
23、其中,所述i表示当前的迭代次数;所述iinit表示生成所述初始可行路径时所完成的迭代次数;n表示预设的最大迭代次数。
24、一实施例中,所述初始扩展距离dbase的表达式为:
25、
26、其中,所述ε表示初始扩展系数,所述l和w分别表示与所述初始可行路径对应的环境平面的长度和宽度。
27、根据第二方面,一种实施例中提供一种改进rrt*的飞行巡逻机器人路径规划系统。该飞行巡逻机器人路径规划系统包括:
28、传感器模块,被配置为获取飞行巡逻机器人的环境数据;
29、飞控模块,被配置为接收所述飞行巡逻机器人的环境数据,基于所述飞行巡逻机器人的环境数据计算得出所述飞行巡逻机器人的位置和姿态,
30、路径规划模块,被配置为所述飞控模块所计算得出所述飞行巡逻机器人的位置和姿态,利用如本文中任一项实施例所述的飞行巡逻机器人路径规划方法生成从所述起点到目标点的最终优化路径;其中,所述飞控模块能够根据所述飞行巡逻机器人的位置和姿态以及所述最终优化路径对所述飞行巡逻机器人进行控制。
31、一实施例中,所述环境数据包括:超声波测距雷达和激光测距雷达所获得飞行巡逻机器人周围的障碍物距离和角度数据、光流传感器所获得飞行巡逻机器人运动的速度数据、三轴陀螺仪所获得飞行巡逻机器人的角速度和角加速度数据、三轴加速度计所获得飞行巡逻机器人的加速度数据、三轴磁力计所获得飞行巡逻机器人的航向数据和气压计所获得飞行巡逻机器人的飞行高度数据中的多个或全部。
32、根据第三方面,一种实施例中提供一种计算机可读存储介质。该介质包括程序,所述程序能够被处理器执行以实现如本文中任一项实施例所述的飞行巡逻机器人路径规划方法。
33、本技术的有益效果是:
34、本飞行巡逻机器人路径规划方法包括:生成从起点到目标点的初始可行路径;生成扩展区域的步骤:基于所述初始可行路径,生成与所述初始可行路径对应的扩展区域;其中,所述初始可行路径位于所述扩展区域的内部;生成渐进优化路径的步骤:在所述扩展区域内执行启发式搜索,以生成一条渐进优化路径;迭代的步骤:依次重复地执行将所述渐进优化路径作为所述初始可行路径的步骤、所述生成扩展区域的步骤以及所述生成渐进优化路径的步骤,直至所述渐进优化路径符合最终优化路径判断标准,将所述符合最终优化路径判断标准的渐进优化路径作为从所述起点到目标点的最终优化路径,进而提高了rrt*算法在飞行巡逻机器人室内特殊环境下的路径搜索效率。
- 还没有人留言评论。精彩留言会获得点赞!