一种基于多深度相机的移动机器人避障方法与流程
本发明涉及机器人避障领域,尤其是涉及一种基于多深度相机的移动机器人避障方法。
背景技术:
1、近年来,随着机器人行业的蓬勃发展,移动机器人开始广泛地应用在工业、农业、国防、服务等行业中。同时,这也对机器人提出了挑战,需要机器人能够在各种复杂的动态环境中自主执行导航的作用。机器人导航的一个关键方面是避障,它确保机器人在障碍物存在的情况下安全高效地移动。
2、目前机器人中,主要使用2d激光雷达传感器进行避障,对于悬空或者低矮等空间障碍物缺乏处理能力,导致相撞。即使对于一些使用深度相机避障的方案而言,存在着相机覆盖视角比较小,多相机部署麻烦等问题。另外,由于深度相机获取的是三维空间信息,无法直接与2d激光雷达的障碍物信息进行融合,如果直接使用三维信息去避障又会对处理性能的要求比较高,算法复杂度也会剧增。同时,对于一些采用深度相机3d避障的方法,丢失了很多语义的信息,对资源造成了一定的浪费。
3、因此,亟需设计一种可对悬空或者低矮等空间障碍物进行有效避障、部署便捷、兼具避障准确性和实时性的移动机器人避障方法。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供了一种可对悬空或者低矮等空间障碍物进行有效避障、部署便捷、兼具避障准确性和实时性的基于多深度相机的移动机器人避障方法。
2、本发明的目的可以通过以下技术方案来实现:
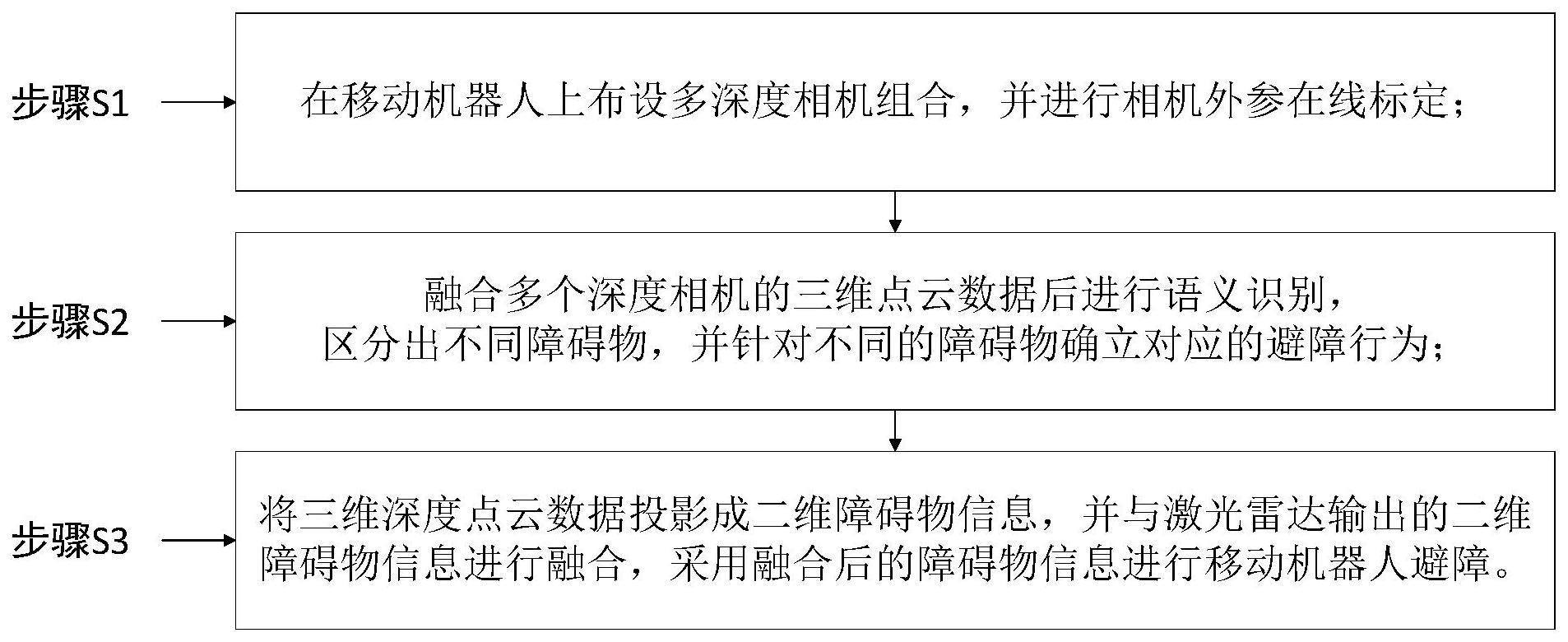
3、本发明提供了一种基于多深度相机的移动机器人避障方法,该方法包括以下步骤:
4、步骤s1、在移动机器人上布设多深度相机组合,并进行相机外参在线标定;
5、步骤s2、融合多个深度相机的三维点云数据后进行语义识别,区分出不同障碍物,并针对不同的障碍物确立对应的避障行为;
6、步骤s3、将三维深度点云数据投影成二维障碍物信息,并与激光雷达输出的二维障碍物信息进行融合,采用融合后的障碍物信息进行移动机器人避障。
7、优选地,所述相机外参为深度相机相对于移动机器人底盘坐标系的安装位置信息。
8、优选地,所述深度相机的数量至少为三。
9、优选地,所述相机外参在线标定,具体为:仅计算多深度相机组合中一个深度相机的位置,基于多深度相机间视野存在一定共识范围条件,进行剩余深度相机的外参标定。
10、优选地,所述仅计算多深度相机组合中一个深度相机的位置,基于多深度相机间视野存在一定共识范围条件,进行剩余深度相机的外参标定,具体包括以下子步骤:
11、1)选定任意一个深度相机作为基准深度相机,根据结构图测量出所述基准深度相机相对于移动机器人底盘坐标系的外参;
12、2)获取所有深度相机的三维点云数据;
13、3)使用特征提取算法从所有的三维点云数据中提取特征点,并对提取的特征点进行特征描述子计算;
14、4)对任一个剩余深度相机点云的特征点与基准深度相机点云的特征点进行特征匹配,找到匹配的特征点对,计算出两个点云之间的初始旋转矩阵;
15、5)采用迭代最近点icp算法优化旋转矩阵,得到当前深度相机点云相对于基准深度相机点云的旋转变换矩阵;其中,icp算法通过迭代最小化点云之间的距离度量来优化旋转矩阵的估计;
16、6)基于基准深度相机外参、以及当前深度相机点云相对于基准深度相机点云的旋转矩阵,计算出当前深度相机的外参;
17、7)重复步骤4)~6),遍历得到所有深度相机的外参数。
18、优选地,所述步骤s2包括以下子步骤:
19、步骤s21、根据深度相机当前观测的深度图像和深度相机内参,转化二维像素为深度点云,然后根据深度相机外参,将所有深度相机的三维点云数据统一至同一坐标系下;
20、步骤s22、通过高度阈值进行点云筛选,滤除地面点云;
21、步骤s23、对点云进行障碍物分割得到行人信息,根据不同语义信息做出不同的避障逻辑。
22、优选地,所述步骤s22中通过高度阈值进行点云筛选,滤除地面点云,具体为:
23、对筛选后的点云计算每个点的表面法向量,并设置阈值,将法向量接近垂直于竖直方向的点视为地面点,以滤除地面点云。
24、优选地,所述步骤s23中根据不同语义信息做出不同的避障逻辑,具体为:
25、对于行人类障碍物,机器人在避障时,优先等待一下并播报提醒语音,待行人离开或一定时间后再继续行驶,而其它的障碍物则快速重新规划路径绕开;
26、对于静态障碍物,在多次检测到后添加到路径规划记忆中。
27、优选地,所述步骤s3包括以下子步骤:
28、步骤s31、将步骤s2处理后的三维点云数据投影成二维代价地图;
29、步骤s32、将当前激光雷达观测形成的二维代价地图以及深度点云投影生成的二维代价地图进行融合,合并得到一张机器人避障使用的代价地图。
30、优选地,所述步骤s32中,还包括:判断深度障碍物点附近是否存在激光雷达的障碍物信息,如有选择激光雷达观测的信息。
31、与现有技术相比,本发明具有以下有益效果:
32、1)本发明通过多个深度相机组合,全方位覆盖机器人的移动视角,减少机器人的盲区,提升对悬空以及低矮障碍物的处理效果;对于多个相机组合,提出多相机外参的在线标定,简化深度相机的部署流程。
33、2)本发明通过融合多个相机的点云数据,进行语义的识别,区分出地面、行人等语义信息,针对不同的语义,做出不同的避障行为,让机器人变得更加智能。
34、3)本发明将三维深度点云数据进行投影,得到机器人使用的二维障碍物信息,降低算法的复杂度以及处理性能的要求;同时为了提升深度信息的精确性,将之与二维雷达障碍物信息进行有效融合,达到互补的作用,保证机器人行走的流畅度。
技术特征:
1.一种基于多深度相机的移动机器人避障方法,其特征在于,该方法包括以下步骤:
2.根据权利要求1所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述相机外参为深度相机相对于移动机器人底盘坐标系的安装位置信息。
3.根据权利要求1所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述深度相机的数量至少为三。
4.根据权利要求1所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述相机外参在线标定,具体为:仅计算多深度相机组合中一个深度相机的位置,基于多深度相机间视野存在一定共识范围条件,进行剩余深度相机的外参标定。
5.根据权利要求4所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述仅计算多深度相机组合中一个深度相机的位置,基于多深度相机间视野存在一定共识范围条件,进行剩余深度相机的外参标定,具体包括以下子步骤:
6.根据权利要求3所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述步骤s2包括以下子步骤:
7.根据权利要求6所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述步骤s22中通过高度阈值进行点云筛选,滤除地面点云,具体为:
8.根据权利要求6所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述步骤s23中根据不同语义信息做出不同的避障逻辑,具体为:
9.根据权利要求1所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述步骤s3包括以下子步骤:
10.根据权利要求9所述的一种基于多深度相机的移动机器人避障方法,其特征在于,所述步骤s32中,还包括:判断深度障碍物点附近是否存在激光雷达的障碍物信息,如有选择激光雷达观测的信息。
技术总结
本发明涉及一种基于多深度相机的移动机器人避障方法,该方法包括以下步骤:步骤S1、在移动机器人上布设多深度相机组合,并进行相机外参在线标定;步骤S2、融合多个深度相机的三维点云数据后进行语义识别,区分出不同障碍物,并针对不同的障碍物确立对应的避障行为;步骤S3、将三维深度点云数据投影成二维障碍物信息,并与激光雷达输出的二维障碍物信息进行融合,采用融合后的障碍物信息进行移动机器人避障。与现有技术相比,本发明提升了对悬空及低矮障碍物的避障效果,避障流畅性更好,且部署更为简便。
技术研发人员:谷桐,王小挺,庞梁,白静
受保护的技术使用者:上海思岚科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!