一种基于深度强化学习的金属酸洗混合流水车间调度方法
本发明涉及一种基于深度强化学习的金属酸洗混合流水车间调度方法,属于制造业生产计划领域。
背景技术:
1、金属酸洗是金属制造业中重要的预处理环节,其生产调度直接影响到生产效率和产品质量,而且冶金属于高能耗产业,其生产过程中产生的能源浪费及环境污染不可忽视。然而,传统的车间调度方法往往基于规则和经验,难以适应生产环境的动态变化,且缺乏智能化的决策能力。因此,需要一种新的、基于现代人工智能技术的车间调度方法来解决这一问题。
2、金属酸洗过程是顺序决定能源消耗的混合流水车间调度问题,顺序依赖可近似为非对称旅行商问题(atsp),atsp问题的输入是一个边带权的完全图,目标是找一个权值和最小的哈密顿回路。atsp被证明是np难解问题,即没有多项式时间复杂度的算法,在有限时间内很难得到最优解。精确算法能够得到最优解,但求解时间长,数学证明复杂,不适用于大规模问题。启发式算法容易陷入局部最优且算法设计困难,在atsp问题上通用性差。
3、由于顺序依赖的混合流水车间调度问题数学求解复杂,算法设计困难等问题,使用强化学习方法更具可行性。强化学习中的基本定义包括智能体、环境、动作、状态、奖励函数、马尔可夫(markov)过程、马尔可夫奖励过程和马尔可夫决策过程(mdp),马尔科夫奖励过程和价值函数估计的结合产生了强化学习方法中应用的核心结果——贝尔曼方程,最优价值函数和最优策略可以通过求解贝尔曼方程得到。贝尔曼方程传统求解方法主要有:动态规划(dynamic programming)、蒙特卡罗(monte-carlo)方法和时间差分(temporaldifference)方法。强化学习是通过智能体与环境交互,更新策略,智能体不断学习决策的过程,深度学习与强化学习结合使得强化学习在解决大规模问题上更具适应性,对求解工业级调度问题具有广阔的应用前景。
4、针对顺序依赖的混合流水车间调度问题,前人使用精确方法和启发式方法具有数学证明复杂,算法设计困难,求解时间过长等问题,亟需一种快速有效的方法求解金属酸洗车间调度问题。策略梯度方法(policy gradient methods)是一类直接针对期望回报(expected return)通过梯度下降(gradient descent)进行策略优化的增强学习方法。该方法直接学习参数化策略πθ,避免了传统强化学习方法在面对无准确价值函数或状态信息不确定时的难解性。
技术实现思路
1、本发明的目的是提供一种基于深度强化学习的金属酸洗混合流水车间调度方法,特别是一种顺序依赖的流水车间调度方法,以最小化最大完工时间和能耗为优化目标,通过使用近端策略优化算法,训练智能决策模型,实现对金属酸洗车间过程的节能优化调度。
2、本发明的技术方案是:本发明提供了一种基于深度强化学习的金属酸洗混合流水车间调度方法,以最小化工期和能耗为优化目标,结合神经网络和强化学习,学习参数化的策略,调度决策候选行为从已有的调度知识和经验规则提炼,结合强化学习在线评价-执行机制,从而为调度系统的每次调度决策选取最优行为策略。
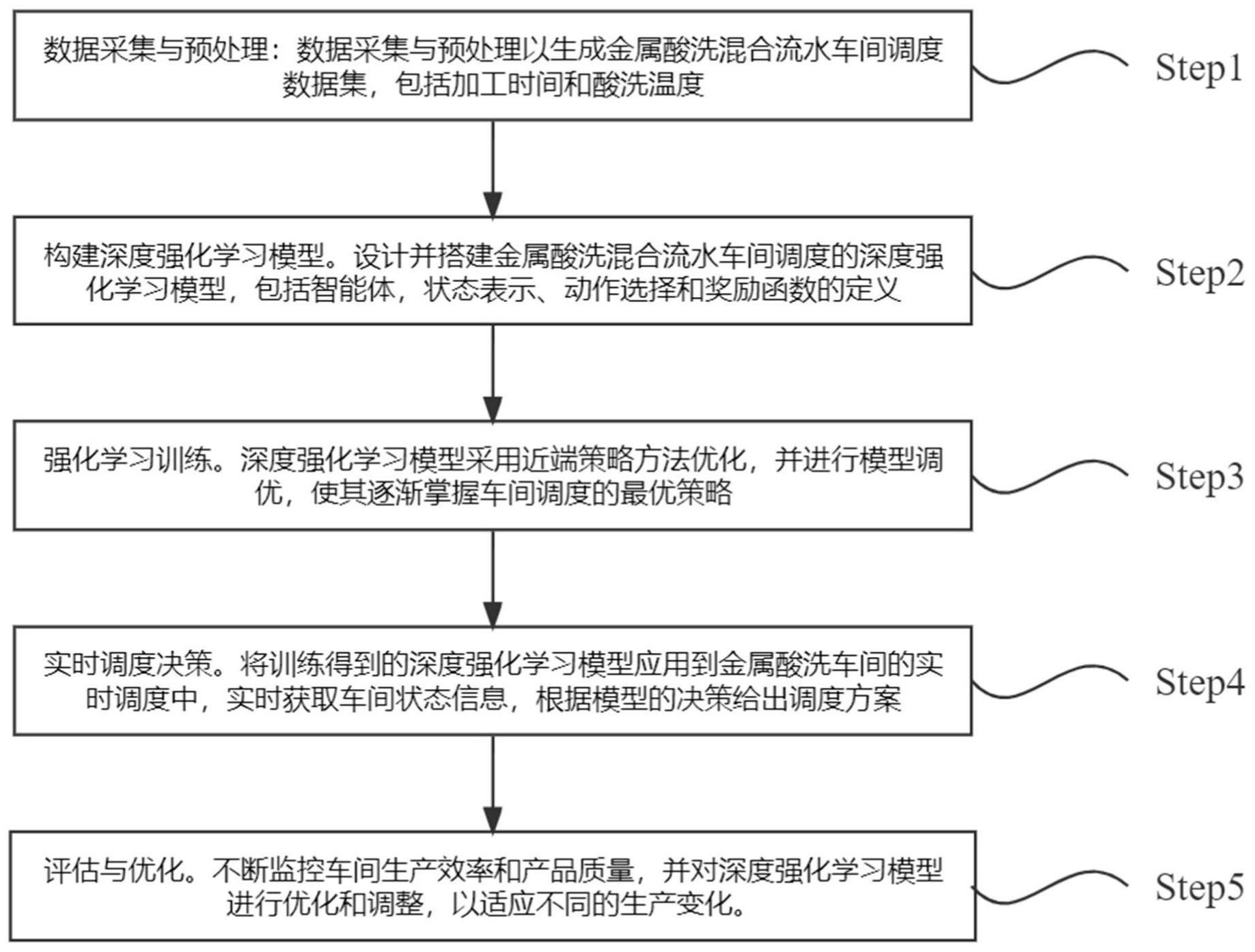
3、进一步地,所述方法具体包括如下步骤:
4、step1、数据采集与预处理:数据采集与预处理以生成金属酸洗混合流水车间调度数据集,包括加工时间和酸洗温度;
5、所述step1中,数据采集包括采集机器平均使用率,标准偏差,作业完成率,操作完成率,加工时间,酸洗液温度,预处理包括根据加工时间和酸洗温度上下界生成调度数据集,根据冶金车间的实际数据生成的随机算例作为参数实验的算例,为寻找较优的方法参数。
6、所述step 1中包括:
7、(1):所述金属酸洗流水车间问题数据集{d},其中工件数记为j和机器数记为m,阶段数为n,子任务在机器上处理时间的上界a与下界b,子任务在机器上处理温度上界d与下界c,指定生成数据的随机seed种子值;
8、(2):根据seed种子和上、下界值随机生成每个工件在每台机器上的处理时间和处理温度;
9、(3):多次执行步骤1.2,产生的数据集记为带温度的流水车间调度数据集{d}。
10、step2、构建深度强化学习模型:设计并搭建金属酸洗混合流水车间调度的深度强化学习模型,包括智能体,状态表示、动作选择和奖励函数的定义;
11、step3、强化学习训练:使用采集到的数据对深度强化学习模型进行训练,并进行模型调优,使其逐渐掌握车间调度的最优策略;
12、step4、实时调度决策:将训练得到的深度强化学习模型应用到金属酸洗车间的实时调度中,实时获取车间状态信息,根据模型的决策给出调度方案;
13、step5、评估与优化:不断监控车间生产效率和产品质量,并对深度强化学习模型进行优化和调整,以适应不同的生产变化。
14、进一步地,所述step2中,设计并搭建金属酸洗混合流水车间调度的深度强化学习模型,所述深度强化学习模型,是将金属酸洗混合流水车间调度问题描述为马尔科夫决策过程,强化学习的常见模型是标准的马尔可夫决策过程,金属酸洗混合流水车间调度即可使用强化学习求解;强化学习模型四要素包括智能体,环境,动作,奖励;金属酸洗为顺序依赖的混合流水车间调度问题,把生产计划输入到深度强化学习模型中,其中待加工工件集合对应强化学习中的智能体,车间动态生产环境对应强化学习中的环境,工件选择对应强化学习中为每个步长智能体选择动作,能耗和最大完工时间对应强化学习的奖励,设置奖励函数与能耗和最大完工时间呈负相关;所述金属酸洗混合流水车间调度问题为金属酸洗过程,是顺序决定能源消耗的混合流水车间调度问题,是可近似为非对称旅行商问题的车间调度问题。
15、进一步地,所述step2中,深度强化学习模型的数学模型表示如下:
16、目标函数:
17、minimize(cmax,qi) (1)
18、总的能源消耗qi:
19、
20、
21、
22、s.t.
23、
24、
25、
26、cji=stji+pjim,j=1,...,n;i=1,...i (8)
27、cji≤stj(i+1),j=1,...,n;i=1,...i (9)
28、stji=max(cj(i-1),pkjimcki) (10)
29、
30、决策变量:
31、
32、
33、其中,cmax表示最大完工时间,cjim表示钛带j在工序i的机器m操作完成时间,qi表示总的能源消耗,qijk表示钛带j在工序k机器i上微波加热的能耗,ak,bj表示钛带k和钛带j的温度参数;x,y表示决策变量,j,k表示工件索引,i表示工序索引,m表示工序i的机器索引1≤m≤mi,n表示工件总数量,i表示工序总数量,xjl表示工件j被安排在第l个位置,mi表示工序i的机器总数量,pjim(1≤i≤i,1≤j≤n,1≤m≤mi)表示钛带j在第i工序上机器m加工的时间,yjim表示工序i时工件j在机器m上加工,cji表示工件j在工序i上完工时间,stji表示工件j在工序i的开始加工时间,pjim表示工件j在工序i的机器m的操作时间,cj(i-1)表示工件j在工序i-1上完工时间,pkjimcki表示工序i的机器m上工件k在工件j前加工,工件k在工序i上完工时间,xjlstji表示工件j被安排到第l个位置工件j在工序i上的操作时间,xj(l+1)stji表示工件j被安排到第l+1个位置工件j在工序i上的操作时间;
34、公式(1)表示调度指标,公式(5)和公式(6)保证调度为所有钛带的一个完全排列,公式(7)表示任意钛带j在任一工序上只能在一台机器上加工;公式(8)表示钛带j在工序i的完工时间等于该钛带的开始时间加上在该工序的机器上的加工时间,完成时间和开始时间的关系;公式(9)表示同一钛带在进行下一道工序时必须完成当前工序;公式(10)表示钛带j的可开始加工时间stji为上个工序i-1完工时间与j的上个钛带k在此工序的完工时间最大值;公式(11)表示排列调度中排位约靠前的工件开始处理的时间越早。
35、进一步地,所述step3中,深度强化学习模型采用近端策略优化方法进行优化,该方法是直接学习参数化的策略,不需要在动作空间求解价值最大化的优化问题,适合高纬度或连续动作空间的问题。
36、进一步地,所述step3的过程如下:
37、step3.1、初始化三个网络,包括actor网络,actor_old网络和critic网络;所述actor网络用于选择动作,需要训练更新、梯度反向传播,actor_old网络用于复制actor网络参数,无需梯度反向传播,critic网络用于计算状态价值,需要训练更新,梯度反向传播;初始化超参数,截断因子∈,用于限制策略梯度更新的幅度;
38、step3.2、输入初始策略参数θ、初始价值函数φ,将actor网络参数复制到actor_old网络,输入一个batch_size的状态s,actor_old网络输出old动作概率密度函数的均值μ和方差σ,dist_old=normal(μ_old,σ_old),从dist_old正态分布计算old_action的log概率密度值;
39、step3.3、在环境中执行策略πθ,并保存轨迹集dk={τi};
40、step3.4、计算将得到的奖励
41、step3.5、基于当前的价值函数vφk,计算优势函数所述优势函数为:
42、
43、step3.6、对于每次迭代,输入一个batch_size的当前状态s,actor网络输出new_action概率密度函数的均值μ和方差σ,输出动作概率密度函数正态分布dist=normal(μ,σ),从dist正态分布计算new_action的log概率密度值;
44、step3.7、采用adam随机梯度上升算法最大化ppo-clip的目标函数来更新策略;更新actor网络,clip算法计算actor网络的损失;所述策略更新:
45、
46、所述clip算法,神经网络参数更新方式如下:
47、
48、step3.8、向critic网络输入一个batch_size的当前状态s,输出状态价值,计算critic网络的损失,所述critic网络的损失使用梯度下降算法最小化均方误差来拟合价值函数:
49、
50、进一步地,所述的近端策略优化方法采用adam随机梯度上升算法最大化ppo-clip的目标函数来更新策略。
51、本发明的有益效果是:
52、1、本发明通过引入基于近端策略优化深度强化学习方法,直接学习参数化的策略,不需要在动作空间求解价值最大化的优化问题,从而解决高纬度或连续动作空间的问题。
53、2、本发明基于近端策略优化深度强化学习的车间调度方法结合了车间生产的实际需求和工艺特点,优化金属酸洗车间的生产调度策略,实现车间资源的高效利用和生产效率的提升。
- 还没有人留言评论。精彩留言会获得点赞!