一种迭代学习自抗扰控制方法
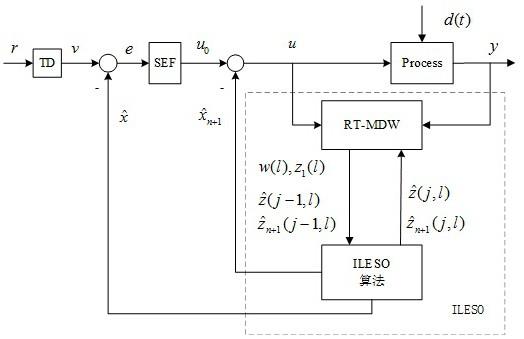
本发明涉及自抗扰控制的,尤其是指一种迭代学习自抗扰控制方法。
背景技术:
1、自抗扰控制(active disturbance rejection control, adrc)方法是我国著名学者韩京清研究员提出来的具有普适性的控制方法。自抗扰控制器由跟踪微分器(tracking differentiator, td)、扩张状态观测器(extended state observer, eso)和状态误差反馈器(state error feedback, sef)组成,其中扩张状态观测器(eso)是自抗扰控制的核心。
2、其中,eso的带宽的选取对自抗扰控制的抗扰能力和对随机噪声的滤波能力影响极大。大量实际应用表明,eso带宽取较大的值,会出现较严重的初始峰值现象,较大的带宽对于测量噪声滤波效果也是不好的;如果取小了,很难实现对总扰动的良好估计。如何动态选择eso带宽一直是adrc应用中长期存在的一个问题。此外,受到模数转换器等硬件速度的限制,采用周期也不能太小。在保证eso对总扰动估计性能前提下,降低数字控制的采样频率是实现低成本自动化的关键技术之一。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提出了一种迭代学习自抗扰控制方法,充分利用历史数据,把近期测量到的历史数据组成一个实时移动数据窗,当最新测量数据进来之后,移除最早的测量数据,然后在实时移动数据窗上运行迭代学习ileso算法,实现对系统总扰动的在实时移动数据窗上的迭代学习辨识,从而得到被控系统总扰动的实时估计;当满足一定的学习误差要求或者下一次采样时刻即将到来时之前,结束本次的迭代学习自抗扰控制,进入下一次采样,重复上述过程,该迭代学习eso可以得到系统总扰动的良好估计,结合td和sef可以实现一种基于迭代学习eso的自抗扰控制方法。通过动态调整迭代eso的迭代学习次数,可以得到时变的eso带宽并极大减少或者消除eso的初值峰值现象。
2、本发明的目的通过下述技术方案实现:一种迭代学习自抗扰控制方法,该方法是在自抗扰控制器adrc中引入迭代学习扩张状态观测器ileso,将迭代学习扩张状态观测器ileso替代自抗扰控制器adrc中原有的扩张状态观测器eso,并结合自抗扰控制器adrc中原有的跟踪微分器td和状态误差反馈器sef进行控制计算;其中,迭代学习扩张状态观测器ileso包括ileso算法和实时移动数据窗rt-mdw,通过在实时移动数据窗rt-mdw运行ileso算法进行迭代学习,输出迭代学习过程的状态变量和扩张状态变量到状态误差反馈器sef中,从而实现对被控系统总扰动的低延时估计,同时由实时移动数据窗rt-mdw实现存储预设长度的采样数据以及迭代学习过程的状态变量和扩张状态变量。
3、进一步,所述迭代学习扩张状态观测器ileso执行以下步骤:
4、定义一个一段采样区间多个数据对(,)组成的实时移动数据窗rt-mdw为如下(1)式:
5、(,;,;…;,) (1);
6、其中,为实时移动数据窗rt-mdw的个数,k为采样次数,通过迭代学习方法来多次重复利用实时移动数据窗rt-mdw中的采样数据,按照实时移动数据窗的大小对相关变量进行重新表示,=,=,,并用二维形式分别表示ileso状态估计和扩张状态估计;
7、ileso执行正向迭代学习机制,正向非线性ileso算法表示为如下(2)式,正向线性ileso算法表示为如下(3)式,其中,j为实时移动数据窗中的迭代次数,nc为迭代学习最大次数;当迭代运行次数达到迭代学习最大次数nc,结束迭代学习;或采用估计误差的绝对值来结束本次迭代学习过程,即当时,为预设的正数,退出本次采用周期的迭代学习;
8、(2);
9、式中,为数据窗口的个数;为被控系统的阶次;为采样周期;为符号函数;,,…,和为使ileso稳定的正常数,采用带宽法来整定;是迭代学习滤波系数,;是迭代学习前馈系数,;是迭代学习反馈系数,;(2)式中给出了fal()函数的定义,是估计误差,是fal()函数中线性段和非线性段的分界点;是fal()函数中的指数,表示非线性的程度;当=1,fal()函数为线性函数,越远离1,非线性程度越大;
10、当=1,得到线性ileso算法:
11、 (3);
12、ileso亦执行逆向迭代学习机制,逆向非线性ileso算法表示为如下式(4),逆向线性ileso算法表示为如下式(5):
13、 (4);
14、逆向线性ileso算法是逆向非线性ileso算法当=1时的线性形式:
15、 (5);
16、正向ileso算法和逆向ileso算法交替进行,先进行正向ileso算法,后进行逆向ileso算法,如此交替迭代,并把所得到的当前采样时刻的ileso输出作为被控系统状态的估计和被控系统扩张状态的估计,如式(6)所示:
17、(6)。
18、进一步,所述状态误差反馈器sef执行以下步骤:
19、采用线性状态误差反馈器sef时,adrc的控制量u(k)计算为如下(7)式:
20、 (7);
21、其中,,,…,为使闭环系统稳定的正常数,采用带宽法来整定;k为采样次数,为被控系统状态的估计,为被控系统扩张状态的估计,为控制增益的估计,为输入r通过跟踪微分器td计算的各阶导数,i=1,…,n。
22、进一步,该方法包括以下步骤:
23、s200、初始化迭代学习自抗扰控制的工作参数;
24、s201、通过跟踪微分器td,求输入r的各阶导数,i=1,…,n;
25、s202、输入采样数据对(,);
26、s203、将步骤s202输入的采样数据对与历史数据组成实时移动数据窗rt-mdw,动态调整迭代学习ileso算法的迭代学习最大次数;
27、s204、进行一次正向ileso算法学习,并使迭代学习的次数j加一;
28、s205、进行迭代学习效果的误差判断;若满足预设的误差要求,则结束本采样周期的迭代学习,进入步骤s206;若不满足预设的误差要求,则进入步骤s208;
29、s206、输出ileso算法在本采样时刻的估计值最终状态和扩张状态;
30、s207、根据自抗扰控制器adrc的状态误差反馈器sef计算控制输出后,进入下一次采样控制,重新回到步骤s201;
31、s208、判断迭代学习次数j是否大于设定的迭代学习最大次数nc;若迭代学习的次数j大于nc,则进入步骤s206;若迭代学习的次数j不大于nc,则进入s209;
32、s209、进行一次逆向ileso算法学习,且使迭代学习次数j加一,进入s210;
33、s210、进行一次正向ileso算法学习,且使迭代学习次数j加一,重新进入s205,进一步完成迭代学习效果的误差判断。
34、进一步,在步骤s200中,所述工作参数包括跟踪微分器td、扩张状态观测器eso和状态误差反馈器sef的参数以及实时移动数据窗的长度nw和迭代学习最大次数nc。
35、进一步,所述步骤s203包括以下步骤:
36、将步骤s202输入的采样数据对(,)与历史数据(,), l=0,…, nw,组成实时移动数据窗rt-mdw,数据不足时,(,)用0代替,在区间[0, nw]对应测量数据的采样时刻为[k-nw, k],随着时间的增加,采样次数k增加,新的测量数据对(,)不断进入,在nw个采样周期之前的数据就退出,形成一个实时移动的数据窗口;此外,实时移动数据窗rt-mdw中储存迭代学习过程中的状态和扩张状态;
37、动态调整nc的大小,随着采样次数k的增加,增加nc,间接实现ileso的变增益控制,如下式(8)所示,
38、(8);
39、其中k为采样次数,ncm为两次采样间隔时间容许的迭代学习最大次数,tc表示过程时间常数,取为系统的一阶等效模型的惯性时间对应的采用周期个数;int为取整函数,min为取最小值函数,实时移动数据窗口rt-mdw的长度nw根据tc调整。
40、进一步,所述步骤s205包括以下步骤:
41、进行迭代学习效果的误差判断;若满足,则结束本采样周期的迭代学习,进入步骤s206;若不满足估计误差的绝对值,则进入步骤s208;其中,为估计误差的绝对值,为预设的正数。
42、进一步,所述步骤s206包括以下步骤:
43、输出ileso算法在本采样时刻的估计值最终状态和扩张状态,其中:
44、 (9);
45、式(9)中,k为采样次数,为ileso状态估计,为ileso扩张状态估计。
46、一种存储有指令的非暂时性计算机可读介质,当所述指令由处理器执行时,执行根据上述的迭代学习自抗扰控制方法的步骤。
47、一种计算设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的迭代学习自抗扰控制方法。
48、本发明与现有技术相比,具有如下优点与有益效果:
49、1、本发明提出了迭代学习扩张状态观测器ileso的结构和算法,在经典eso的基础上,引入迭代学习机制,把一段时间的实时采样数据组成一个在实时移动数据窗,通过沿时间轴的正向和逆向迭代学习,提高ileso的收敛速度,减少相位滞后,实现对总扰动的低延时估计;
50、2、本发明能够根据ileso对系统输出的误差动态调整迭代学习次数,达到间接地自适应调节eso带宽或者观测器增益的目的,克服未知扰动的大范围不确定性对eso性能的影响;该方法不需要高增益,降低了初始峰值现象;
51、3、ileso可以降低时域经典eso的带宽,对测量噪声具有较好的滤波作用,解决了经典eso很难同时兼顾对测量噪声的滤波性能和对总扰动的估计性能的问题;
52、4、实时移动数据窗口的长度可以根据被控系统的时间常数调整,在计算机算力容许的情况下,增加数据窗口的长度可以使得总扰动的估计更加光滑,可以减少控制系统执行器的频繁来回动作,提高其工作寿命。
- 还没有人留言评论。精彩留言会获得点赞!