自主车辆横纵向决策路径规划方法、系统、设备及介质
本发明涉及车辆驾驶决策,特别是涉及一种自主车辆横纵向决策路径规划方法、系统、设备及介质。
背景技术:
1、在安全和效率方面,无人驾驶车辆比有人驾驶车辆具有巨大优势,随着深度学习的发展,基于学习的方法,尤其是强化学习算法在自主车辆决策规划研究中得到广泛关注,然而完全依靠传统的强化学习算法无法完全保证轨迹的安全性和可行性。此外,许多强化学习算法的通行效率并不高。
2、因此,部分学者将强化学习融入传统决策规划中,在非结构化道路上基于强化学习选取局部路径点作为局部规划的指引。但是,该种方法没有考虑感知遮挡的情况,不能够适应感知不确定性的场景,例如行人探头等,在狭窄视野里很可能导致事故。
3、还有建立分层的结构,将全局任务分解为若干个局部子任务,通过实现各个子任务最终实现达到目的地,但是架构相对比较复杂,目前还缺乏传统路径规划和强化学习算法的融合。
技术实现思路
1、为了解决上述问题,本发明提出了一种自主车辆横纵向决策路径规划方法、系统、设备及介质,将横纵向决策问题解耦,利用值分布式强化学习算法来决策,提升在感知遮挡下的决策规划效果。
2、为了实现上述目的,本发明采用如下技术方案:
3、第一方面,本发明提供一种自主车辆横纵向决策路径规划方法,包括:
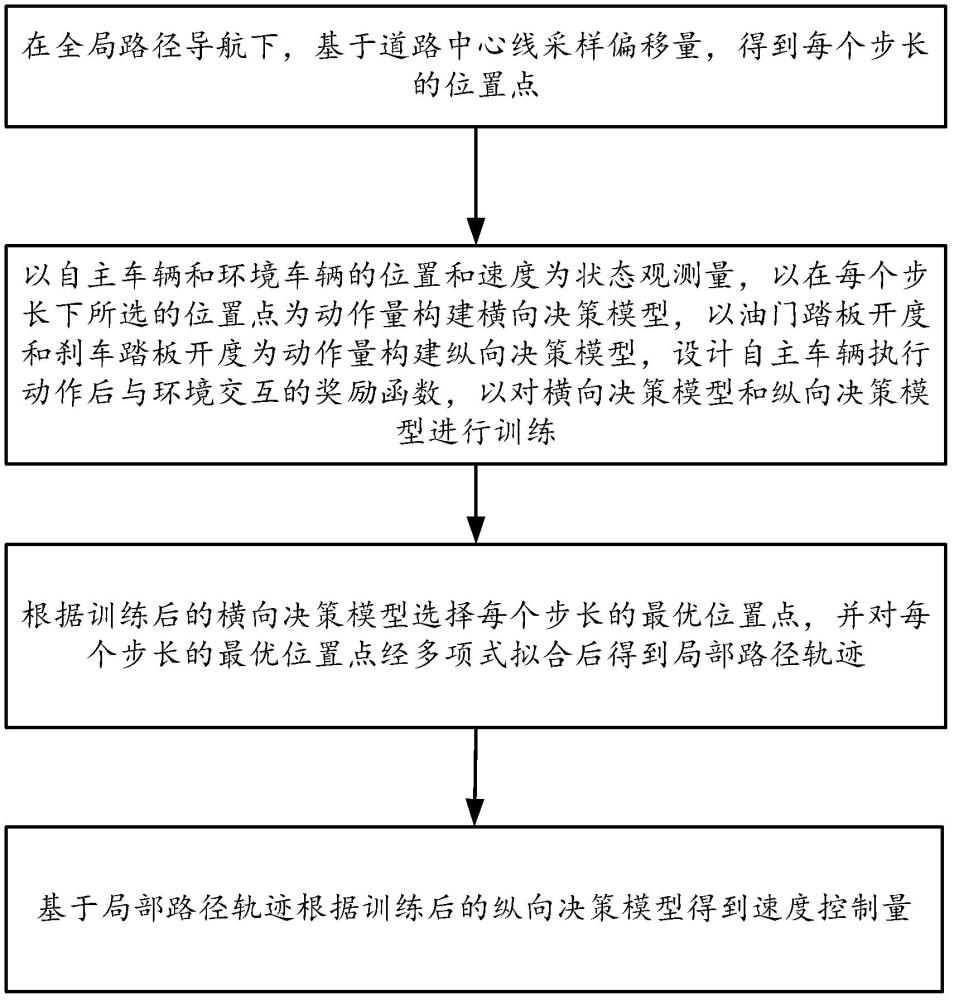
4、在全局路径导航下,基于道路中心线采样偏移量,得到每个步长的位置点;
5、以自主车辆和环境车辆的位置和速度为状态观测量,以在每个步长下所选的位置点为动作量构建横向决策模型,以油门踏板开度和刹车踏板开度为动作量构建纵向决策模型,设计自主车辆执行动作后与环境交互的奖励函数,以对横向决策模型和纵向决策模型进行训练;
6、根据训练后的横向决策模型选择每个步长的最优位置点,并对每个步长的最优位置点经多项式拟合后得到局部路径轨迹;
7、基于局部路径轨迹,根据训练后的纵向决策模型得到速度控制量。
8、作为可选择的实施方式,纵向决策模型的奖励函数包括:安全性奖励函数、效率通行奖励函数、到达目的地奖励函数和舒适奖励。
9、作为可选择的实施方式,安全性奖励函数表示如果发生碰撞时,则赋奖励值;
10、到达目的地奖励函数表示如果到达目的地和如果没有到达目的地但没有发生碰撞时,则赋奖励值;
11、效率通行奖励函数表示为根据期望车速控制车速;
12、舒适奖励表示为,其中,a是车辆加速度。
13、作为可选择的实施方式,横向决策模型的奖励函数包括:纵向决策模型的奖励函数以及参考线奖励函数和换道奖励函数。
14、作为可选择的实施方式,参考线奖励函数表示如果在参考线上时,则赋奖励值;
15、换道奖励函数表示如果存在换道,则赋奖励值。
16、作为可选择的实施方式,对横向决策模型和纵向决策模型进行训练时,采用值分布式强化学习的完全参数化的分位数函数,先训练纵向决策模型,再训练横向决策模型,之后再迭代优化,且在迭代优化时,固定某一方向策略后,学习另一个方向的策略。
17、作为可选择的实施方式,在横向决策模型和纵向决策模型中,以自主车辆和环境车辆的位置和速度为状态观测量,以此组成观测空间,观测空间包括自主车辆与环境车辆的位置差和速度差,以不同时刻的状态观测量堆叠为状态空间。
18、第二方面,本发明提供一种自主车辆横纵向决策路径规划系统,包括:
19、采样模块,被配置为在全局路径导航下,基于道路中心线采样偏移量,得到每个步长的位置点;
20、模型训练模块,被配置为以自主车辆和环境车辆的位置和速度为状态观测量,以在每个步长下所选的位置点为动作量构建横向决策模型,以油门踏板开度和刹车踏板开度为动作量构建纵向决策模型,设计自主车辆执行动作后与环境交互的奖励函数,以对横向决策模型和纵向决策模型进行训练;
21、横向决策模块,被配置为根据训练后的横向决策模型选择每个步长的最优位置点,并对每个步长的最优位置点经多项式拟合后得到局部路径轨迹;
22、纵向决策模块,被配置为基于局部路径轨迹根据训练后的纵向决策模型得到速度控制量。
23、第三方面,本发明提供一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成第一方面所述的方法。
24、第四方面,本发明提供一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成第一方面所述的方法。
25、与现有技术相比,本发明的有益效果为:
26、本发明提出了一种自主车辆横纵向决策路径规划方法,提出一种解耦的分层框架,将横纵向决策问题解耦,横向决策问题为局部路径轨迹的规划,首先在全局路径导航下基于采样方法获取每个步长的位置点,然后利用值分布式强化学习的完全参数化的分位数函数,对每个步长的位置点进行决策,选择每个步长的最优位置点,最后利用传统路径规划的多项式拟合生成局部路径轨迹;纵向决策问题是基于局部路径轨迹对速度控制量进行强化学习,利用值分布式强化学习的完全参数化的分位数函数算法来决策,且融合传统路径规划和值分布式强化学习算法,强化学习的神经网络能够拟合风险分布下的总奖励值(即q值),潜在学习到感知遮挡下的安全动作,学习不确定性环境中的风险,提升在感知遮挡下的决策规划效果。
27、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种自主车辆横纵向决策路径规划方法,其特征在于,包括:
2.如权利要求1所述的一种自主车辆横纵向决策规划方法,其特征在于,纵向决策模型的奖励函数包括:安全性奖励函数、效率通行奖励函数、到达目的地奖励函数和舒适奖励。
3.如权利要求2所述的一种自主车辆横纵向决策规划方法,其特征在于,安全性奖励函数表示如果发生碰撞时,则赋奖励值;
4.如权利要求2所述的一种自主车辆横纵向决策规划方法,其特征在于,横向决策模型的奖励函数包括:纵向决策模型的奖励函数以及参考线奖励函数和换道奖励函数。
5.如权利要求4所述的一种自主车辆横纵向决策规划方法,其特征在于,参考线奖励函数表示如果在参考线上时,则赋奖励值;
6.如权利要求1所述的一种自主车辆横纵向决策规划方法,其特征在于,对横向决策模型和纵向决策模型进行训练时,采用值分布式强化学习的完全参数化的分位数函数,先训练纵向决策模型,再训练横向决策模型,之后再迭代优化,且在迭代优化时,固定某一方向策略后,学习另一个方向的策略。
7.如权利要求1所述的一种自主车辆横纵向决策规划方法,其特征在于,在横向决策模型和纵向决策模型中,以自主车辆和环境车辆的位置和速度为状态观测量,以此组成观测空间,观测空间包括自主车辆与环境车辆的位置差和速度差,以不同时刻的状态观测量堆叠为状态空间。
8.一种自主车辆横纵向决策路径规划系统,其特征在于,包括:
9.一种电子设备,其特征在于,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成权利要求1-7任一项所述的方法。
10.一种计算机可读存储介质,其特征在于,用于存储计算机指令,所述计算机指令被处理器执行时,完成权利要求1-7任一项所述的方法。
技术总结
本发明公开一种自主车辆横纵向决策路径规划方法、系统、设备及介质,涉及车辆驾驶决策技术领域,包括:在全局路径导航下,基于道路中心线采样偏移量,得到每个步长的位置点;以自主车辆和环境车辆的位置和速度为状态观测量,以在每个步长下所选的位置点为动作量构建横向决策模型,以油门踏板开度和刹车踏板开度为动作量构建纵向决策模型,设计奖励函数,对横向决策模型和纵向决策模型进行训练;根据训练后的横向决策模型选择每个步长的最优位置点,并对每个步长的最优位置点经多项式拟合后得到局部路径轨迹;基于局部路径轨迹,根据训练后的纵向决策模型得到速度控制量,提升在感知遮挡下的决策规划效果。
技术研发人员:陈雪梅,徐书缘,朱宇臻,肖龙,薛杨武,沈晓旭,赵小萱
受保护的技术使用者:北京理工大学前沿技术研究院
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!